机器翻译中的深度学习技术:CNN,Seq2Seq,SGAN,Dual Learning
机器翻译是深度学习技术与NLP结合使用最活跃的,最充满希望的一个方向。从最初完全基于靠人编纂的规则的机器翻译方法,到后来基于统计的SMT方法,再到现在神经机器翻译NMT,机器翻译技术在过去60多年的时间里一直不断的更新,特别是在2012深度学习技术进入人们视野之后,机器翻译的准确率不断刷新,今天就主要盘点一下各类深度学习机器翻译里面的应用现状,给出一些比较有代表性的论文学习一下。
基于深度学习技术的神经翻译技术(NMT)最大的有点久在于:1、采用一种端到端(end-to-end)的结构,不在需要人为的去抽取特征;2、网络结构设计简单,不需要进行词语切分、词语对齐、句法树设计等复杂的设计工作。同时,这一方法的缺点也很明显:1、可解释性差,以seq2seq为例,很难解释和理解隐层输出,即encoder输出具体的物理意义;2、训练复杂度高,耗时耗力。深度学习训练样本量往往多大亿计,训练一个模型需要专门得GPU集群,花费几天甚至一周时间才能得出一个结果,模型的迭代更新非常慢。虽然NMT有它的不足,但总的来说还是利远远大于弊,下面就主要讲讲深度学习在机器翻译得一些具体应用:
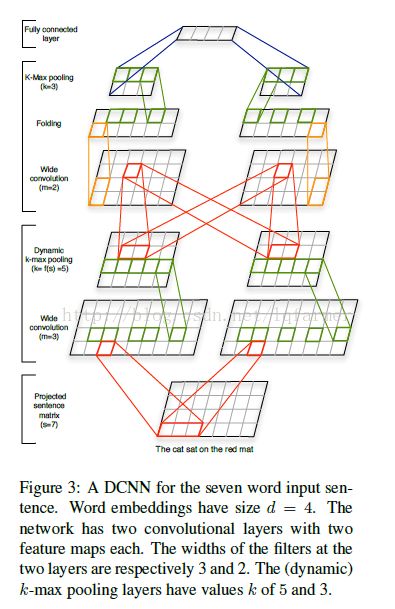
A Convolutional Neural Network for Modelling Sentences
Nal Kalchbrenner和Edward Grefenstette在2013年提出的基于“编码-解码结构”一种新的机器翻译框架,对于源语言句子,采用一个卷积神经网络把它映射成一个连续稠密的隐向量,在使用一个递归神经网络做为解码器,把这个隐向量解码成目标语言句子。这样做的有点在于可以使用RNN来处理长短不一的输入句子,尽量捕获其全部历史信息,但因为RNN存在着“梯度消失”和“梯度爆炸”的问题,没办法捕获比较长时间的依赖关系。
Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation;Kyunghyun Cho ,Dzmitry Bahdanau,Yoshua Bengio(研究组)
本文采用的任然是“解码-编码”的结构,分别采用一个RNN做为编码和解码器,第一个RNN把源语言句子映射成一个固定长度的输出隐向量,然后第二个RNN把固定的长度的隐向量解码成目标语言句子。与上一篇文章不同在于:1、本文编解码采用的都是单层的LSTM;2、提出了比LSTM结构更为简单的GRU单元,简化模型的训练。本文把深度学习输出做为一个特征,与统计机器翻译方法结合,证明“jiema-编码”架构的深度学习技术能有效提高机器翻译效果。

