DBSCAN聚类算法难吗?我们来看看吧~
往期经典回顾
从零开始学Python【29】--K均值聚类(实战部分)
从零开始学Python【28】--K均值聚类(理论部分)
从零开始学Python【27】--Logistic回归(实战部分)
从零开始学Python【26】--Logistic回归(理论部分)
从零开始学Python【25】--岭回归及LASSO回归(实战部分)
距离上一篇从零开始学Python系列已将近1年,在这一年中我一直忙于新书的编写,如今新书已上市,即《从零开始学Python数据分析与挖掘》。接下来我可以继续分享Python相关的知识点,主题包含数据可视化、数据分析和数据挖掘。
前言
在第29期,我们分享了有关K均值聚类的项目实战,本期将介绍另一种聚类算法,那就是基于密度聚类的算法。该算法的最大优点是可以将非球形簇实现恰到好处的聚类,如下图所示,即为一个非球形的典型图形:
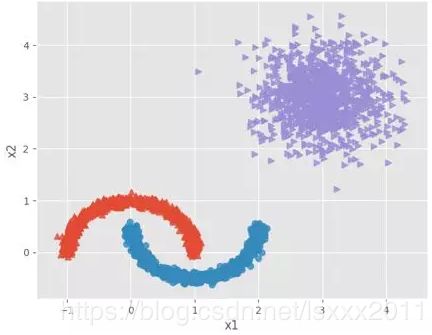
如上图所示,右上角的样本点为一个簇,呈现球形特征,但是左下角的两个样本簇,存在交合状态,并非球形分布。如果直接使用K均值聚类算法,将图形中的数据,聚为三类,将会形成下图的效果:

如上图所示,K均值聚类的效果很显然存在差错。如果利用本文所接受的DBSCAN聚类算法,将不会出现这样的问题。不妨先将DBSCAN的聚类效果呈现在下图:

如上图所示,基于密度聚类的算法(DBSCAN),就可以得到非常理想的聚类效果。接下来需要分享一下,为什么DBSCAN可以做到完美的聚类。
DBSCAN理论--基本概念
密度聚类算法中的“密度”一词,可以理解为样本点的紧密程度,而紧密度的衡量则需要使用半径和最小样本量进行评估,如果在指定的半径领域内,实际样本量超过给定的最小期望样本量,则认为是高密度对象。那么问题来了,该算法是如何基于半径和最小样本量完成聚类的呢?回答这个问题之前,需要理解一些基本概念:
点的 领域:在某点p处,给定其半径
领域:在某点p处,给定其半径 后,所得到的覆盖区域;
后,所得到的覆盖区域;
核心对象:对于给定的最少样本量MinPts而言,如果某点p的领域内至少包含MinPts个样本点,则点p就为核心对象;
直接密度可达:假设点p为核心对象,且在点p的领域内存在点q,则从点p出发到点q是直接密度可达的;
密度可达:假设存在一系列的对象链 ,如果
,如果 是关于半径和最少样本点MinPts的直接密度可达
是关于半径和最少样本点MinPts的直接密度可达 (
( ),则
),则 密度可达
密度可达 ;
;
密度相连:假设点o为核心对象,从点o出发得到两个密度可达点p和点q,则称点p和点q是密度相连的;
聚类的簇:簇包含了最大的密度相连所构成的样本点;
边界点:假设点p为核心对象,在其领域内包含了点b,如果点b为非核心对象,则称其为点p的边界点;
异常点:是指不属于任何簇的样本点;
为使读者很好的理解上面的概念,以及它们之间的差异,可以参考下面的图片:
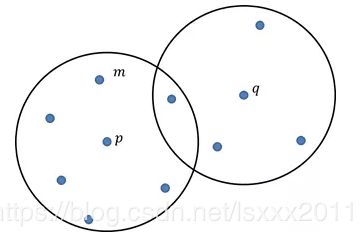
如上图所示,如果为3,MinPts为7,则点p为核心对象(因为在其领域内至少包含了7个样本点);点q为非核心对象;点m为点p的直接密度可达(因为它在点p的领域内)。

