Redis-跳表
Redis-跳表
跳表(skiplist)是一种有序数据结构,它通过在每个节点维持多个指向其他节点的指针来达到快速访问的目的。Redis使用跳表作为有序表的底层实现。
Redis的有序集合和散列一样,也是健值对。有序集合的键是成员对象(其实就是一个简单动态字符串SDS),成员对象是各不相同的,有序集合的值是分值。比如有一个有序集合s,它的值集合为(m1,4)、(m2,6)、(m3, 8),则该有序集合的键为s,它的成员对象为m1、m2、m3,分值分别为4、6、8,有序集合就可以根据分值来将成员对象进行排序。
下面是一个添加的示例,添加完元素后执行zrange命令取出排序后的集合。
127.0.0.1:6379> zadd s 6 m2
(integer) 1
127.0.0.1:6379> zadd s 8 m3
(integer) 1
127.0.0.1:6379> zadd s 4 m1
(integer) 1
127.0.0.1:6379> zrange s 0 -1 withscores
1) "m1"
2) "4"
3) "m2"
4) "6"
5) "m3"
6) "8"首先介绍下跳表这个数据结构
跳表
描述跳表之前我们先简单回顾下链表

图1
如图1所示的有序链表中,头指针为head,当想查找关键字7、15、46时,从头指针开始,需要分别比较3次、7次、13次。这种效率是比较低的,查找复杂度为O(n)。为了解决这个问题,我们学习过二叉树、红黑树,这两个数据结构确实能够高效的操作有序表,但是这些数据结构本身的复杂度也不容小觑,需要关注的细节很多,不容易把握。

图2
跳表的查找
在图1的基础上修改为图2,例如对于关键字15,查询的步骤为:
结点从上往下查找,第一个节点的最上层(第2层)指向的下个节点值为8(小于15),则直接从值为1的节点跳到值为8的节点。
值为8 的节点最上层(第2层)指向的下一节点值为18(大于15),则从该节点的下一层开始查找。
从值为8的节点的第一层一直往后走,直到找到关键字为15为止。如图3所示查找过程(深色部分)。

图3
对于关键字46,查找的步骤为:
- 结点从上往下查找,第一个节点的最上层(第2层)指向的下个节点值为8(小于46),则直接从值为1的节点跳到值为8的节点。
- 值为8的节点的最上层(第2层)指向的下一节点的值为18(小于46),则从值为8的节点跳到值为18的节点。
- 值为18的节点的下一个节点值为40(小于46),则从值为18的节点跳到值为40的节点。
- 值为40的节点的下一个节点为空(到达该层链表的末尾),往下一层查找,直到找到46,查找结束。如图4所示查找过程(深色部分)。

图4
此时发现,若有2层,则查找效率会提高不少。当节点的层数为3时,即节点最多有3个指向其他节点的指针时,查找效率更高,如图5所示查找关键字46的示意图(深色部分)。

图5
以上我们已经介绍了跳表的核心思想,总结下跳表的关键特性:
- 跳表由很多层组成。
- 每一层都是一个有序链表。
- 每一层的最后一个值都为空,表示该有序链表结束。
- 最底层(第1层)包括了所有元素。
- 如果一个元素出现在节点的上层,则该元素将出现在该节点所有的下层。
- 对于每个节点的每一个元素,不仅有指向下一个节点的指针,也有指向当前节点下一层的指针。
跳表的插入
若在图5中插入关键字14,首先确定该关键字的层数,层数是根据随机算法生成的,但是为了不让层数过大,会有一个最大层数MAX_LEVEL限制,随机算法生成的数值不得大于该值。
假设生成的随机层数为2,则插入如图6所示。首先断开关键字为13和关键字为15的链,在中间插入关键字14,将原来关键字为8的节点指向关键字为18节点的指针改为指向新插入的关键字14,新插入的关键字最上层(第2层)指向关键字为18的节点。
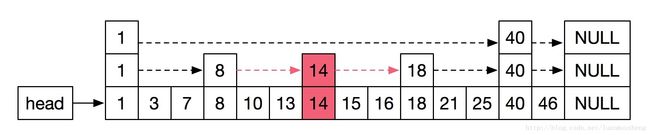
图6
若生成的随机层数为4,则插入如图7所示。首先整个跳表的层数将增加,由原来的最高3层变为最高4层。
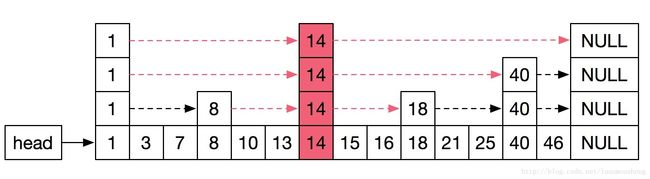
图7
跳表的删除
跳表的删除逻辑逻辑如图8示

