终身规划A*算法(LPA*):Lifelong Planning A*
终身规划A*算法(LPA*):Lifelong Planning A*
- 1.描述
- 2.父代节点与子代节点
- 3.起始距离估计
- 4.优先队列
- 5.节点状态及扩展
- 6.初始化运行
- 7.最短路径搜索
- 8.伪代码
- 9.性质
- 10.符号表示
- 11.算法示例推演
- 12.总结
- 13.对公式的进一步理解
- 伪代码
- 参考资料
- 搜索算法其他文章
LPA_start或life Planning A_star是一种基于A*的增量启发式搜索算法。2001年,斯文·柯尼格(Sven Koenig)和马克西姆·利卡切夫(Maxim Likhachev)首次提出。
1.描述
LPA_star是A_star的增量版本,它可以适应图形中的变化而无需重新计算整个图形,方法是在当前搜索期间更新前一次搜索的g值(从开始起的距离),以便在必要时进行更正。与A_star一样,LPA*使用启发式算法,该启发性来源于从给定节点到目标路径代价的更低边界。如果保证是非负的(零可以接受)并且从不大于到目标的最低路径的代价,则允许该启发式。
启发式搜索和增量式搜索的区别在于,启发式搜索是利用启发函数来对搜索进行指导,从而实现高效的搜索,启发式搜索是一种“智能”搜索,典型的算法例如A_star算法、遗传算法等。增量搜索是对以前的搜索结果信息进行再利用来实现高效搜索,大大减少搜索范围和时间,典型的例如LPA_star、D_star Lite算法等。
2.父代节点与子代节点
除了开始节点和目标节点外,每个节点n都有上一代和下一代节点:
- 任何一条边指向n的节点都是n的前一代;
- 从n引出一条边的任何节点都是n的后继节点。
在下面的描述中,这两个术语仅指直接的父代(上一代)和子代(下一代),不指父代的父代或子代的子代。
3.起始距离估计
LPA_star对每个节点的起始距离g_star(n)保持两个估计值:
- g(n)为之前计算的g值(起始距离),如在A*中的含义;
- rhs(n),一个基于节点父代(上一代)的g值的预测值(所有g(n’)+d(n’,n)的最小值,其中n’是n的父代,d(x,y)是连接x和y的边的代价)。
对于开始节点,以下始终为真:
r h s ( s t a r t ) = g ( s t a r t ) = 0 rhs(start)=g(start)=0 rhs(start)=g(start)=0
如果rhs(n)等于g(n),则称n局部一致的。如果所有节点都是局部一致的,那么最短路径可以用A*来确定。但是,当边缘代价发生变化时,只需要对与路由相关的节点重新建立局部一致。
4.优先队列
当一个节点在局部变得不一致时(因为它的父代节点的代价或将它链接到父代节点的边缘发生了变化),它将被放在一个优先级队列中进行重新评估。
LPA*使用二维key:
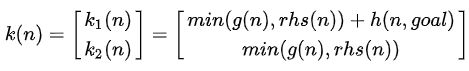
元素由 k 1 k_1 k1(它直接对应于A*中使用的f值)排序,然后由 k 2 k_2 k2排序。
根据更小的k(n)的值搜寻更优的路径节点,当一个节点n比另一个节点n’更优时,n节点的k(n)不大于k(n’),即:
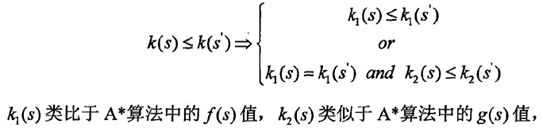
5.节点状态及扩展
队列顶部节点展开如下:
- 局部一致(Locally Consistent):g(s)=rhs(s)。当所有节点均为局部一致状态时,g(s)的值等于s到起始点的最短距离(注意,反向不成立)。这个概念很重要,当上述条件满足时,可以找到任意一点u到起始点的最短路径,假设当前位置为s,父辈节点s’(向着起始点前进的下一个节点)通过最小化(g(s’)+c(s,s’))来获得,不断重复直到到达sStart。然而,LPA*并不需要使所有节点均为局部一致状态,它通过启发式搜索将关注点放在搜索上,并且只更新那些与计算最短路径相关的节点的g值。
- 局部过一致(Locally Overconsistent):g(s)>rhs(s)。当优先队列U中取出的节点为局部过一致状态时,意味着g(s)可以通过父辈节点使自己到起点的路径更短,此时将设置g(s)=rhs(s),节点状态变为局部一致状态。
- 局部欠一致(Locally Underconsistent):g(s)
