TensorFlow word2vec_basic 代码分析
将字母向量化(即 word embedding)是NLP的基础,在TensorFlow中有一个简单的实现即word2vec(这篇文章主要关注他的基本实现,demo在这个目录下:tensorflow/examples/tutorials/word2vec/word2vec_basic.py)。关于word2vec的介绍非常多理论也一堆一堆的,下面是本文参考的几篇主要的理论文章:
http://www.jeyzhang.com/tensorflow-learning-notes-3.html
https://liusida.github.io/2016/11/14/study-embeddings/
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/tutorials/word2vec/word2vec_basic.py
本文希望抛开理论,三言两语的把word2vec用人话说清楚。
一些基本概念不在复述,这里主要总结几个结论:
1.word2vec的学习过程目标是把每个单词映射成一个向量。
2.我们希望这些向量能满足一些基本规律,比如如果两个单词的含义是相近的,那么他们对应的向量的余弦相似度尽可能小。
3.在一个上下文环境中如果单词a出现过多次,单词b也出现过多次,那么a和b极有可能是同个类型的或者意思相近的词。
4.在这里上下文主要指一个单词周围的其他单词。
5.word2vec使用的是skip-gram模型,skip-gram模型是从目标词来预测上下文信息。
所以这里word2vec的模型其实很简单,取其中一个词,作为目标词,当输入目标词的时候,那么理论上就可以输出他的上下文信息。但是它的上下文信息很多,一个目标词周围有很多的词,目标词对应其中任何一个词都是合理的输出。所以将目标词与周围的N个词组成N组训练样本,分别作为输入输出进行训练。
举个例子理解起来就很简单了,一个句子: Y X A B C D E X Y,假设将单词左右两边的两个单词以内的词作为当前词的上下文,当将C作为输入(这时A,B,D,E都是他的上下文),那么他的输出是什么呢, 输出可以是A ,B , D,E中的任何一个,所以(C,E),(C,B)(C,D)(C,A),都可以作为训练样本,一般随机选其中的几种进行训练,比如我们只选(C,E),这是C是输入,E是输出(也就是label,机器学习,当给数据打了标签就好办了)。
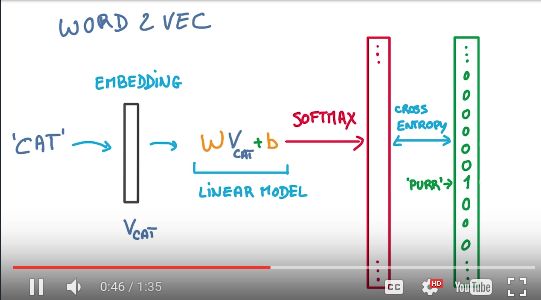
到现在这个模型应该已经非常清晰了,他的输入是一个单词(应该是一个单词word embedding后对应的数字化后的向量),他的输出也是一个单词,不过输出这里的单词表示方式跟输入不太一样,采用的是One-hot Representation,为什么输入使用word embedding的方式而输出使用One-hot Representation的方式,我的理解是word embedding的方式表示一个单词开始时是有参数的,不是真实的结果,没法用来作为输出去优化模型。
所以对于一个总共有5000个单词的词库,进行word embedding,假设词向量是128维的,那么这个模型的输入是一个1x128的向量,输出是一个1x5000的向量。
 ]
]
最后我们把代码贴出来看下:
# Copyright 2015 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Basic word2vec example."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import collections
import math
import os
import random
import zipfile
import numpy as np
from six.moves import urllib
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
# Step 1: Download the data.
url = 'http://mattmahoney.net/dc/'
def maybe_download(filename, expected_bytes):
"""Download a file if not present, and make sure it's the right size."""
if not os.path.exists(filename):
filename, _ = urllib.request.urlretrieve(url + filename, filename)
statinfo = os.stat(filename)
if statinfo.st_size == expected_bytes:
print('Found and verified', filename)
else:
print(statinfo.st_size)
raise Exception(
'Failed to verify ' + filename + '. Can you get to it with a browser?')
return filename
filename = maybe_download('text8.zip', 31344016)
# Read the data into a list of strings.
def read_data(filename):
"""Extract the first file enclosed in a zip file as a list of words."""