图8
Redis跳表
Redis跳表由zskiplistNode和zskiplist两个结构定义的
跳表结点定义-zskiplistNode
typedef struct zskiplistNode {
//后退指针
struct zskiplistNode *backward;
//分值
double score;
//成员对象
robj *obj;
//层
struct zskiplistLevel {
//前进指针
struct zskiplistNode *forward;
//跨度
unsigned int span;
} level[];
} zskiplistNode;- backward:节点的后退指针,跳表可以从尾部往头部节点方向访问,每次只能后退至前一个节点,这点和前进指针不同。前进指针可以往尾部结点方向跳跃多个节点。
- score和obj:score(分值)是跳表用来排序的,它是一个double类型的值。obj是结点的成员对象,它是一个指向字符串对象(SDS)的指针。跳表中成员对象必须是唯一的,但是分值却可以相同,分值相同的节点按照成员对象的大小从小到大排列。
- level:跳表节点的level是一个数组,其中每一个元素都有指向下个节点的指针,数组越大,层数越多,访问其他节点越快。每次创建新的节点时,会随机生成1至32的整数作为该节点的层数。层数从0开始,即level[0]为第一层,level[1]为第二层。
- forward:前进指针,节点的每层都有一个前进指针,该前进指针指向跳表后面的节点。前进指针可以跳过多个节点,指向较远处的节点。
- span:节点的每层都有一个跨度,该值指示了前进指针指向的下一个节点和该节点的距离,即跨度是多少。
如图9示三个不同层数的跳表节点,节点层数分别为1、2、3
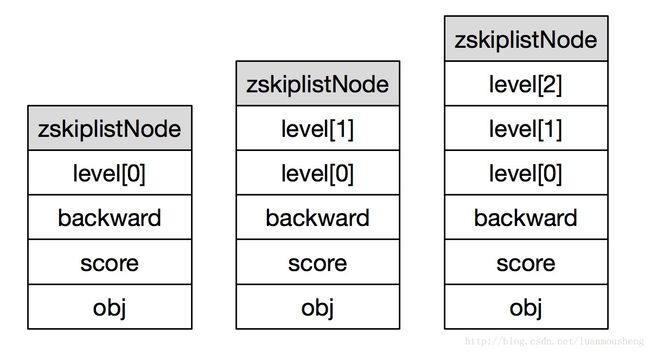
图9
跳表定义-zskiplist
Redis定义了跳表zskiplist
typedef struct zskiplist {
//表头节点
struct zskiplistNode *header;
//表尾节点
struct zskiplistNode *tail;
//表中节点的数量
unsigned long length;
//表中层数最大的节点的层数
int level;
} zskiplist;- header:指向跳表的表头节点
- tail:指向跳表的表尾节点
- length:记录跳表包含节点的数量,不包括头节点
- level:记录该跳表中节点的最大层数
图10所示一个完整的跳表,其中头结点包括了所有的1至32层,头结点省略了后退指针、分值、成员对象,因为这些字段在头结点中未使用,箭头上的数字表示跨度值。
当访问分值为3.0,对象为O4时为虚线路径所示。
- 由头指针访问到头结点
- 头结点从上层往下层遍历,直到L4,L4的forward指针指向的结点就是需要找到的结点,遍历结束。
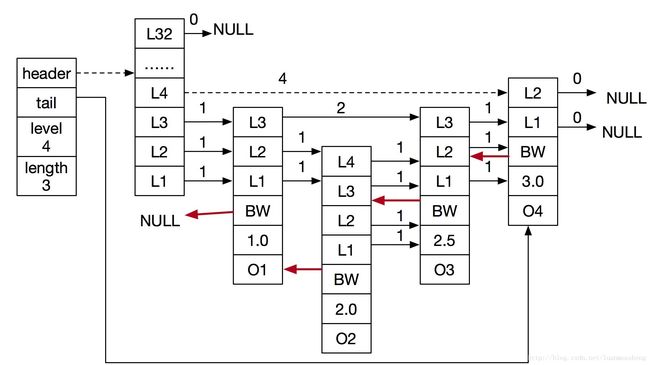
图10
当访问分值为2.5,对象为O3时的路径为图11的虚线路径所示
- 从头指针访问到头结点
- 头结点从上层往下层遍历,访问到第一个forward指针不为空的L4层时,发现L4层的forward指针指向的节点不是O3,并且分值为3.0(大于2.5),继续往下遍历到L3层
- L3层forward指针指向的节点分值为1.0(小于2.5),查询路径移到该节点
- 从对象为O1节点的上层往下层遍历,L3层的forward指针指向的下一个节点即是需要查找的节点,遍历结束。
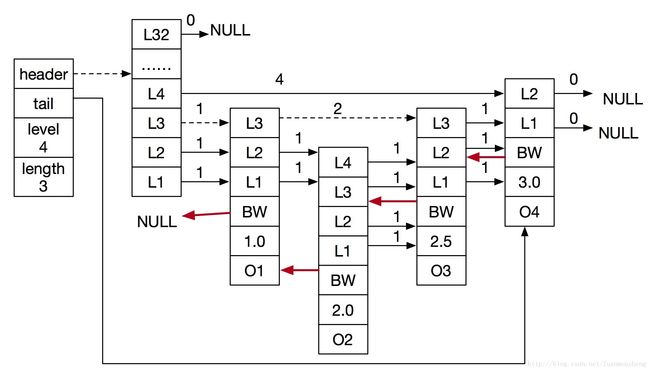
图11
补充:
查看redis源码跳表插入方法zslInsert有这么一句注释
zskiplistNode *zslInsert(zskiplist *zsl, double score, robj *obj);
/* we assume the key is not already inside, since we allow duplicated
* scores, and the re-insertion of score and redis object should never
* happen since the caller of zslInsert() should test in the hash table
* if the element is already inside or not. */这句话的意思其实就是说跳表中成员对象不能重复,只能有一个,如果插入的成员对象已经存在,则会更新对应的分值。
另外,值得注意的是在调用zslInsert前,调用方需要去判断该对象是否已经存在,怎么判断?在哈希表中判断,也就是redis维护了成员对象的哈希表,方便根据成员对象来快速查找该对象是否在该跳表中。
我们调用redis的命令zrank时,只要传跳表的key和成员对象即可,如:
127.0.0.1:6379> zrank s m3
(integer) 2但是,其实源码中的声明是这样的
unsigned long zslGetRank(zskiplist *zsl, double score, robj *o);redis需要去根据命令zrank传入的参数(成员对象)去查该成员对象对应的score,然后才能调用zskGetRank。
参考
- Redis设计与实现. 黄健宏著
- Redis In Action. [美] Josiah L. Carlson 著. 黄健宏译