selenium+chrome多线程爬取多个网站信息
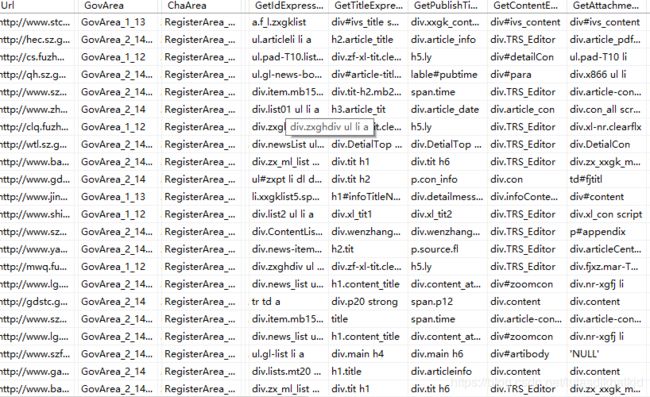
- 本文创建sqlserver数据库连接池,从数据库读取相关网站配置。下图为各个网址的数据标签定位配置:
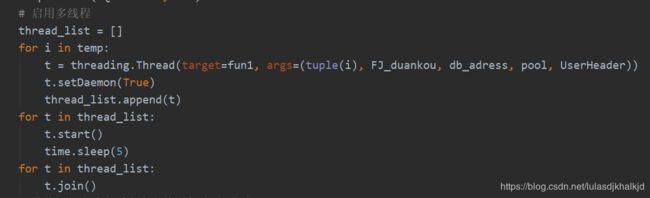
 2. 获得配置之后,创建多线程。从配置文件中读取配置后,
2. 获得配置之后,创建多线程。从配置文件中读取配置后,
下图为创建多线程(threading):
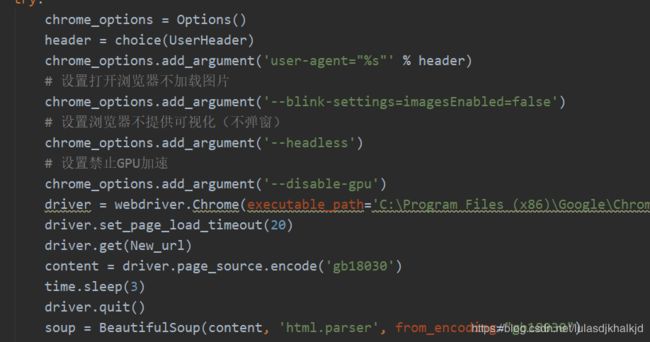
 3. 接下来使用selenium+chromedriver调用浏览器,使用beautifuisoup解析页面爬取动态页面数据:
3. 接下来使用selenium+chromedriver调用浏览器,使用beautifuisoup解析页面爬取动态页面数据:
最后展示全部代码:
import pyodbc
import pymssql
import socket
import _mssql
import uuid
from multiprocessing import Lock, Pool
import multiprocessing
import decimal
from DBUtils.PooledDB import PooledDB
import time
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.triggers.interval import IntervalTrigger
import threading
import re
import os
import pytz
import time
import configparser
import html
import urllib
import uuid
from urllib import request
import requests
import datetime
from bs4 import BeautifulSoup
from k_v import k_v
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from fake_useragent import UserAgent
from random import choice
UserHeader = [
“Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36”,
“Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2226.0 Safari/537.36”,
“Mozilla/5.0 (Windows NT 6.4; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36”,
“Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36”,
“Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36”,
“Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.93 Safari/537.36”,
“Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36”,
“Mozilla/5.0 (Windows NT 4.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36”,
“Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.67 Safari/537.36”,
“Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.67 Safari/537.36”,
“Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.3319.102 Safari/537.36”,
“Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36”,
“Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.2309.372 Safari/537.36”,
“Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.2117.157 Safari/537.36”,
“Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1866.237 Safari/537.36”,
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.116 Safari/537.36 ",
“Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1667.0 Safari/537.36”,
“Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.16 Safari/537.36”,
“Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1623.0 Safari/537.36”,
“Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.17 Safari/537.36”,
“Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.62 Safari/537.36”,
“Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.2 Safari/537.36”,
“Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1468.0 Safari/537.36”,
“Mozilla/5.0 (Windows NT 6.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1467.0 Safari/537.36”,