由于更改节点的g值也可能更改其后续节点的rhs值(从而更改它们的局部一致),因此将对它们进行评估,并在必要时更新它们的队列成员和key。
节点将继续扩展到下一个节点,直到满足以下两个条件:
- 目标是局部一致的
- 优先级队列顶部的节点有一个大于或等于目标的key。
6.初始化运行
当边的代价发生变化时,LPA*检查受变化影响的所有节点,即其中一条变化边终止的所有节点(如果一条边可以在两个方向上遍历,且变化影响两个方向,则检查由该边连接的两个节点):
- 更新节点的rhs值。
- 已成为局部一致的节点将从队列中删除。
- 已成为局部不一致的节点将添加到队列中。
- 保持局部不一致的节点的key已更新。
之后,节点继续扩展,直到达到结束条件。
7.最短路径搜索
节点展开完成后(即满足退出条件),计算最短路径。如果目标的代价为无穷大,那么从开始到目标没有有限的代价路径。否则,最短路径可以通过向后移动来确定:
- 从目标开始。
- 移动到当前节点n的父代n’,其中g(n’)+d(n’,n)最低(如果最低分数由多个节点共享,则每个节点都是有效的解决方案,其中任何一个都可以任意选择)。
- 重复上一步,直到开始。
8.伪代码
该代码假定一个优先队列queue,该队列支持以下操作:
- topKey()返回队列中任何节点的(数字上的)最低优先级(如果队列为空,则返回无穷大);
- pop()从队列中删除优先级最低的节点并返回它;
- insert(node, priority) 将具有给定优先级的节点插入队列;
- remove(node) 从队列中移除一个节点;
- contains(node) 如果队列包含指定节点,则返回true;如果不包含指定节点,则返回false;

void main() {
initialize();
while (true) {
computeShortestPath();
while (!hasCostChanges())
sleep;
for (edge : getChangedEdges()) {
edge.setCost(getNewCost(edge));
updateNode(edge.endNode);
}
}
}
void initialize() {
queue = new PriorityQueue();
for (node : getAllNodes()) {
node.g = INFINITY;
node.rhs = INFINITY;
}
start.rhs = 0;
queue.insert(start, calculateKey(start));
}
/** 优先级队列中扩展节点. */
void computeShortestPath() {
while ((queue.getTopKey() < calculateKey(goal)) || (goal.rhs != goal.g)) {
node = queue.pop();
if ((node.g > node.rhs) {
node.g = node.rhs;
for (successor : node.getSuccessors())
updateNode(successor);
} else {
node.g = INFINITY;
updateNode(node);
for (successor : node.getSuccessors())
updateNode(successor);
}
}
}
/** 重新计算节点的rhs并将其从队列中删除。.
* 如果节点在局部变得不一致,则使用其新key(re-)将节点插入队列。. */
void updateNode(node) {
if (node != start) {
node.rhs = INFINITY;
for (predecessor: node.getPredecessors())
node.rhs = min(node.rhs, predecessor.g + predecessor.getCostTo(node));
if (queue.contains(node))
queue.remove(node);
if (node.g != node.rhs)
queue.insert(node, calculateKey(node));