如上图所示,如果为3,MinPts为7,则点 和
和 为核心对象;点
为核心对象;点 为非核心对象;点
为非核心对象;点 直接密度可达点
直接密度可达点 、点
、点 直接密度可达点
直接密度可达点 、点直接密度可达点,所以点密度可达点;点为核心点的边界点。
、点直接密度可达点,所以点密度可达点;点为核心点的边界点。
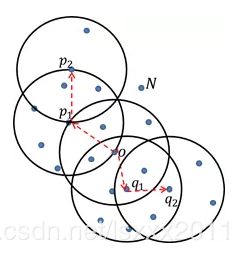
如上图所示,如果为3,MinPts为7,则点 ,和
,和 为核心对象;点
为核心对象;点 和
和 为非核心对象;由于点密度可达点,并且点密度可达点,则称点和点是密度相连的,如果点和点是最大的密度相连,则上图中的所有样本点构成一个簇;由于点
为非核心对象;由于点密度可达点,并且点密度可达点,则称点和点是密度相连的,如果点和点是最大的密度相连,则上图中的所有样本点构成一个簇;由于点 不属于上图中呈现的簇,故将其判断为异常点。
不属于上图中呈现的簇,故将其判断为异常点。
DBSCAN理论--基本步骤
输入:包含n个对象的集合D,指定半径和最少样本量MinPts。
输出:所有生成的簇,达到密度要求。
1)repeat
2)从集合D中抽取一个未处理的点;
3)如果抽出的点是核心点,则找出所有从该点出发的密度可达对象,形成簇;
4)如果抽出点的为非核心点,则跳出循环,寻找下一个点;
5)until所有点都被处理。
这里用一个简单的例子叙述DBSCAN算法步骤,以说明该方法的思路和操作过程:
首先看一下数据集合D:
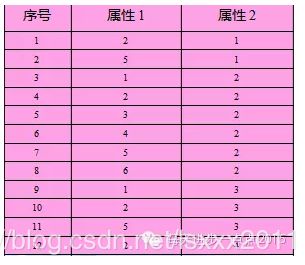
第1步:在集合D中选择点1,以它为圆心,1为半径画圆,发现仅有2个点在圆内,因此点1不为核心点,选择下一个点;
第2步:在集合D中选择点2,以它为圆心,1为半径画圆,发现仅有2个点在圆内,因此点2不为核心点,选择下一个点;
第3步:在集合D中选择点3,以它为圆心,1为半径画圆,发现仅有3个点在圆内,因此点3不为核心点,选择下一个点;
第4步:在集合D中选择点4,以它为圆心,1为半径画圆,发现有5个点在圆内,因此点4为核心点,接着寻找从该点出发的直接可达。聚成新类{1,3,4,5,9,10,12},完成后继续选择下一个点;
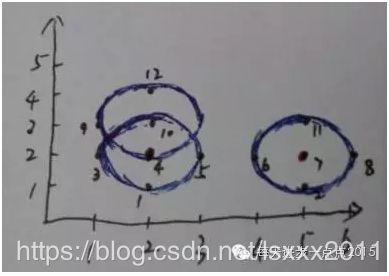
第5步:在集合D中选择点5,发现该点已在簇1中,选择下一个点;
第6步:在集合D中选择点6,以它为圆心,1为半径画圆,发现仅有3个点在圆内,因此点6不为核心点,选择下一个点;
第7步:在集合D中选择点7,以它为圆心,1为半径画圆,发现有5个点在圆内,因此点7也为核心点,接着寻找从该点出发的直接可达。聚成新类{2,6,7,8,11},完成后继续选择下一个点;
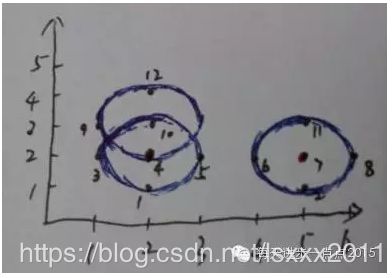
第8步:在集合D中选择点8,发现该点已在簇2中,选择下一个点;
第9步:在集合D中选择点9,发现该点已在簇1中,选择下一个点;
第10步:在集合D中选择点10,发现该点已在簇1中,选择下一个点;
第11步:在集合D中选择点11,发现该点已在簇2中,选择下一个点;
第12步:在集合D中选择点12,发现该点已在簇1中,此时所有点都被处理过,程序结束。
最终,通过这一流程下来,发现这12个点的集合D可以形成2个簇。
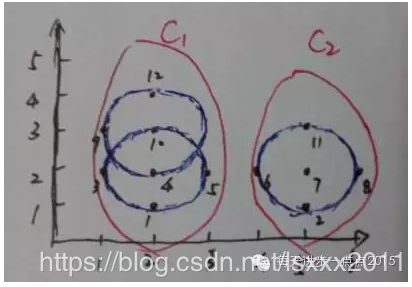
DBSCAN的缺点
1)需要为算法指定eps和MinPts参数,这对分析人员是一个很大的挑战;
2)DBSCAN聚类算法对参数eps和MinPts的设置是非常敏感的,如果指定不当,该算法将造成聚类质量的下降。
结语
OK,关于密度聚类算法的理论部分我们就分享到这里,在《从零开始学Python数据分析与挖掘》一书中,对密度聚类算法也作了更多的讲解。下一期我们将针对该算法使用Python进行实战分析。如果你有任何问题,欢迎在公众号的留言区域表达你的疑问。同时,也欢迎各位朋友继续转发与分享文中的内容,让更多的人学习和进步。