纯干货-17 分布式深度学习原理、算法详细介绍
介绍
无监督的特征学习和深度学习已经证明,通过海量的数据来训练大型的模型可以大大提高模型的性能。但是,考虑需要训练的深度网络模型有数百万甚至数十亿个参数需要训练,这其实是一个非常复杂的问题。我们可以很快完成复杂模型的训练,而不用等待几天甚至几个星期的时间呢?Dean等人提出了一个可行的训练方式,使我们能够在多台物理机器上训练和serving一个模型。作者提出了两种新的方法来完成这个任务,即模型并行和数据并行。在下面的博客文章中,我们将简单地提到模型并行,因为我们主要关注数据并行的方法。
注:文章由“深度学习与NLP”编译,原文地址:http://joerihermans.com/ramblings/distributed-deep-learning-part-1-an-introduction/
模型并行(Model Parallelism)
在模型并行中,单个的模型分布在多个机器上。将深度神经网络放在多台机器上并行训练所能获得的性能提升效果主要取决于模型的结构。具有大量参数的模型通常可以获得更多CPU内核和内存,因此,并行化大型模型会显著提高性能,从而缩短训练时间。
先举一个简单的例子,以便更清楚地说明这个概念。假设有一个感知器,如图1所示。为了更有效地并行化,我们可以将神经网络看作一个依赖图(Dependency Graph),其目标是尽量减少同步机制的数量,假设我们拥有无限的资源。此外,只有当一个节点具有多个变量依赖时,才需要同步机制。变量依赖(variable dependency)是可以随时间变化的依赖。例如,偏差(bias)是一个静态的依赖,因为随着时间的推移,偏差的值保持不变。在图1所示感知器中,并行化非常简单。涉及多个输入X(x1,x2,x3...)的计算可以并行化执行。

图1:使用模型并行化对感知器进行切分。在这种方法中,每个输入节点负责接受输入Xi,并且与相关的权值Wi相乘。乘完之后,结果被送到输出结果累加求和,得到输出。当然,输出结点需要一个同步机制来确保结果时间是一致的。同步机制通过等待计算y所依赖的结果来实现。
数据并行(Data Parallelism)
数据并行性是另外一种完全不同的参数优化方法。数据并行化减少训练时间的一般思路是,采用n个workers同时并行计算n个不同的数据块(partitions,分区),来优化一个central model的参数。在这种情况下,把n个模型副本放在n个处理节点上,即每个节点(或进程)都拥有一个模型的副本。然后,每个worker使用指定的数据块来训练一个局部的模型副本。但是,可以让所有的workers同时一致工作,优化同一个目标。有几种方法来实现这一目标,在后面的章节中详细的讨论这些方法。
尽管如此,达到这一目标的一个常见的方法是采用一个集中的参数服务器。参数服务器的目标是负责收集来自于各个worker的参数更新(updates),以及处理来自各个worker的参数请求(request)。分布式学习过程首先将数据集分割成n个块(shards)。每个单独的块将被分配给一个特定的worker。接下来,每个worker从其shards中采样mini-batches的数据用于训练一个local model。在一个(或多个)mini-batches之后,每个worker将与参数服务器通信,发送变量更新请求。这个更新请求一般都是梯度∇fi(x)。最后,参数服务器将所有这些参数更新的梯度收集起来,求平均(更新),并把更新之后的值发送到每个worker。图2展示上述过程。

图2:数据并行方法的示意图。在这种方法,采用n个worker(不一定在不同的机器上),并将数据集的数据块(分区)分配给每个worker。使用这个数据块,每个worker i将遍历一个的mini-batch的数据,生成梯度∇fi(x)。然后,将梯度∇fi(x)被发送给服务器参数,参数服务器PS将梯度收集起来,按照特定的更新方式(update mechanism)进行更新。
并行化方法介绍