}
}
int[] calculateKey(node) {
return {min(node.g, node.rhs) + node.getHeuristic(goal), min(node.g, node.rhs)};
}
9.性质
由于算法上类似于A*, LPA*具有许多相同的属性。
- 对于LPA的每次运行,每个节点最多展开(访问)两次。每个LPA运行最多扩展一次局部过一致节点,因此其初始运行(每个节点进入过一致状态)的性能与A*类似,都是最多访问每个节点一次。
- 每次运行时展开的节点key都是单调的不随时间递减的,就像A*的情况一样。
- 启发式信息越丰富(因而越大)(同时仍然满足可接受性标准),需要扩展的节点就越少。
- 优先级队列实现对性能有重大影响,如在A*中。与效率较低的实现相比,使用斐波那契堆可以显著提高性能。
对于一个A_star实现,它打破了两个具有相等f值的节点之间的联系,而支持具有较小g值的节点(在A*中没有定义),下面的陈述也是正确的:
- 扩展局部过一致节点的顺序与A*相同。
- 在所有局部过一致的节点中,只有那些代价不超过目标的节点需要扩展,就像A*中的情况一样。
LPA_star还具有以下特性: - 当边的代价发生变化时,LPA的性能优于A(假设后者是从头开始运行的),因为只需要再次扩展一部分节点。
下文将结合Lifelong Planning A*论文的一个例子简要介绍LPA_star算法的主要过程。
10.符号表示
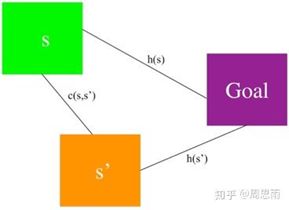
S:地形图中的路径节点的集合,s属于S
succ(s):successors,节点s的后续节点(子代节点)集合,例如节点1,2,3…i按顺序均已被搜索过,那么除了1~i的其它结点均属于succ(i)。
pred(s):predecessors,类比上述,节点s的前代节点(父代节点),与succ(s)的意义刚好相反。
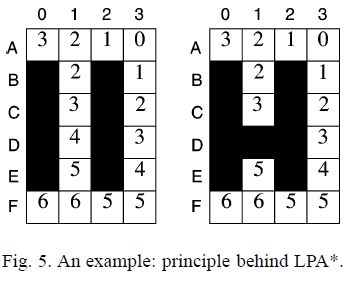
c(s,s’):两节点之间的代价函数,0 g * (s):节点s到起始点SStart的实际最短距离。 g(s):节点s到起始点的预计最短距离,而g*(s)值是实际的最短距离,这个值是一个预计值,是随着算法求解进程不断变动的,当所有节点的g(s)=rhs(s)时,g(s)的值就是到起始点的实际最短距离,即g(s)=g*(s)。 rhs(s):right hand sides,来自DynamicSWSF-FP算法。rhs值是基于g值的一步前瞻值,因此可能比g值更好地信息反馈。对于s的所有邻接节点,求它们到s的距离加上邻接节点自身的g值,其中最小的那个值作为s的rhs值。具体求法可以见下面的公式: 举个例子,图5中左侧网格世界给出的g值。方格A0的rhs值为3,即方格A1+1的gvalue和方格B1+1的g值的最小值。因此,方格A0的g值等于它的rhs值,即为局部一致。这个概念很重要,因为如果所有单元格都是局部一致的,那么所有的g值都等于各自的起始距离。 U:同A_star算法中的优先队列,依据每个节点的Key值进行排序。 当rhs(s) h(s):同A*中的类似,到目标点的估计距离,在论文中用的是到目标节点的绝对距离进行表示。 论文中以二维平面网格地图作为演示对象,每一个网格与周围八个网格相连(相互之间可以直接到达),黑色网格为障碍。 第一次搜索:地形发生变动之前的路径搜索,与A_star搜索基本相同。起点为右上角的点,目标点为左下角的点。第一张图描述了各点的到起始点的最短距离以及各点到目标点的h值。左侧为g_star值(由当前位置到起始点的代价,距离采用曼哈顿计算公式),右侧为h值(由当前位置到目标点的代价)。最开始所有点rhs和g均设为无穷,然后由起始点开始,将起始点的rhs设置为0,然后如上图过程不断迭代,直到获得最短路径。 在第一次迭代时rhs(s)=g(s),K1大致等同于A_star里的f(s),K2大致等同于A_star里的g(s)。此时按照A_star算法进行搜索,搜索的过程是按照key[K1;K2]的优先级进行搜索的。 第二次搜索:当场景中地形状态发生变动,在该例子中,节点(D,1)变为障碍,只改变了三个起始距离,即单元D1、E1和F0。这允许LPA*有效地重新规划最短路径,即使从开始单元到目标单元的最短路径完全改变。 