CNN论文-YOLOv1
You Only Look Once: Unified, Real-Time Object Detection
I. Motivation
之前的目标检测如R-CNN系列模型一般分为3个步骤:
(1) 通过region proposal methods产生bbox;
(2) 通过分类器对这些bbox进行分类;
(3) post-processing:refine bbox, eliminate duplicate detections, and rescore the box based on other objects in the scene
复杂的pipeline,加上模型的不同部分需要分开单独训练,使得模型的优化速度很慢。YOLO提出的解决方法是,将目标检测视作回归任务,bbox坐标及分类结果都通过回归求得。如下图所示,CNN既预测bbox坐标,又预测bbox属于某一类的概率。

II.YOLO具体细节
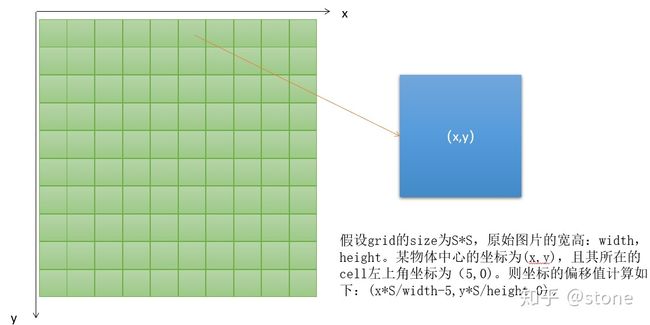
YOLO将输入图像划分为S*S的栅格,每个栅格负责检测中心落在该栅格中的物体,每一个栅格预测B个bounding boxes,以及这些bounding boxes的confidence scores。这个 confidence scores反映了模型对于这个栅格的预测:该栅格是否含有物体,以及这个box的坐标预测的有多准,即 confidence=Pr(Object)*IOU pred truth \text{confidence=Pr(Object)*IOU}_{\text {pred}}^{\text {truth}} confidence=Pr(Object)*IOUpredtruth . 如果这个栅格中不存在目标,则confidence score应该为0;否则的话,confidence score为predicted bbox与 ground truth box之间的 IoU。
YOLO对每个bounding box有5个预测值:x, y, w, h,和confidence:
坐标x,y代表了预测的bounding box的中心与栅格边界的相对值。
坐标w,h代表了预测的bounding box的width、height相对于整幅图像width,height的比例。
confidence就是预测的bounding box和ground truth box的IOU值。

每一个栅格还要预测C个 conditional class probability(条件类别概率): Pr(Class i |Object) \text {Pr(Class}_i\text{|Object)} Pr(Classi|Object)。即在一个栅格包含一个Object的前提下,它属于某个类的概率。我们只为每个栅格预测一组(C个)类概率,而不考虑框B的数量。
注意:conditional class probability信息是针对每个网格的,以及confidence信息是针对每个bbox的。
在测试阶段,将每个栅格的conditional class probabilities与每个bbox的 confidence相乘:
P r ( C l a s s i ∣ O b j e c t ) ∗ P r ( O b j e c t ) ∗ I O U p r e d t r u t h = P r ( C l a s s i ) ∗ I O U p r e d t r u t h Pr(Class_i | Object)*Pr(Object)*IOU_{pred}^{truth}=Pr(Class_i)*IOU_{pred}^{truth} Pr(Classi∣Object)∗Pr(Object)∗IOUpredtruth=Pr(Classi)∗IOUpredtruth
这样可得到每个bbox的具体类别的confidence score,这个score既衡量了某个类出现在这个box中的概率,又衡量了predicted box的准确度(IoU)。
论文使用的 S=7,即将一张图像分为7×7=49个栅格每一个栅格预测B=2个boxes(每个box有 x,y,w,h,confidence,5个预测值),同时C=20(PASCAL数据集中有20个类别)。因此,最后的prediction是7×7×30的Tensor, 即 S ∗ S ∗ ( B ∗ 5 + C ) S * S * ( B * 5 + C) S∗S∗(B∗5+C) 。

III.YOLO网络设计 包括24个卷积层和2个全连接层
YOLO在减少参数方面受到了GoogLeNet分类网络结构的启发。不同的是,YOLO未使用inception module,而是使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+3x3卷积层简单替代。

II.YOLO的训练

关于loss,需要特别注意的是需要计算loss的部分。具体地说:有物体中心落入的grid,需要计算分类loss,两个predictor都要计算confidence loss,预测的bounding box与ground truth IOU比较大的那个predictor需要计算xywh loss。特别注意:没有物体中心落入的grid,只需要计算confidence loss。
另外,每一项loss的计算都是L2 loss,即使是分类问题也是。所以说yolo是把分类问题转为了回归问题。论文中设置 λ coord = 5 , λ noobj = 0.5 \lambda_{\text {coord}}=5, \lambda_{\text {noobj}}=0.5 λcoord=5,λnoobj=0.5.
II.YOLO的优缺点
1. 优点:
(1) YOLO检测物体非常快:因为没有复杂的检测流程,只需要将图像输入到神经网络就可以得到检测结果,YOLO可以非常快的完成物体检测任务。标准版本的YOLO在Titan X 的 GPU 上能达到45 FPS。更快的Fast YOLO检测速度可以达到155 FPS。而且,YOLO的mAP是之前其他实时物体检测系统的两倍以上。
(2) YOLO可以很好的避免背景错误,减少false positives:不像其他物体检测系统使用了滑窗或region proposal,分类器只能得到图像的局部信息。YOLO在训练和测试时都能够看到一整张图像的信息,因此YOLO在检测物体时能很好的利用上下文信息,从而不容易在背景上预测出错误的物体信息。和Fast-R-CNN相比,YOLO的背景错误不到Fast-R-CNN的一半。
(3) YOLO可以学到物体的泛化特征:当YOLO在自然图像上做训练,在艺术作品上做测试时,YOLO表现的性能比DPM、R-CNN等之前的物体检测系统要好很多。因为YOLO可以学习到高度泛化的特征,从而迁移到其他领域。
2.缺点:
(1) 由于YOLO在bbox预测时有很强的spatial constraints(每个grid只预测两个bbox,只能输出一个目标预测), YOLO对密集的小物体的检测效果不好。
(2) 由于YOLO从训练集中学习如何预测bbox,在遇到新的、不常见的尺寸比例的目标时,泛化效果就不太好。另外,由于模型中的多个下采样层,YOLO在预测bbox时使用的特征也是较为粗糙的(coarse features) 。
(3) 损失函数对大的bbox和小的bbox产生的误差没有做区分,但同样大小的误差对尺寸小的bbox的IOU会有更大的影响。YOLO的误差主要来自与定位误差(incorrect localizations)。
我的一些理解:
(1) 为什么一个grid要预测多个bbox?原论文里是这样解释的:
YOLO predicts multiple bounding boxes per grid cell. At training time we only want one bounding box predictor to be responsible for each object. We assign one predictor to be “responsible” for predicting an object based on which prediction has the highest current IOU with the ground truth. This leads to specialization between the bounding box predictors. Each predictor gets better at predicting certain sizes, aspect ratios, or classes of object, improving overall recall.
参考:
(1)YOLOv1论文理解
(2)你真的读懂yolo了吗? - stone的文章 - 知乎
(3)[【Darknet】【yolo v2】训练自己数据集的一些心得----VOC格式]
(https://blog.csdn.net/renhanchi/article/details/71077830)
(4)目标检测:YOLOv3: 训练自己的数据
(5)【YOLO学习】使用YOLO v2训练自己的数据
(6)yolo系列之yolo v3【深度解析】