“Mozilla/5.0 (Windows NT 6.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1464.0 Safari/537.36”,
“Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1500.55 Safari/537.36”,
“Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36”,
“Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36”,
“Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36”,
“Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36”,
“Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.90 Safari/537.36”,
“Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.60 Safari/537.17”,
“Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.15 (KHTML, like Gecko) Chrome/24.0.1295.0 Safari/537.15”,
“Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.14 (KHTML, like Gecko) Chrome/24.0.1292.0 Safari/537.14”]
连接数据库
def sql_lianjie():
cf = configparser.ConfigParser()
cf.read("./run.ini")
db_Host = cf.get(“db”, “db_ip”)
db_post = cf.get(“db”, “db_post”)
db_user = cf.get(“db”, “db_user”)
db_password = cf.get(“db”, “db_password”)
db_database = cf.get(“db”, “db_database”)
db_charset = cf.get(“db”, “db_charset”)
# 创建数据库连接池
pool = PooledDB(creator=pymssql, mincached=3, maxshared=9, maxconnections=6, blocking=False,host=db_Host, port=int(db_post), user=db_user, password=db_password, database=db_database, charset=db_charset)
if not pool:
raise (NameError, ‘连接数据库失败’)
else:
print(‘连接成功’)
return pool
将配置数据平均分成几等分
def func(listTemp, n):
aaa = []
for i in range(0, len(listTemp), n):
aaa.append(listTemp[i:i + n])
return aaa
实时监测程序运行状态,当程序运行完成时在此调用函数并运行代码
def running():
scheduler = BlockingScheduler()
c1 = IntervalTrigger(minutes=1)
scheduler.add_job(start_object, c1)
scheduler.start()
连接数据库并创建连接池,读取配置文件后执行多线程爬虫
def start_object():
# 当程序开始时,在日志文件载入记录
with open(’./all.log’, ‘a’, encoding=‘utf-8’) as LOG:
shijian = datetime.datetime.now()
LOG.write(str(shijian)[:-7] + ‘-’ + ‘---------------------------爬虫开始运行---------------------------’ + ‘\n’)
LOG.close()
pool = sql_lianjie()
conn = pool.connection()
cur = conn.cursor()
# 读取配置文件
cf = configparser.ConfigParser()
cf.read("./run.ini")
FJ_duankou = cf.get(“db”, “db_host”)
FJ_sql = cf.get(“db”, “db_sql”)
db_adress = cf.get(“db”, “db_adress”)
# 信息网区域
cur.execute(FJ_sql)
SQLsession = cur.fetchall()
cur.close()
conn.close()
# 每个线程数据传输100条
temp = func(SQLsession, 100)
# 启用多线程
thread_list = []
for i in temp:
t = threading.Thread(target=fun1, args=(tuple(i), FJ_duankou, db_adress, pool, UserHeader))
t.setDaemon(True)
thread_list.append(t)
for t in thread_list:
t.start()
time.sleep(5)
for t in thread_list:
t.join()
# 等待运行完成之后在去文件写入‘运行成功’
with open(’./all.log’, ‘a’, encoding=‘utf-8’) as LOG:
shijian = datetime.datetime.now()
LOG.write(str(shijian)[:-7] + ‘-’ + ‘---------------------------运行成功,正在等待重启---------------------------’ + ‘\n\n\n’)
LOG.close()
time.sleep(180)
从数据库得到配置数据并传入爬虫函数中.