这是重用以前的规划构建过程的一部分(以g值的形式),而不是以更大的内存需求为代价来调整先前规划的优点。特别是,g值不仅可以用来确定最短路径,而且它们比最短路径本身更容易再次使用。 首先对该节点进行更新,并将其后代节点置于优先队列中,该节点的变动对父辈节点的状态并无影响。同第一次搜索类似,不断进行迭代直到再次找到到目标位置的最短路径。 在迭代中,第二次到第三次之间为父辈的某一节点突然变为障碍的情况下,造成父辈节点到起点的路径变大。此时,g(s) LPA_star提出了一种解决动态环境下的最短路径搜索方法,但是它针对的是起始点和目标点固定的情况,如果在机器人按照搜索到的最短路径行走过程中,环境中某些节点发生变化,这时如果想获得新的路径,就得以机器人当前节点为起始点,重新用LPA_star算法解算一次,这效率是很低的。针对这种情况,该论文的作者随后提出了D_starLite算法来作为处理动态环境最短路径问题的高效方法。 来源于路径规划——Lifelong Planning A*算法 和A_star算法一样,LPA_star算法采用非负、一致性的启发函数 h(s) 表示当前位置网格点 s 到目标点 Goal 的距离的估计, h(s) 一致性体现在服从以下三角不等式,可以由简单的三角形几何性质可以推出: 其中 s≠Goal 且 s属于succ(s),如图1所示: succ(s)或 children(s) ,表示网格点 s 下一时刻将要移动到的点,相当于 s 点的继承点,对于 Goal 点,有 s u c c ( G o a l ) = ⊘ succ(Goal)=\oslash succ(Goal)=⊘ pred(s) 或 parent(s) ,表示前一时刻移动到当前位置 s 点来的网格点,相当于 s 点的前辈点,对于 Start 点,有 KaTeX parse error: Can't use function '\(' in math mode at position 5: pred\̲(̲Start)=\oslash; g*(s) ,表示 Start 点到当前 s 点的最短路径距离, g(s) 是对g*(s) 值的估计, g ∗ ( s ) g^*(s) g∗(s) 定义如下: 其中 g(s’) 是节点 s’ 到起始节点 s_{start} 的代价,类似于A*算法中的 g(n) , c(s’,s) 表示从节点 s’ 到节点 s 的代价,被称为边缘代价函数。 在图2的a)中, 此时属于“正常情况”,即 g(s)=rhs(s) ,此时 s 点为局部一致(locally consistent); 在图2的b)中,如果边缘代价函数值 c(s’,s) 由于环境发生改变从 B 变为 ∞ (即自由网格点 s 被障碍物占据),则有 这种情况有 ,此时 s 点为局部不一致(locally inconsistent)。 局部不一致又分为过一致(Overconsistent)和欠一致(Subconsistent)。 当 g(s)>rhs(s) 被称为局部过一致,即 s’ 点到 s 点的边缘代价函数 c(s,s’) 值变低,代表网格上障碍物被清除(例如c值从 ∞ 变为 B )或搜索到一条更短的“捷径”。 当 g(s) Openlist或priority queue,和A*算法一样,表示被搜索网格点的集合,用 key(s) 来对这些网格点进行排序,值得注意的是所有Openlist的点都局部不一致,所有局部不一致的点都在列表上。 key(s),代表着优先级队列中网格点选择的优先权,key值用于处理局部不一致的网格点, key(s) 由两个元素组成, key(s) 被定义为: key值之间的比较方式如下: key值越小,其优先权越高,该点就越先被搜索。 [1] Wiki百科:Lifelong Planning A* Field Dstar路径规划算法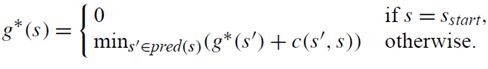
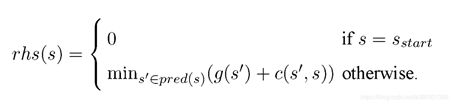
Key[K1,K2]:优先队列排序依据的键值,包含两部分,K1与K2,优先比较K1,若相同则比较K2进行排序。在rhs(s)=g(s)的情况下,K1大致等同于A_star里的f(s),K2大致等同于A*里的g(s),K1与K2的计算方法见下面的图。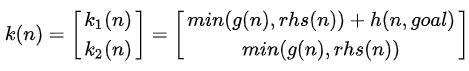