在本节中,我们讨论几种并行的梯度下降(Gradient Descent,GD)的方法。这不是一个直观的任务,因为梯度下降是一个固有的顺序算法,其中,每个数据点(实例)提供了一个趋近极小值的方向。但是,使用大量的数据集训练具有大量参数的模型将会导致训练时间过长。如果想减少训练时间,最好的选择就是购买更好的,或更确切地说是更合适的硬件(例如GPU)。但是,这并不总是可行的。出于这个原因,有几种方式可以通过梯度并行化来实现。在下面的小节中,我们将介绍一些比较常用的并行梯度下降的方法,讲解这些方法的底层原理,以及如何使用它们。
同步数据并行化方法
数据并行性有两种不同的方式。就个人而言,最直接的概念是同步数据并行性。在同步数据并行中,如图3所示,所有worker根据相同的central variable(center variable)计算其梯度。这就意味着,每当一个worker完成当前batch的梯度计算时,它就会提交参数(即,模型的梯度或参数)到参数服务器。但是,在将这些信息纳入central variable之前,参数服务器将存储所有信息,直到所有worker都完成模型计算,提交参数梯度。之后,参数服务器将应用特定的更新机制(取决于算法),将提交的梯度合并到参数服务器中。从本质上讲,可以看到同步数据并行化适用于小批量并行计算。
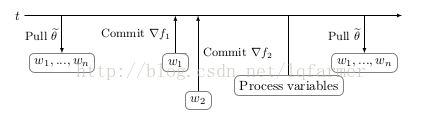
图3:在同步数据并行环境下,n个worker并行计算(不一定在不同的机器上)。在训练过程开始时,每个worker都会获取最新的central variable。接下来,每个worker都将开始他们自己本地的训练。在本地完成梯度计算之后,worker将所计算的得到的更新信息(梯度或参数化,取决于算法)提交给参数服务器。但是,由于系统存在很多未知因素,一些worker可能会严重的延迟,从而导致其他worker处于无任务等待状态,同时仍占用相当的内存资源,这会导致模型训练时间变长。
但是,由于worker存在为建模的系统行为(不确定因素),worker可能拖延一定时间之后,在提交本地的参数更新。这主要取决于系统负载均衡情况,这个延迟可能相当重要。因此,这种数据并行方法印证了一个古老的说法:“只有当集群中最弱的worker也非常高效时,一个同步数据并行方法才能非常高效”。
模型平均
实际上,这是一中在介绍中提到过的数据并行方法。但是,与更传统的数据并行方法相反,这一方法没有采用参数服务器。在模型平均中,每个worker在训练开始时都会得到一个模型的副本。然而,如图4所示,可以对每个worker采用不同的权重初始化技术,使得模型在初始的几个Iterations中具有不同的参数,来覆盖更多的参数空间。尽管如此,但不建议这样做,因为这会给每个worker带来非常不同的结果。因此,每个worker需要耗费更多的时间迭代收敛到所有worker都“Agree”的“good solution”。但是,这个问题与这里讨论的大多数分布式优化算法有关,将在下面的内容中更详细地讨论。
在每个worker都使用模型的副本初始化之后,所有的worker都开始相互独立地训练过程。这意味着在训练过程中,worker之间不会有任何沟通。因此,消除了参数服务器方法中存在的通信开销问题。在一个epoch结束之后,即一个完整的数据集的迭代,这些模型将在一个worker上进行参数的汇总和平均。由此产生的平均模型将被分配给所有的worker,训练过程重复,直到平均模型收敛。

图4:在这个场景中,我们有4个独立的worker,每个worker都有一个随机初始化的模型。为了简化情况,假设我们可以直接从损失函数E(θ)中获得梯度。在模型平均中,每个worker只在自己本地的local模型中应用梯度下降,而不与其他worker通信。在一个epoch结束之后,如中间的图所示,对这些模型进行平均以产生一个central model。在下一个epoch,central model将被用作所有worker的初始模型。
EASGD