def fun1(SQLsession,FJ_duankou,db_adress,pool, UserHeader):
for get_SQLsession in SQLsession:
# 查册网版块
ChaPlate = get_SQLsession[3]
# 信息网区域
GovArea = get_SQLsession[2]
# 查册网区域
ChaArea = get_SQLsession[4]
# 附件下载地址
FJ_adress = FJ_duankou + db_adress
# url地址
url = get_SQLsession[1]
# print(url)
# 每个公告的id拼接
ID = get_SQLsession[5]
# 标题
TITLE = get_SQLsession[6]
# 发布时间
PUBLISHTIME = get_SQLsession[7]
# 内容
CONTENT = get_SQLsession[8]
# 附件
FJ_Download = get_SQLsession[9]
# 最后一次获取ID
LastGetID = get_SQLsession[10]
# Mainid获取
ConfigId = get_SQLsession[0]
# 拼接ID
ID_Splicing = get_SQLsession[11]
# 拼接附件
FJ_Splicing = get_SQLsession[12]
# 获取请求头get_SQLsession[13]
User_agent = choice(UserHeader)
header = {‘User-Agent’: User_agent}
get_url(url, ID, TITLE, PUBLISHTIME, CONTENT, GovArea, ChaArea, FJ_Download, FJ_adress, LastGetID, ChaPlate, ConfigId, db_adress, header, ID_Splicing, FJ_Splicing, pool, UserHeader)
进行网页解析并进行去重检测
def get_url(url, ID, TITLE, PUBLISHTIME, CONTENT, GovArea, ChaArea, FJ_Download, FJ_adress, LastGetID, ChaPlate, ConfigId, db_adress, header, ID_Splicing, FJ_Splicing, pool, UserHeader):
try:
socket.setdefaulttimeout(20)
# 随机生成请求头user-agent
response = requests.get(url, headers=header, timeout=20)
response.encoding = ‘utf-8’
time.sleep(3)
soup = BeautifulSoup(response.text, ‘html.parser’)
try:
time.sleep(1)
Url = soup.select(ID)
time.sleep(1)
Session = 0
for i in Url:
Get_ID = re.findall(r’\d+?.[a-z]+?.\d+\d+?.[a-z]{3,5}|20\d+/\S+.[a-z]{3,5}|content/post\d+.?[a-z]{3,4}|adetail\d+_\d+|.?p=\d+|HTML/zwgk\S+.?[a-z]{3,4}|\d+article\d+|aspx.?id=\d+|.asp.?id=\d+|.jsp.?trid=\d+’, str(i.get(‘href’)))
if Get_ID:
New_url = ID_Splicing + Get_ID[0]
if LastGetID == Get_ID[0]:
print(’---------------页面未更新------------’)
break
else:
Session += 1
if Session == 1:
conn = pool.connection()
cur = conn.cursor()
sql = “UPDATE dbo.TDOA_CcwNewsConfig SET LastGetId=’%s’ WHERE Url=’%s’” % (Get_ID[0], url)
cur.execute(sql)
print(‘记录%s条ID成功’ % Session)
conn.commit()
cur.close()
conn.close()
# =====================================================
print(New_url)
open_url(New_url, TITLE, PUBLISHTIME, CONTENT, GovArea, ChaArea, url, FJ_Download, FJ_adress, Get_ID, ChaPlate, ConfigId, db_adress, FJ_Splicing, Url, ID_Splicing, pool, UserHeader)
else:
Get_ID = re.findall(r'\d+\S+.[a-z]{3,5}.?id=\d+|\d+\S+.[a-z]{3,5}|20\S+.[a-z]{3,5}|.php.?[a-z]{2,3}=\d+\S+|Info.?id=\S+|.php.?Sid=\S+|Archive.aspx.?Id=\d+|aspx.?id=\d+|\.action.?id=\d+|id=\d+&chid=\d+', str(i.get('href')))
if Get_ID:
New_url = ID_Splicing + Get_ID[0]
if LastGetID == Get_ID[0]:
print('---------------页面未更新------------')
break
else:
Session += 1
if Session == 1:
conn = pool.connection()
cur = conn.cursor()
sql = "UPDATE dbo.TDOA_CcwNewsConfig SET LastGetId='%s' WHERE Url='%s'" % (
Get_ID[0], url)
cur.execute(sql)
print('记录%s条ID成功' % Session)
conn.commit()
cur.close()
conn.close()
# =====================================================
print(New_url)