with zipfile.ZipFile(filename) as f:
data = tf.compat.as_str(f.read(f.namelist()[0])).split()
return data
vocabulary = read_data(filename)
print('Data size', len(vocabulary))
# Step 2: Build the dictionary and replace rare words with UNK token.
vocabulary_size = 50000
def build_dataset(words, n_words):
"""Process raw inputs into a dataset."""
count = [['UNK', -1]]
count.extend(collections.Counter(words).most_common(n_words - 1))
dictionary = dict()
for word, _ in count:
dictionary[word] = len(dictionary)
data = list()
unk_count = 0
for word in words:
if word in dictionary:
index = dictionary[word]
else:
index = 0 # dictionary['UNK']
unk_count += 1
data.append(index)
count[0][1] = unk_count
reversed_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
return data, count, dictionary, reversed_dictionary
data, count, dictionary, reverse_dictionary = build_dataset(vocabulary,
vocabulary_size)
del vocabulary # Hint to reduce memory.
print('Most common words (+UNK)', count[:5])
print('Sample data', data[:10], [reverse_dictionary[i] for i in data[:10]])
data_index = 0
# Step 3: Function to generate a training batch for the skip-gram model.
def generate_batch(batch_size, num_skips, skip_window):
global data_index
assert batch_size % num_skips == 0
assert num_skips <= 2 * skip_window
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * skip_window + 1 # [ skip_window target skip_window ]
buffer = collections.deque(maxlen=span)
if data_index + span > len(data):
data_index = 0
buffer.extend(data[data_index:data_index + span])
data_index += span
for i in range(batch_size // num_skips):
target = skip_window # target label at the center of the buffer
targets_to_avoid = [skip_window]
for j in range(num_skips):
while target in targets_to_avoid:
target = random.randint(0, span - 1)
targets_to_avoid.append(target)
batch[i * num_skips + j] = buffer[skip_window]
labels[i * num_skips + j, 0] = buffer[target]
if data_index == len(data):
buffer[:] = data[:span]
data_index = span
else:
buffer.append(data[data_index])
data_index += 1
# Backtrack a little bit to avoid skipping words in the end of a batch
data_index = (data_index + len(data) - span) % len(data)
return batch, labels
batch, labels = generate_batch(batch_size=8, num_skips=2, skip_window=1)
for i in range(8):
print(batch[i], reverse_dictionary[batch[i]],
'->', labels[i, 0], reverse_dictionary[labels[i, 0]])
# Step 4: Build and train a skip-gram model.
batch_size = 128
embedding_size = 128 # Dimension of the embedding vector.
skip_window = 1 # How many words to consider left and right.
num_skips = 2 # How many times to reuse an input to generate a label.
# We pick a random validation set to sample nearest neighbors. Here we limit the
# validation samples to the words that have a low numeric ID, which by
# construction are also the most frequent.
valid_size = 16 # Random set of words to evaluate similarity on.
valid_window = 100 # Only pick dev samples in the head of the distribution.
valid_examples = np.random.choice(valid_window, valid_size, replace=False)
num_sampled = 64 # Number of negative examples to sample.
graph = tf.Graph()
with graph.as_default():
# Input data.
train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
# Ops and variables pinned to the CPU because of missing GPU implementation
with tf.device('/cpu:0'):
# Look up embeddings for inputs.
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
# Construct the variables for the NCE loss
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
# Compute the average NCE loss for the batch.
# tf.nce_loss automatically draws a new sample of the negative labels each
# time we evaluate the loss.
loss = tf.reduce_mean(
tf.nn.nce_loss(weights=nce_weights,
biases=nce_biases,
labels=train_labels,
inputs=embed,
num_sampled=num_sampled,
num_classes=vocabulary_size))
# Construct the SGD optimizer using a learning rate of 1.0.
optimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss)
