Scala学习笔记:Scala基础
目录
Scala基础
1.Scala基础数据类型
(1)数值类型:Byte、Short、Int、Long、Float、Double
(2)字符类型Char和字符串类型String
(3) 布尔类型
(4)Unit的类型
(5)Nothing类型
(6)Any类型
(7)AnyRef类型
2.变量与常量
3.函数与方法
4.条件表达式: if...else语句
5.循环语句: for、while、do..while、foreach迭代
for表达式
while循环
foreach迭代
6.Scala的函数参数
(1)函数参数的求值策略
(2)函数参数的类型
7.Scala的Lazy特性(懒执行特性)
8.异常处理
9.数组
(1)定长数组:Array
(2)变长数组:ArrayBuffer
(3)多维数组:通过数组的数组来实现
(4)区间数组
10.映射与元组
映射(Map)
元组(Tuple)
参考
Scala基础
1.Scala基础数据类型
Scala中所有的数据都是对象,也就是说scala没有java中的原生类型。在scala是可以对数字等基础类型调用方法的。
举例:数字 1是一个对象,就有方法(函数)
scala> 1.toString
res0: String = 1
可以不用指定数据的类型,Scala会自动进行类型的推荐
举例:下面的两条语句是一样的
val a:Int = 10
val b = 10 ----> b的类型就是Int
(1)数值类型:Byte、Short、Int、Long、Float、Double
Byte表示:8位有符号补码整数。数值区间为 -128 到 127
Short表示:16位有符号补码整数。数值区间为 -32768 到 32767
Int: 32位有符号补码整数。数值区间为 -2147483648 到 2147483647
Long:64位有符号补码整数。数值区间为 -9223372036854775808 到 9223372036854775807,数值后带L/l
Float:32 位, IEEE 754标准的单精度浮点数,浮点数后带F/f的就是Float
Double:32 位 IEEE 754标准的单精度浮点数,浮点数后不带F/f的就是Double
(2)字符类型Char和字符串类型String
字符串的操作
//定义一个字符,字符是要用单引号来定义的
scala> var c1 = 'x'
c1: Char = x
//定义一个字符串,注意这里使用了双引号
scala> val s1 = "Hello World"
s1: String = Hello World
//字符串的插值
scala> s"My name is Tom and ${s1}"
res2: String = My name is Tom and Hello World(3) 布尔类型
取值只有true和false
(4)Unit的类型
相当于Java的void
scala> def printname() {
| println("name")
| }
printname: ()Unit
scala> printname()
name(5)Nothing类型
Nothing类型在Scala的类层级的最低端;它是任何其他类型的子类型。代码中如果出现Nothing类型的时候,在load到JVM运行的时候将会把Nothing替换为Nothing$类型。也即在JVM之外以Nothing的身份进行显示,在JVM中以Nothing$的身份进行显示,两者表示同一个含义。这样解释也满足了Nothing可以当做 throw new XXXXXException("head of empty list")的类型使用的原因,即: Nothing$ extends Throwable.
(6)Any类型
Any是所有其他类的超类
(7)AnyRef类型
AnyRef类是Scala里所有引用类(reference class)的基类
2.变量与常量
在Scala中,常量用val关键字定义,变量用var关键字定义,注意在Scala里这两个关键字要用小写,否则会报错
scala> Var x:Long =1
:1: error: ';' expected but '=' found.
Var x:Long =1
^
scala> var x:Long =1
x: Long = 1
scala> Val y:Long = 1L
:1: error: ';' expected but '=' found.