EASGD,或弹性平均SGD。EASGD是一种分布式优化方案,旨在减少与参数服务器的通信开销。这与DOWNPOUR等异步的方法形成对比,大多数情况下需要一个小的communication window才能正常收敛。小communication window带来的问题是需要停止训练过程,以便使模型梯度跟新与参数服务器同步,因此也限制了训练过程的吞吐量。当然,模型中的参数数量也是一个重要的因素。例如,可以想象,假设每5个batch计算完之后,与参数服务器的同步,一个具有100 MB值的参数的模型可能会严重影响训练性能。此外,由于分布式性质,每个worker对附近参数空间的探索实际上提高了模型在连续梯度下降方面的统计性能。但是,目前我们没有任何证据支持这个说法,也不否认。我们所观察到的是,单个epoch之后,模型的统计性能通常(显著)小于采用Adam(顺序训练)和ADAG(分布式训练)的训练的模型。但是,如果我们让EASGD达到与Adam后ADAG相同的训练时间,那么我们仍然可以得到相同或稍差的模型性能。所以有证据表明,至少在EASGD的情况下,这种说法并不完全正确。但是,这需要更多的调查研究。
EASGD通过在worker的参数和central variable之间施加“弹性力, elastic force”来解决通信的带宽限制。此外,由于与参数服务器的通信的弹性变化和减少,允许每个worker充分探索其周围的参数空间。如上所述,更多的探索可以有利于提升模型的统计性能。但是,我们认为,如模型平均一样,只有当worker处于central variable的附近时,这种方法才会有用,我们将在实验部分来证明这一点。然而,与模型平均相比,worker并不与central variable同步。这引出了一个问题,EASGD如何确保worker仍然处于central variable的附近呢?因为在模型平均中,太大的参数空间探索实际上恶化了central variable的性能,并且可能会阻止收敛,因为从本质上讲,worker之间其实覆盖了不同的参数空间,如图4所示。但是,如果弹性参数值过大,exploration根本不会发生。

为了充分理解EASGD方程的含义,如方程1和方程2所示,我们将引入图5来详细地说明,图5揭示了弹性力(elastic force)的本质。有两个向量,梯度∇f和弹性差ηρ(θti - θtc),其中η是学习率和ρ是弹性参数。当弹性参数ρ很小时,模型可以进一步探索参数空间。这可以从图5中观察到。当矢量ρ较小时,弹性差ηρ(θti - θtc)也比较小(除非worker和central variable之间的距离非常大)。因此,central variable和worker之间的吸引很小,因此可以更广泛地探索参数空间。

图5:worker变量w正在探索参数空间以进行优化C。然而,探索的程度与弹性系数ρ和差分值(θti - θtc)成正比。一般来说,当ρ很小,模型可以进行更多的探索。需要指出的是,在模型平均中,太多的探索实际上会使模型的统计性能恶化(如图4的第一个子图所示),因为worker们达不到一个统一合适的模型参数。特别是当考虑到central variable是使用worker的变量的平均值进行更新的时候,如公式2所示。
现在,从方程1和上面的说明,我们可以设想,一些worker在communication window内进行第i步的参数更新,累积的梯度是大于或等于所述弹性力。因此,这阻止了worker的进一步探索参数空间(如预期的那样)。然而,一个明显的副作用是,下面所示的梯度计算显然被浪费了,因为它们被elastic difference所抵消了,如图5所示。如公式3所示。

解决公式3所描述的计算浪费问题最直接的方式就是,简化每一个mini-batch计算之后的条件检查。当这个条件满足时,使用∑i−η∇f(xt+i; θt+i)与参数服务器通信。这样不会浪费任何计算,而且,也将方式超参数的限制,因为communication window现在由超参数ρ控制(间接)。实质上,ADAG的核心思想(本文后面会提到)也可以应用到这个方案中,以进一步提高梯度更新的质量,并使优化方案对其他超参数不那么敏感,例如,并行worker的数量。
异步数据并行方法