# Compute the cosine similarity between minibatch examples and all embeddings.
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / norm
valid_embeddings = tf.nn.embedding_lookup(
normalized_embeddings, valid_dataset)
similarity = tf.matmul(
valid_embeddings, normalized_embeddings, transpose_b=True)
# Add variable initializer.
init = tf.global_variables_initializer()
# Step 5: Begin training.
num_steps = 100001
with tf.Session(graph=graph) as session:
# We must initialize all variables before we use them.
init.run()
print('Initialized')
average_loss = 0
for step in xrange(num_steps):
batch_inputs, batch_labels = generate_batch(
batch_size, num_skips, skip_window)
feed_dict = {train_inputs: batch_inputs, train_labels: batch_labels}
# We perform one update step by evaluating the optimizer op (including it
# in the list of returned values for session.run()
_, loss_val = session.run([optimizer, loss], feed_dict=feed_dict)
average_loss += loss_val
if step % 2000 == 0:
if step > 0:
average_loss /= 2000
# The average loss is an estimate of the loss over the last 2000 batches.
print('Average loss at step ', step, ': ', average_loss)
average_loss = 0
# Note that this is expensive (~20% slowdown if computed every 500 steps)
if step % 10000 == 0:
sim = similarity.eval()
for i in xrange(valid_size):
valid_word = reverse_dictionary[valid_examples[i]]
top_k = 8 # number of nearest neighbors
nearest = (-sim[i, :]).argsort()[1:top_k + 1]
log_str = 'Nearest to %s:' % valid_word
for k in xrange(top_k):
close_word = reverse_dictionary[nearest[k]]
log_str = '%s %s,' % (log_str, close_word)
print(log_str)
final_embeddings = normalized_embeddings.eval()
# Step 6: Visualize the embeddings.
def plot_with_labels(low_dim_embs, labels, filename='tsne.png'):
assert low_dim_embs.shape[0] >= len(labels), 'More labels than embeddings'
plt.figure(figsize=(18, 18)) # in inches
for i, label in enumerate(labels):
x, y = low_dim_embs[i, :]
plt.scatter(x, y)
plt.annotate(label,
xy=(x, y),
xytext=(5, 2),
textcoords='offset points',
ha='right',
va='bottom')
plt.savefig(filename)
try:
# pylint: disable=g-import-not-at-top
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
plot_only = 500
low_dim_embs = tsne.fit_transform(final_embeddings[:plot_only, :])
labels = [reverse_dictionary[i] for i in xrange(plot_only)]
plot_with_labels(low_dim_embs, labels)
except ImportError:
print('Please install sklearn, matplotlib, and scipy to show embeddings.')其他的就不多说,我想重点分析一下 generate_batch 这个函数。
# Step 3: Function to generate a training batch for the skip-gram model.
#从文本总体的第二个单词开始,每个单词依次作为输入,它的输出可以是上下文范围内的单词中的任何一个单词。一般不是取全部而是随机取其中的几组,以增加随机性。
#batch_size 就是每次训练用多少数据,skip_window是确定取一个词周边多远的词来训练,num_skips对于一个输入数据,产生多少个标签数据。所以skip_window决定上下文的长度,就是当前词的周围多少个词内的词被视为它的上下文的范围内,然后从这上下文范围内的词中随机取num_skips个与输入组合成num_skips组训练数据
def generate_batch(batch_size, num_skips, skip_window):
global data_index
assert batch_size % num_skips == 0
assert num_skips <= 2 * skip_window #保证num_skips不会超过当前输入的的上下文的总个数
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * skip_window + 1 # [ skip_window target skip_window ]
#这个很重要,最大长度是span,后面如果数据超过这个长度,前面的会被挤掉,这样使得buffer里面永远是data_index周围的span歌数据,
#而buffer的第skip_window个数据永远是当前处理循环里的输入数据
buffer = collections.deque(maxlen=span)
if data_index + span > len(data):
data_index = 0
buffer.extend(data[data_index:data_index + span])
data_index += span
for i in range(batch_size // num_skips):
target = skip_window # target label at the center of the buffer
targets_to_avoid = [skip_window] #自己肯定要排除掉,不能自己作为自己的上下文
for j in range(num_skips):
while target in targets_to_avoid:
target = random.randint(0, span - 1) #随机取一个,增强随机性,减少训练时进入局部最优解
targets_to_avoid.append(target)
batch[i * num_skips + j] = buffer[skip_window] #这里保存的是训练的输入序列
labels[i * num_skips + j, 0] = buffer[target] #这里保存的是训练时的输出序列,也就是标签
if data_index == len(data): #超长时回到开始
buffer[:] = data[:span]
data_index = span
else:
buffer.append(data[data_index]) #append时会把queue的开始的几个挤掉
data_index += 1
# Backtrack a little bit to avoid skipping words in the end of a batch
data_index = (data_index + len(data) - span) % len(data)
return batch, labels