Val y:Long = 1L
^
scala> val y:Long = 1L
y: Long = 1 3.函数与方法
Scala 中使用 val 语句可以定义函数,def 语句定义方法,但本质上两者没什么区别。Scala 方法是类的一部分,而函数是一个对象可以赋值给一个变量。换句话来说在类中定义的函数即是方法。
Scala 中的方法跟 Java 的类似,方法是组成类的一部分。
Scala 中的函数则是一个完整的对象,Scala 中的函数其实就是继承了 Trait 的类的对象。
方法实例:递归实现斐波那契
scala> def Fibonacci(n:Int):Int={
| if (n<=2 && n>0) 1
| else Fibonacci(n-1)+Fibonacci(n-2)
| }
Fibonacci: (n: Int)Int
scala> for(i<-1 to 10)
| print(Fibonacci(i)+" ")
1 1 2 3 5 8 13 21 34 554.条件表达式: if...else语句
scala> def myFactor(x:Int):Int = {
| if(x<=1)
| 1 注意:Scala的函数中,函数的最后一句话就是函数的返回值
| else
| myFactor(x-1)*x
| }
5.循环语句: for、while、do..while、foreach迭代
for表达式
通过使用被称为发生器(generator)的语法“files<-filesHere”,遍历了list里的元素,每一次枚举,名为s的新的val就被元素值初始化,函数体println(s)也将被执行一次
在写for循环的时候,可以在for表达式的括号里添加过滤器,如第三种写法;第二种写法等价于第三种。for表达式里可以加入超过一个的过滤器,if子句必须用分号分隔。同样的,生成器也是可以加入超过一个的,这样就等同于其他语言的for循环嵌套。
之前的例子都是对枚举值进行操作,然后就释放。在for表达式之后加上关键字yield,就可以创建一个值去记住每一次的迭代。
package ch01.s02
object mydemo01 {
def main(args: Array[String]): Unit = {
var list = List("Mary","Mike","Tom")
//for循环的第一种写法
for(s <- list) println(s)
//for循环的第二种写法
for{
s <- list
if(s.length > 3)
}println(s)
//for循环的第三种写法
for(s<-list if s.length>3) println(s)
//使用yield生成一个新的集合
var newList = for{
s <- list
s1 = s.toUpperCase()
}yield(s1)
for(a <- newList) println(a)
}
}while循环
while循环分两种:while和do-while
之所以把while称为循环,而不是表达式,是因为它们不能产生有意义的结果,结果的类型是Unit,下面代码可以看见,方法体前面没有等号。
package practice
object test1 {
def main(args: Array[String]): Unit = {
var list = List("Mary","Mike","Tom")
//while循环
var i = 0
while(i < list.length){
println(list(i))
i += 1
}
//do-while循环
var j = 0
do{
println(list(j))
j += 1
}while(j还有一个值得注意的是,对var再赋值等式本身也是unit值,假设使用以下的例子,编译的时候,Scala会警告comparing values of types Unit and String using `!=' will always yield true,所以循环会变成死循环
var line=""