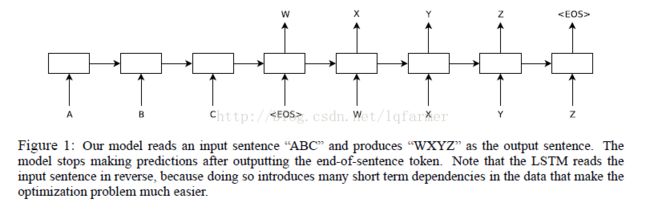
Sequence to Sequence Learning with Neural Networks;Ilya Sutskever;2014
大名鼎鼎的seq2seq模型就来源于这篇文章,Google最先采用本文描述的模型进行机器翻译并取得了很好的效果,tensorflow官方得tutorial给出了具体的实现。与前两篇文章不同:其一、本文提出了一种基于“编码-解码”架构的end-to-end的深度学习翻译模型,简单来说就是堆叠多层LSTM来进行解码,把输入源语言句子转换成一个固定长度的隐向量,在堆叠一个多层的LSTM来把隐向量解码成输出目标语言句子。多层的结构比单层结构更为灵活,可以设计出更加高效的模型;此外,类似Hierarchical的层次化结构可以抽取纬度更高、更具代表性的特征。其二、提出把源语言句子逆序输入,可以获得更好的翻译效果,因为这样可以向模型中引入更多源语言句子和目标语言句子的短依赖关系,缩短源语言句子与目标语言句子之间的距离。
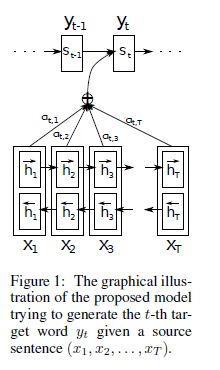
NEURAL MACHINE T RANSLATION BY J OINTLY L EARNING TO ALIGN AND T RANSLATE;Dzmitry Bahdanau,Yoshua Bengio(研究组)
本文认为通过一个encoder把源语言句子映射成一个固定长度的隐向量是提升NMT翻译效果的瓶颈,实际:解码器在解码出目标语言句子时,仅仅至于输入源句子的一部分相关,基于这种思想,提出了“attention mechanism”机制,让模型自动得找到源语言句子和目标语言句子词与词之间的重点对应关系,不限定隐向量的长度。给出了一套基于内容(content-based)注意力计算方法,本质就是用一个双向的LSTM来学习源语言句子中没个词的重要程度,这种方法非常有效,也可以用到深度学习与NLP的很多其他的领域,比如问答,句子关系推理,实体次抽取,文档生成等等。
On Using Very Large Target Vocabulary for Neural Machine Translation:
指出随着训练样本增多,基于NMT的机器翻译方法是需要维护一个非常大的词表,导致训练和解码的复杂度随着样本数正比增加的问题。提出了重要性采样的方法(importance sampling):从巨大的词表中选择一部分目标词(target vocabulary)参与训练。指出:用大的词表抽样小词表来训练小模型,然后通过组合的方式训练出模型达到跟目前模型一样的效果。
Dual Learning for Machine Translation:微软的刘铁岩团队2016年在NIPS中提出的一种新的深度学习机器翻译框架。
NMT进行训练时往往需要上千万带标注的数据,但实际上常常面临标注数据不足的情况,特别是对于小语种的翻译,为了解决NMT训练样本不足问题,本文提出了一种对偶学习的模式(dual-learning),让模型自动的从未标记的数据中去学习。翻译可以看做是一个闭环的对偶学习任务,eg:英文到中文看做一个primal阶段,英文到中文看做一个dual阶段,而primal和dual刚好形成一个闭环,dual可以产生足够反馈信息来进行自学习。采用深度强化学习结合生成对抗网络学习结合的机制来训练网络参数,用一个agent代表primal任务,另一个agent代表dual任务,相互之间通过一种强化学习机制来学习网络参数,直至模型收敛。其中的反馈信息构建:X代表输入,经过primal之后为Y;Y经过dual反馈回去X’,根据X - X’绝对值构建。

Improving Neural Machine Translation with Conditional Sequence Generative Adversarial Nets:
这是中科院自动化在上个月中放到arxiv上的一篇文章。这篇文章的突出指出在于首次使用GAN来进行机器翻译,并且使BELU比stat-of-art提升了2.
文章提出了条件化GAN神将网络翻译模型,即CSGAN-NMT模型。模型由两个对抗模型组成,其一是生成模型G,采用的是传统的attention-based 神经网络模型,把源语言句子翻译成目标语言句子。其二是判别模型D,判断句子是由机器翻译还是人翻译的,其设计有两种方法,即分别采用CNN或者RNN设计,最终发现CNN的效果比LSTM要好,因为LSTM训练时存在negative signal干扰。文章另外一个值得借鉴的是其训练策略,GAN的训练往往非常困难,本文采用了MLE来预训练生成器G,然后再用G生成的样本和真实样本来pretrain D,当D达到某一个准确率的时候,进入对抗性训练的环节,GAN的部分基本和SeqGAN一样,用policy gradient method+MC search,感兴趣的可以关注论文:SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient。

更多深度学习在NLP方面应用的经典论文、实践经验和最新消息,欢迎关注微信公众号“DeepLearning_NLP” 或扫描二维码添加关注。