11.算法示例推演
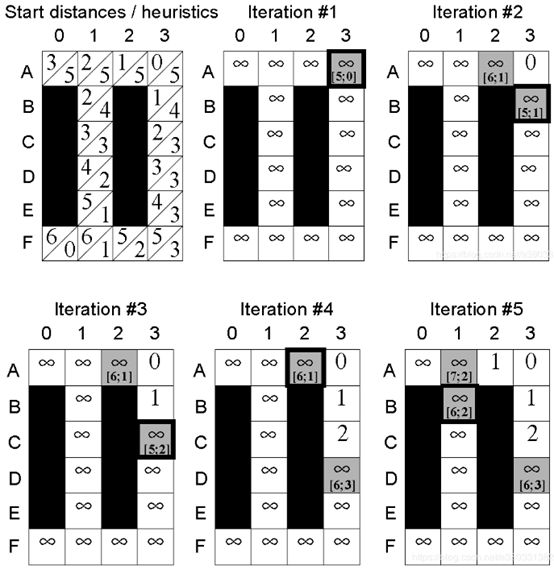
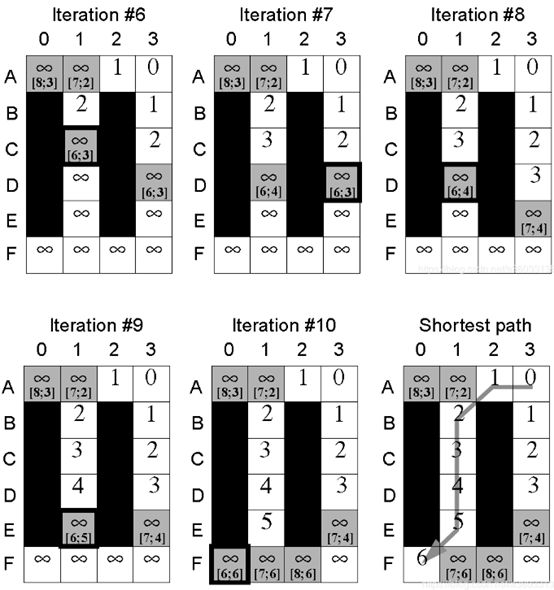


12.总结
13.对公式的进一步理解
![]()
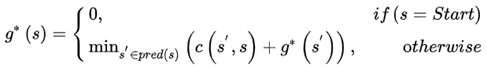
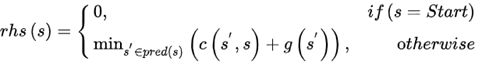
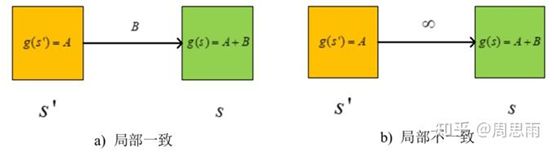
g ( s ) = A + B g(s)=A+B g(s)=A+B
r h s ( s ) = g ( s ′ ) + c ( s ′ , s ) = A + B rhs(s)=g(s')+c(s',s)=A+B rhs(s)=g(s′)+c(s′,s)=A+B
g ( s ) = A + B g(s)=A+B g(s)=A+B
r h s ( s ) = g ( s ′ ) + c ( s ′ , s ) = A + ∞ = ∞ rhs(s)=g(s')+c(s',s)=A+∞=∞ rhs(s)=g(s′)+c(s′,s)=A+∞=∞
k e y ( s ) = [ k 1 ( s ) ; k 2 ( s ) ] key(s)=[k1(s);k2(s)] key(s)=[k1(s);k2(s)]
其中:
k 1 ( s ) = m i n g ( s ) , r h s ( s ) + h ( s , G o a l ) k1(s)=min{g(s),rhs(s)}+h(s,Goal) k1(s)=ming(s),rhs(s)+h(s,Goal)
k 2 ( s ) = m i n g ( s ) , r h s ( s ) k2(s)=min{g(s),rhs(s)} k2(s)=ming(s),rhs(s)if k1(s)<= k1(s') or (k1(s)=k1(s') and k2(s)<= k2(s'))
k(s)<= k(s')
end
伪代码
For each s in Graph
s.g(x)=rhs(x)=∞;局部一致
end for each
startNode.rhs=0;局部过一致
Forever
While(OpenList.Top().key < goal.key OR goal is incosistent)
当OpenList中最优先点的key值小于目标点的key值或者目标点局部不一致时
currentNode=OpenList.Pop()
当前点为OpenList中最优先点,并将U中最优先的网格点删除
if (currentNode is overconsistent)
如果当前点局部过一致,代表网格上障碍物被清除或搜索到更短的“捷径”
currentNode.g(x)=currentNode.rhs(x);
令当前点的g(x)=rhs(x),使其局部一致
else
否则
currentNode.g(x)=∞;
局部过一致g(s)>rhs(s)或一致g(s)=rhs(s)
end if
for each s in currentNode.Children[]
update s.rhs(x);
局部过一致g(s)>rhs(s)或一致g(s)=rhs(s)
end for each
End while
Wait for changes in Graph
For each connection (u,v) with changed cost
Update connection(u,v);
Make v locally inconsistent;
end for each
End forever
参考资料
[2] 路径规划——Lifelong Planning A_star 算法
[3] LPA* 路径搜索算法介绍
[4] Lifelong planning A∗.pdf
[5]徐开放. 基于D_star Lite算法的移动机器人路径规划研究[D]. 哈尔滨工业大学, 2017.
[6]张浩. 地面移动机器人安全路径规划研究[D]. 安徽工程大学, 2015.搜索算法其他文章
Dstar Lite路径规划算法
D*路径搜索算法原理解析及Python实现