while ((line = readLine()) != "")
println("Read: "+ line)foreach迭代
这里的例子使用集合的foreach方法进行迭代,输出list里的数据。
第一行代码对list调用了foreach方法,并把函数字面量作为参数传入,符号=>表示这个函数将左边的东西转换成了符号右边的东西,在这里就是把element变成了打印element,可以把函数字面量就此理解为匿名函数。
Scala解释器可以推断element的类型是String,因为String是调用foreach的那个list的元素类型。如果想要表达的更明确一些,可以像第二行代码一样指明类型,并用括号括起来。
而函数字面量在这只有一行语句,并且只带一个参数,那么甚至连指代参数都不需要,可以写成第三行代码这样的形式
package practice
object test1 {
def main(args: Array[String]): Unit = {
var list = List("Mary","Mike","Tom")
list.foreach(element => println(element))
list.foreach((element:String) => println(element))
list.foreach {println}
}
}6.Scala的函数参数
(1)函数参数的求值策略
call by value:对函数实参进行求值,并且只求一次
call by name:函数实参在函数内部调用的时候,才会求值,每次都会求值
举例:Call by value 使用冒号
def func1(x:Int,y:Int):Int = x + x
Call by name 使用 : =>
def func2(x: => Int,y: => Int):Int = x + x
调用:
func1(3+4,8)
执行过程 1:fun1(7,8)
2:7+7
3:4
func2(3+4,8)
执行过程 1:(3+4)+(3+4)
2:7 +(3+4)
3:7 + 7
4:14
复杂一点的例子
def bar(x:Int,y: => Int):Int = 1
def loop():Int = loop //死循环
调用 bar(1,loop) 输出:1
bar(loop,1) 可以看到worksheet里这条语句上有个不断转动的杠,进入了死循环
原因还是一样的,bar(1,loop)调用的时候,x是call by value,y是call by name,所以这里会先对x做一个求值,x=1,而y在没有调用到它的情况下,是不会进行求值的;同样的bar(loop,1)也是一样的道理,对x做求值,这个时候程序就会进入一个死循环的情况。
(2)函数参数的类型
默认参数
可以看到,当指定了默认参数值的时,即便没有参数值传入,也会按默认值来进行运算。
代名参数
func2中每个参数都有默认值,我们可以通过指定参数名以及参数值去将默认值给替换掉
可变参数
在参数类型的后面加上星号(*),就说明参数的个数不确定,且均为这个类型
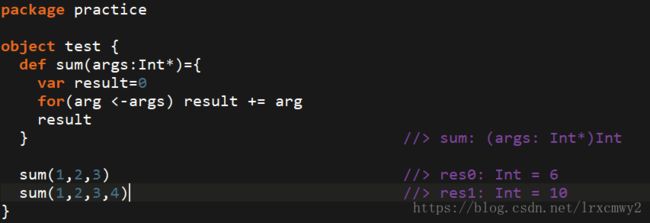
7.Scala的Lazy特性(懒执行特性)
当一个变量被申明是lazy,他的初始化会被推迟,直到第一次使用他的时候,才会被初始化

另一个例子,没有添加Lazy关键字的时候,会抛出异常,因为b.txt根本不存在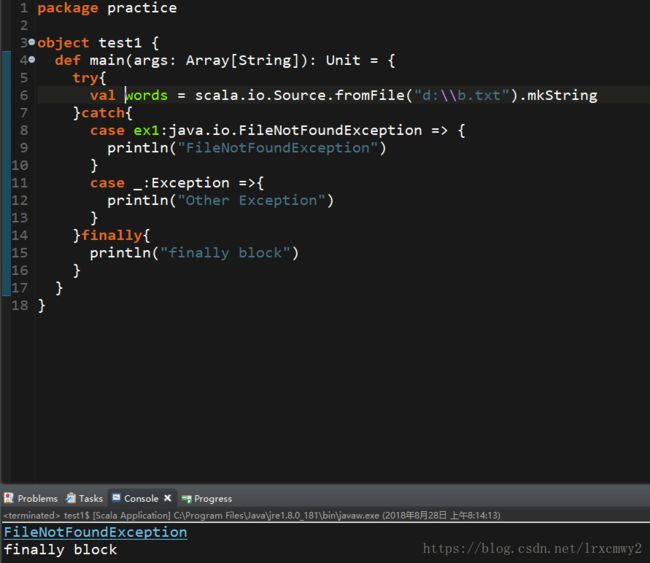
而加上Lazy关键字后,因为没有调用words,所以没有抛出异常
8.异常处理
还是上面的例子,除了直接打印异常,还可以像Java一样用try..catch..finally来进行异常捕获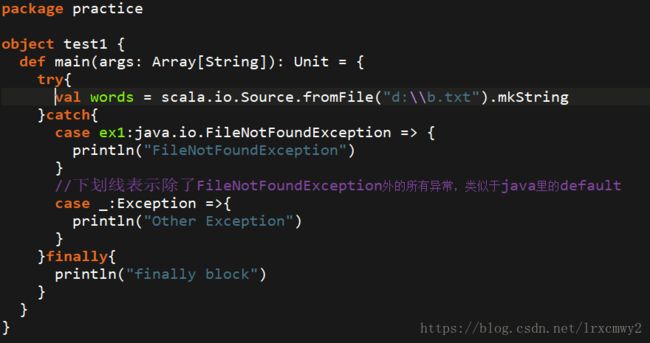
9.数组
Scala里使用new实例化对象,实例化过程中,可以用值和类型使对象参数化,参数化的意思是指在创建实例的同时完成对它的“设置”,数组同样可以如此。
(1)定长数组:Array