为了克服在同步数据并行中,由负载的worker引起的严重延迟问题,从而进一步减少训练时间,简单的方法就是去除同步约束限制。但是,这又带来了其他一些影响,其中一些影响不是很明显。概念上最简单的是参数过时(Parameter staleness)。Parameter staleness是指当一个worker从central variable获取参数(pull)之后,再到下次提交参数到central variable之间的延迟的时间。直观地说,这意味着worker正在使用基于该模型的先前参数的梯度来更新模型参数。如图6所示。w1在t1时刻,从central variable获取参数到本地进行计算,当本地计算完成之后,在t2时刻把梯度提交到central variable进行参数更新,这之间t2 - t1的时间差称为w1的Parameter staleness。因为t1到t2之间,w2进行了一次梯度更新提交,所以t2时刻,w1的参数更新是有延迟的,这样是不合理的。

图6:在异步数据并行模式中,由于在同步数据并行中删除了同步机制,训练时间进一步减少(平均)。但是,这引起了一些效应,比如Parameter staleness和由异步引起的动量。
注意:除非您确实需要,否则不需要阅读以下段落。但是,拓展一下:增加并行worker数量的行为就像增加更多的动力一样。
另一个不那么直观的副作用是由异步引起的动量。粗略地说,这意味着在问题中增加更多的worker也会为优化过程增加更多的隐动量(implicit momentum)。这种隐动量是由异步所需要的排队模型所带来的结果。请注意,一些方法,如Hogwild!不需要同步锁机制,因为他们假定稀疏梯度更新。但是,分布式SGD也适用于密集梯度的更新。我们也证实了作者的观点,即在使用不过时和不同步的算法时,增加更多的异步worker实际上会降低模型的统计性能。此外,异步算法的行为模式大致由方程4描述。这意味着异步产生的隐动量是(1 - 1/n)。
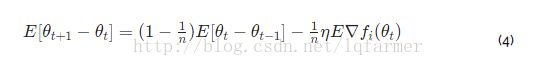
但这不是整个事情的全貌。队列模型,或一般来说,异步worker数量的增加会降低模型的统计性能(我们在实验中也观察到这一点)。但是,想说的是,这一效果与动量类似,但不一定被定义为(ADAG,我们没有观察到这种效果,至少在30个并行的过程中)。我们将在以下博客文章中更深入地讨论这个话题。
异步EASGD
异步EASGD的更新方案与同步EASGD非常相似,但是也有一些重要的细节。在下面的段落中,我们将用向量-ηρ(θti - θtc)表示弹性差(elastic difference),从而遵循原始论文中表示方式。请记住,在同步版本中,该向量实际上用于实现对参数空间的探索的策略。这意味着,在方程式1中,这个向量的任务是不让worker远离central variable。这正是,当将elastic difference应用于worker时发生的情况,如图5所示。
在异步版本中,elastic difference具有相同的功能。但是,它也将被用来更新central variable。如上段所述,elastic difference实际上用于参数空间的限制性探索。但是,如果我们否定elastic difference,那就是+ ηρ(θti - θtc),则elastic difference可以被用来优化所述central variable(图5中的反向箭头),同时任然保持通信限制(communication constraint),这这是EASGD正在努力解决的问题。
DOWNPOUR
在DOWNPOUR中,每当worker计算一个梯度(或梯度序列)时,梯度就与参数服务器通信。当参数服务器从worker那里接收到梯度更新请求时,它将把更新合并到central variable中,如图7所示。与EASGD相反,DOWNPOUR并不假设存在任何通信限制。更重要的是,如果与参数服务器的频繁通讯不发生(为了减少worker差异),DOWNPOUR将不会收敛(这也与由异步引起的动量问题有关,见图8)。这正与上面讨论的问题相同。如果我们允许worker探索“太多”的参数空间,那么所有的worker就不会一起努力去为central variable找到一个好的解决方案。此外,DOWNPOUR没有任何固有的机制来保持central variable的邻域。因此,如果增加通讯窗口(communication window)大小,则会成比例地增加发送到参数服务器的梯度的长度。因此,为了使参数空间中worker的方差更“小”,就需要更加积极地更新central variable。