open_url(New_url, TITLE, PUBLISHTIME, CONTENT, GovArea, ChaArea, url, FJ_Download, FJ_adress, Get_ID, ChaPlate, ConfigId, db_adress, FJ_Splicing, Url, ID_Splicing, pool, UserHeader)
else:
print('-----------------ID获取不到-----------------')
continue
except Exception as e:
Logger(e, url)
print(e)
pass
except Exception as e:
Logger(e, url)
print(e)
pass
打开详情页面并根据要求获取数据
def open_url(New_url, TITLE, PUBLISHTIME, CONTENT, GovArea, ChaArea, url, FJ_Download, FJ_adress, Get_ID, ChaPlate, ConfigId, db_adress, FJ_Splicing, Url, ID_Splicing, pool, UserHeader):
try:
chrome_options = Options()
header = choice(UserHeader)
chrome_options.add_argument(‘user-agent="%s"’ % header)
# 设置打开浏览器不加载图片
chrome_options.add_argument(’–blink-settings=imagesEnabled=false’)
# 设置浏览器不提供可视化(不弹窗)
chrome_options.add_argument(’–headless’)
# 设置禁止GPU加速
chrome_options.add_argument(’–disable-gpu’)
driver = webdriver.Chrome(executable_path=‘C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe’,chrome_options=chrome_options)
driver.set_page_load_timeout(20)
driver.get(New_url)
content = driver.page_source.encode(‘gb18030’)
time.sleep(3)
driver.quit()
soup = BeautifulSoup(content, ‘html.parser’, from_encoding=“gb18030”)
Title = get_Title(soup, TITLE, ChaArea)
PublishTime = get_PublishTime(soup, PUBLISHTIME, New_url)
Abstract = get_Abstract(soup, CONTENT)
Content = get_txt(soup, CONTENT, PublishTime, url, FJ_adress, Title)
time.sleep(2)
new_list = get_FJ(soup, url, FJ_Download, FJ_adress, PublishTime, Title, Get_ID, db_adress, FJ_Splicing, header, ID_Splicing)
time.sleep(2)
start_sql(Title, PublishTime, GovArea, ChaArea, Content, New_url, Abstract, new_list, ChaPlate, ConfigId, url, pool)
except Exception as e:
Logger(e, New_url)
pass
获取标题:
def get_Title(soup, TITLE, ChaArea):
try:
a = ‘【’ + k_v[ChaArea] + ‘】’
except:
a = ‘【’ + ‘】’
Title = a+soup.select(TITLE)[0].text.strip()
if ‘字号:’ in Title:
Title = Title.replace(‘字号:’, ‘’).strip()
print("------------标题:" + Title)
return Title
else:
print("------------标题:" + Title)
return Title
获取时间:
def get_PublishTime(soup, PUBLISHTIME, New_url):
try:
if PUBLISHTIME == ‘None’:
return ‘’
PublishTime = re.search(r’\d{4}[/:-]\d{1,2}[/:-]\d{1,2}\s\d{1,2}[/:-]\d{1,2}[/:-]\d{1,2}|\d{4}[/:-]\d{1,2}[/:-]\d{1,2}\s\d{1,2}[/:-]\d{1,2}|\d{4}[/:-]\d{1,2}[/:-]\d{1,2}|\d{4}[年]\d{1,2}[月]\d{1,2}[日]’,soup.select(PUBLISHTIME)[0].text)[0]
if PublishTime:
if ‘年’ in PublishTime:
PublishTime = PublishTime.replace(‘年’, ‘-’).replace(‘月’, ‘-’).replace(‘日’, ‘’)
print(“时间:” + PublishTime)
return PublishTime
else:
print(“时间:” + PublishTime)
return PublishTime
else:
print(‘时间获取不到’)
except Exception as e:
Logger(e, New_url)
PublishTime = New_url.split(’/’)[-1]
PublishTime = PublishTime[1:5] + ‘-’ + PublishTime[5:7] + ‘-’ + PublishTime[7:9]
print(“时间:” + PublishTime)
return PublishTime
获取摘要:
def get_Abstract(soup, CONTENT):
return ‘’
# Txt = soup.select(CONTENT)
# if Txt:
# c = []
# for i in Txt:
# c.append(i.text)
# Content = ‘\n’.join©
# if Content:
# Abstract = Content[:100].replace(’ ', ’ ‘).replace(’ ', ’ ')
# print(“摘要:”+Abstract)
# return Abstract
获取详情页面的内容:
def get_txt(soup, CONTENT, PublishTime, url, FJ_adress, Title):
try:
Txt = soup.select(CONTENT)[0]
if Txt:
c = []
for i in Txt:
Script_BQ = re.findall(’
Script_BQ3 = re.findall(’<\sscript[>]*>[<]<\s*/\sscript\s>’, str(i))
if Script_BQ3:
pass
# Script_BQ2 = re.findall(’ baidu button begin \S+ baidu button end ‘, str(i))
if Script_BQ:
pass
else:
c.append(str(i).replace(‘yes’, ‘’).replace(‘fujian_downcon’, ‘’).replace(‘Times’,’’).replace(‘New’, ‘’).replace(‘Roman’, ‘’).replace(‘Calibri’, ‘’).replace(‘margin:’, ‘’).replace(‘Cambria’, ‘’).replace(‘Corbel’, ‘’).replace(‘附件下载: ‘,’’))
Content = ‘’.join©
new_txt = Content.replace(’ ', ’ ‘).replace(’ ‘, ’ ‘).replace(’ baidu button begin ‘, ‘’).replace(’ baidu button end ‘, ‘’).replace(’ ‘, ‘’).replace(‘分页连接位置,必须’, ‘’).replace(’ ‘, ‘’)
Script_txt = re.findall(’
if len(Script_txt) == 1:
new_txt = new_txt.replace(Script_txt[0], ‘’)
if len(Script_txt) == 2:
new_txt = new_txt.replace(Script_txt[0], ‘’).replace(Script_txt[1], ‘’)
print(“标签内容:” + new_txt)
return new_txt
except:
return ‘’
获取附件并下载
def get_FJ(soup, url, FJ_Download, FJ_adress, PublishTime, Title, Get_ID, db_adress, FJ_Splicing, header, ID_Splicing):
try:
new_list = []
FUJIAN = soup.select(FJ_Download)
if FUJIAN:
FJ_url = re.findall(r’/[A-Z]\d+.docx|/[A-Z]\d+.png|/[A-Z]\d+.doc|/[A-Z]\d+.pdf|/[A-Z]\d+.xlsx|/[A-Z]\d+.xls|/[A-Z]\d+.zip|/[A-Z]\d+.rtf|/[A-Z]\d+.jpg|/[A-Z]\d+.rar|/[A-Z]\d+.tif|/[A-Z]\d+.mp4|/\d+\S+\d+.?[a-z]{3,5}|up[a-z]+\S+.?[a-z]{3,4}|/\d+\S+[a-z].?[a-z]{3,4}|\d+\S+/files/\S+.?[a-z]{3,4}|[a-z]\S+/files/\S+.?[a-z]{3,4}|.files=\d+.?[a-z]{3,4}’, str(FUJIAN))
# 对附件列表进行去重和数据过滤
bbb = set(FJ_url)
FJ_url = list(bbb)
if FJ_url:
FJ_title = soup.select(FJ_Download + ’ a’)
if FJ_title:
FJ_url = []
FJ_NEWtitle = []
for i in FJ_title:
if i.get(‘href’):
if i.get(‘href’).split(’.’)[-1] != ‘htm’:
if i.get(‘href’).split(’.’)[-1] != ‘html’:
if i.get(‘href’).split(’.’)[-1] != ‘shtml’:
if i.get(‘href’).split(’.’)[-1] != ‘jhtml’:
if i.get(‘href’).split(’.’)[-1] in [‘docx’,‘png’,‘doc’,‘pdf’,‘xlsx’,‘xls’,‘zip’,‘rtf’,‘jpg’,‘rar’,‘tif’,‘ppt’,‘mp4’]:
try:
FJ_URL = re.findall(r’/[A-Z]\d+.docx|/[A-Z]\d+.png|/[A-Z]\d+.doc|/[A-Z]\d+.pdf|/[A-Z]\d+.xlsx|/[A-Z]\d+.xls|/[A-Z]\d+.zip|/[A-Z]\d+.rtf|/[A-Z]\d+.jpg|/[A-Z]\d+.rar|/[A-Z]\d+.tif|/[A-Z]\d+.wps|/[A-Z]\d+.ppt|/[A-Z]\d+.mp4|/\d+\S+\d+.?[a-z]{3,5}.?ref=spec|/\d+\S+?[a-z]{3,4}.[a-z]{3,5}|/\d+\S+\d+.[a-z]{3,5}|uploadfile\S+ \S+.?[a-z]{3,4}|up[a-z]+\S+.?[a-z]{3,4}|/\d+\S+[a-z]{1,2}.[a-z]{3,4}|.files=\d+.?[a-z]{3,4}|\d+\S+/files/\S+.?[a-z]{3,4}|[a-z]\S+/files/\S+.?[a-z]{3,4}|\d+\S+/file/\S+’,i.get(‘href’))
if FJ_URL:
FJ_NEWtitle.append(i)
FJ_url.append(FJ_URL[0])
else:
continue
except Exception:
continue
#特殊情况处理
if i.get(‘href’).split(’?’)[-1] == ‘ref=spec’:
try:
FJ_URL = re.findall(r’/[A-Z]\d+.docx|/[A-Z]\d+.png|/[A-Z]\d+.doc|/[A-Z]\d+.pdf|/[A-Z]\d+.xlsx|/[A-Z]\d+.xls|/[A-Z]\d+.zip|/[A-Z]\d+.rtf|/[A-Z]\d+.jpg|/[A-Z]\d+.rar|/[A-Z]\d+.tif|/[A-Z]\d+.wps|/[A-Z]\d+.mp4|/[A-Z]\d+.ppt|/\d+\S+\d+.?[a-z]{3,5}.?ref=spec|/\d+\S+?[a-z]{3,4}.?[a-z]{3,5}|/\d+\S+\d+.?[a-z]{3,5}|uploadfile\S+ \S+.?[a-z]{3,4}|up[a-z]+\S+.?[a-z]{3,4}|/\d+\S+[a-z].?[a-z]{3,4}|.files=\d+.?[a-z]{3,4}|\d+\S+/files/\S+.?[a-z]{3,4}|[a-z]\S+/files/\S+.?[a-z]{3,4}|\d+\S+/file/\S+’,i.get(‘href’))
if FJ_URL:
FJ_NEWtitle.append(i)
FJ_url.append(FJ_URL[0])
else:
continue
except Exception:
continue
# 对获得的附件url的id进行过滤去重
news_ids = []
for id in FJ_url:
if id not in news_ids:
news_ids.append(id)
FJ_title = FJ_NEWtitle
# 对附件的完整url进行拼接
for x, y in zip(news_ids, FJ_title):
if FJ_Splicing:
FJ_url = FJ_Splicing + x
print(FJ_url)
else:
if x[0] != ‘/’:
x = ‘/’ + x
FJ_url = ID_Splicing + Get_ID[0][:6] + x
print(FJ_url)
# 对下载的附件路径和存入数据库的附件路径进行处理
FJ_houzhui = re.findall(r’docx|png|doc|pdf|xlsx|xls|zip|rtf|jpg|rar|tif|wps|XLS|PDF|ppt|mp4’, x.split(’.’)[-1])
filename = FJ_adress + y.text.split(’】’)[-1].replace(’\n’, ‘’).replace(’\r’,’’).replace(’\u3000’,’’).strip() + ‘.’ + FJ_houzhui[0]
print(filename)
sql_filename = db_adress + y.text.split(’】’)[-1].replace(’\n’, ‘’).replace(’\r’,’’).replace(’\u3000’,’’).strip() + ‘.’ + FJ_houzhui[0]
try:
new_list.append(sql_filename)
r = requests.get(FJ_url, headers={‘User-Agent’: UserAgent})
with open(filename, “wb”) as code:
code.write(r.content)
code.close()
except:
continue
return new_list
except Exception as e:
Logger(e, url)
print(e)
pass
数据接收并存入sql sever 数据库:
def start_sql(Title, PublishTime, GovArea, ChaArea, Content, New_url, Abstract, new_list, ChaPlate, ConfigId, url, pool):
FJ_filename = ‘,’.join(new_list)
Now_time = str(datetime.datetime.now())[:-3]
conn = pool.connection()
cur = conn.cursor()
sql_UPTIME = “UPDATE dbo.TDOA_CcwNewsConfig SET CreateDateTime=’%s’,UpdateDateTime=’%s’ WHERE Url=’%s’” % (Now_time, Now_time, url)
try:
sql = "INSERT INTO dbo.TDOA_CcwCrawlerNews (MainID,Title,PublishTime,GovArea,ChaArea,[Content],Info,OriginalUrl,CreateBy,CreateByName,CreateDateTime,UpdateBy,UpdateByName,UpdateDateTime,Attachment,ChaPlate,ConfigId) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
# 每个值的集合为一个tuple,整个参数集组成一个tuple,或者list '%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s'
param = [(str(uuid.uuid4()), Title, PublishTime, GovArea, ChaArea, Content, Abstract, New_url, 'Crawler', '系统爬虫', Now_time, 'Crawler', '系统爬虫', Now_time, FJ_filename, ChaPlate, ConfigId)]
# 使用executemany方法来批量的插入数据!
cur.executemany(sql, param)
# cur.execute(sql)
cur.execute(sql_UPTIME)
conn.commit()
cur.close()
conn.close()
except Exception as e:
Logger(e, New_url)
print(e)
运行报错并写入日志文件
def Logger(e, d):
with open(’./all.log’, ‘a’, encoding=‘utf-8’) as LOG:
shijian = datetime.datetime.now()
LOG.write(str(shijian)[:-7] + ‘(网址为:’ + d + ‘)’ + ‘-’ + '报错内容: ’ + str(e) + ‘\n’)
LOG.close()
if name==‘main’:
# 当程序开始时,在日志文件载入记录
with open(’./all.log’, ‘a’, encoding=‘utf-8’) as LOG:
shijian = datetime.datetime.now()
LOG.write(str(shijian)[:-7] + ‘-’ + ‘运行开始’ + ‘\n’)
LOG.close()
running()