数组的索引从0开始,最大值为数组的长度-1,整数类型的数组初始值全部为0,而String类型的为Null
限定数组长度
val a = new Array[Int](10)
val b = new Array[String](5)
对数组直接进行初始化
val c = Array("Tom","Mary","Mike")
val a = new Array[Int](1,2,4,9,5)
注意,尽管使用的是val进行定义,但是数组内部的元素是可以被修改的,只是数组对象不能被重新赋值成新的数组
对数组进行排序并输出,这里是降序排列
a.sortwith(_>_).foreach(print)
(2)变长数组:ArrayBuffer
import scala.collection.mutable._
val d = ArrayBuffer[Int]()
往变长数组中添加元素
d += 1
d += 2
d += 3
一次添加多个元素
d += (10,20,30)
去掉数组中的元素
d.trimEnd(2)
(3)多维数组:通过数组的数组来实现
数组中的每一个值都可以是一个数组
import Array._
object Test {
def main(args: Array[String]) {
//定义二维数组,设定长宽
var myMatrix = ofDim[Int](3,3)
//初始化数组
for (i <- 0 to 2) {
for ( j <- 0 to 2) {
myMatrix(i)(j) = j;
}
}
//打印二维数组
for (i <- 0 to 2) {
for ( j <- 0 to 2) {
print(" " + myMatrix(i)(j));
}
println();
}
}
}(4)区间数组
使用range方法生成数组
import Array._
object Test {
def main(args: Array[String]) {
//使用range方法生成数组,注意,是左闭右开区间,第三个参数为增长量
var myList1 = range(10, 20, 2)
var myList2 = range(10,20)
// 输出所有数组元素
for ( x <- myList1 ) {
print( " " + x )
}
println()
for ( x <- myList2 ) {
print( " " + x )
}
}
}10.映射与元组
映射(Map)
Map是一种可迭代的键值对(key/value)结构,所有的值都可以通过Key来获取,Map 中的Key都是唯一的。
Map 也叫哈希表(Hash tables)。
Map 有两种类型,可变与不可变,区别在于可变对象可以修改它,而不可变对象不可以。
默认情况下 Scala 使用不可变 Map。如果需要使用可变集合,要引入 import scala.collection.mutable.Map 类 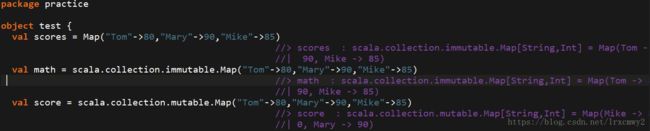
当key不存在的时候,就会报错![]()
避免异常的方法当然是使用条件控制语句,或者getOrElse方法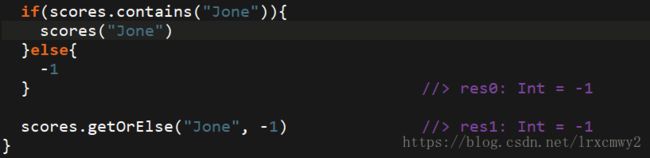
Map的增删改、遍历
元组(Tuple)
与List一样,元组也是不可变的,但与列表不同的是元组可以包含不同类型的元素。
可以利用Scala的类型推断来隐式定义一个元组,也可以显式的new,但注意显式的情况下,Tuple后面要跟元组的长度,目前Scala Tuple的最大长度为22
Tuple不能直接用foreach来遍历,所以要使用迭代器再foreach进行遍历
Tuple还可以使用tostring方法来将元组转换成字符串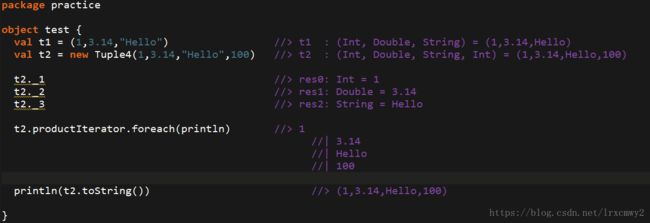
参考
scala(一)Nothing、Null、Unit、None 、null 、Nil理解
https://www.cnblogs.com/PerkinsZhu/p/7868012.html
《Scala编程》Programming in Scala