图7:具有相同学习率的20个平行的worker(蓝色)的DOWNPOUR的动画,试图去优化与常规顺序梯度下降法(绿色)相比的单个目标(central variable,红色)。如上所述,从这个动画中我们可以观察到,有并行的worker之间的异步特性引起的动量,正如我们上面所讨论的。
图8:具有40个并行worker的DOWNPOUR的动画。在这种情况下,由worker数量产生的隐含动量会导致算法发散。
ADAG
我们注意到,一个大的communication window与模型性能的下降有关。使用一些模拟(如DOWNPOUR,如上所示),我们注意到,当使用communication window标准化累积梯度时,可以减轻这种影响。还有几个积极的影响,例如,对于并行worker的数量,并没有进行标准化(normalizing),因此,也不会失去并行化梯度下降(收敛速度)带来的好处。这有一个副作用,即每个worker就central variable产生的方差同样也会保持较小,因此,对central objective有积极作用!此外,由于规范化,模型对超参数也不太敏感,特别是communication window大小。然而,也就是说,大的communication window通常也会降低模型的性能,因为可以让worker基于数据分片(data shard)中的样本,探索更多的参数空间。在第一个原型中,我们调整了DOWNPOUR来适应这个想法。我们观察到以下结果。首先,我们观察到模型性能的显着提高,甚至与诸如Adam的顺序优化算法可比。其次,与DOWNPOUR相比,我们可以以3倍大小增加communication window。因此,可以更有效地利用CPU资源,并且进一步减少总的训练时间。最后,归一化积累的梯度允许我们增大communication window。因此,我们能够匹配EASGD的训练时间,并且达到大致相同(有时更好,有时更差)的结果。

总之,ADAG或异步分布式自适应梯度算法的核心思想,可以应用于任何分布式优化的方案。使用我们的观察和直觉(特别是关于由异步引起的隐动量),我们可以猜测,归一化累积梯度的思想可以应用于任何分布式优化方案。
总结
在这项工作中,我们向读者介绍了分布式深度学习相关的问题,以及在实际应用时需要考虑的一些问题,比如隐动量。我们还提出了一些能够显着改善现有分布式方案的技术。
往期精品内容推荐
老铁,邀请你来免费学习人工智能!!!
完美后空翻_波士顿动力发布2017年最新Atalas机器人
深度学习中如何选择一款合适的GPU卡的一些经验和建议分享
斯坦福大学-2017年-秋-最新深度学习基本理论课程分享
国立台湾大学-李宏毅-2017年(秋)最新深度学习与机器学习应用及其深入和结构化研究课程分享
麻省理工学院-2017年-深度学习与自动驾驶视频课程分享
深度学习的发展历史及应用现状
<深度学习优化策略-3> 深度学习网络加速器Weight Normalization_WN
<深度学习优化策略-4> 基于Gate Mechanism的激活单元GTU、GLU
模型汇总23 - 卷积神经网络中不同类型的卷积方式介绍
模型汇总-12 深度学习中的表示学习_Representation Learning
深度学习模型-13 迁移学习(Transfer Learning)技术概述
<纯干货-5>Deep Reinforcement Learning深度强化学习_论文大集合
<模型汇总-10> Variational AutoEncoder_变分自动编码器原理解析
更多深度学习在NLP方面应用的经典论文、实践经验和最新消息,欢迎关注微信公众号“深度学习与NLP”或“DeepLearning_NLP”或扫描二维码添加关注。
