Professional CUDA C Programing
代码下载:http://www.wrox.com/WileyCDA/
Warp资源分配
➤ 程序计数器
➤寄存器
➤ 共享内存
每个warp的上下文都是全部保留在SM上的,所以warp之间的切换没有什么消耗。每个SM上的寄存器和共享内存分配给线程块,根据寄存器的多上和共享存储器的大小可以决定同时驻留在一个SM上的warp数目和线程块数目。
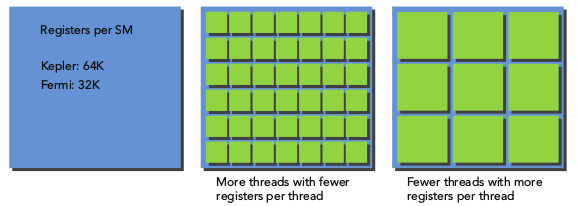
一个SM上同时驻留的线程越多,则每个线程占用的寄存器数量越少。
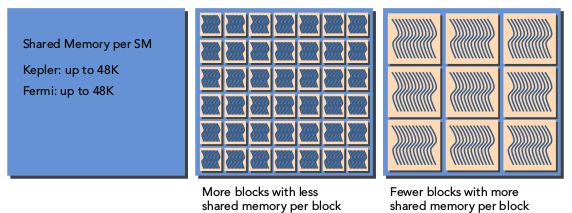
一个SM上驻留的线程块越多,每个线程块占用的共享显存越少。
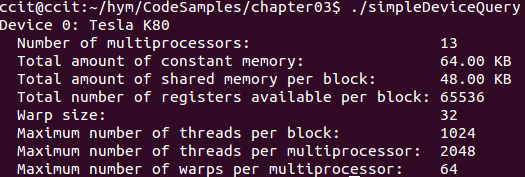
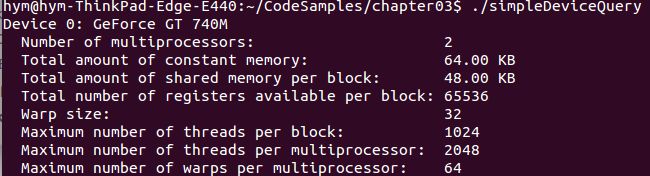
查看GPU资源的一些限制信息:一个线程块中最多1000个线程,GT740只有2个SM,但是Tesla K80有13个SM。
Active Warp
当计算资源分配给了该线程块时,该线程块叫做active block,其中包含的warps叫做active warps。active waps分为以下3类:
➤ Selected warp:warp调度器选中的warp,正在执行的warp。
➤ Stalled warp:还没有准备好执行的warp
➤ Eligible warp:已经准备好执行,但是还没有执行的warp。(准备好的限制条件:1.32个CUDA core可以用来执行;2.当前指令的所有参数都准备就绪)
延迟隐藏Latency Hiding
GPU设计成处理大量轻量的并发的线程,最大化实现吞吐率。
指令分为两类:
➤ 算术类指令:10-20个时钟周期
➤ 访存类指令:400-800个时钟周期访问global memory
????没有看懂
Number of Required Warps = Latency × Throughput
Bandwidth VS hroughput:带宽一般是理论上的峰值,吞吐量一般是实际达到的值。带宽一般指单位时间内数据的传输多少,吞吐量一般指单位时间内完成的某种操作或计算,比如说单位时间内完成的指令次数。
Occupancy
每个SM:occupancy = active warps/maximum warps
CUDA Toolkit中有一个帮助用户确定grid和block大小的工具:/usr/local/cuda-8.0/tools
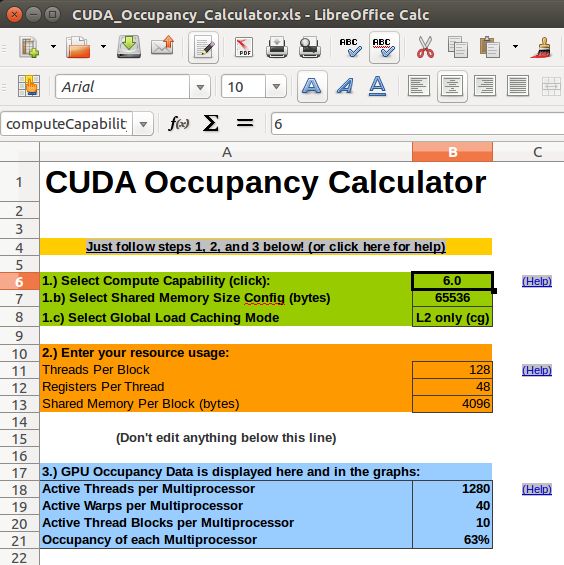
➤小线程块:每个块的线程太少导致在所有硬件资源完全利用之前,已经达到了每个SM最多的warps。比如一个线程块只有10个thread,那么一个线程块就要占用一个warp。
➤大线程块:每个块太多的线程导致每个线程可以利用SM的资源更少。
选择策略:根据kernel的计算量调整block的size,并进行多次实验发现最优的grid和block的设置。
➤每个block中含有的thread是warpSize的整数倍数。
➤避免一个block太少的thread,一个block最少128或256个线程。
➤尽量使block的数目大于GPU的SM的数目。
同步Synchronization
屏障同步是许多并行编程语言中常见的原语。 在CUDA的同步可以在两个层面上执行:
➤系统级别:等待主机和设备上的所有工作完成。
➤块级别:等待在设备上的线程块中的所有线程到达执行中的同一点(同步点)。
由于许多CUDA API调用和所有内核启动都是与主机异步的,
cudaDeviceSynchronize可用于阻止主机应用程序,直到所有CUDA操作(copies,内核等)已经完成:
cudaError_t cudaDeviceSynchronize(void);
__device__ void __syncthreads(void);
同一个block中threads要注意避免资源竞争,不同的warps的执行顺序是随机的,多个thread访问同一个变量要注意read-write,write-read等问题,避免读脏数据等。不同的block的执行顺序是随机的。
可扩展性Scalability
可扩展:当计算量增大时可以通过增加CUDA core来解决。
参考在不同数量的计算核心上执行相同应用程序代码的能力
作为透明的可扩展性。 透明可扩展的平台拓宽了现有用例
应用程序,并减轻开发人员的负担,因为它们可以避免对新的更改或不同的硬件。 可扩展性比效率更重要。 一个可扩展但效率低的系统可以通过简单地添加硬件核心来处理更大的工作负载。 效率很高但不可扩展系统可能快速达到可实现性能的上限。
Checking Active Warps with nvprof
代码来源:http://www.wrox.com/WileyCDA/
第三章sumMatrix.cu
//矩阵大小16384*16384
// invoke kernel at host side
int dimx = 32;
int dimy = 32;
if(argc > 2)
{
dimx = atoi(argv[1]);
dimy = atoi(argv[2]);
}
dim3 block(dimx, dimy);
dim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y);
// grid 2D block 2D
__global__ void sumMatrixOnGPU2D(float *A, float *B, float *C, int NX, int NY)
{
unsigned int ix = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int iy = blockIdx.y * blockDim.y + threadIdx.y;
unsigned int idx = iy * NX + ix;
if (ix < NX && iy < NY)
{
C[idx] = A[idx] + B[idx];
}
}
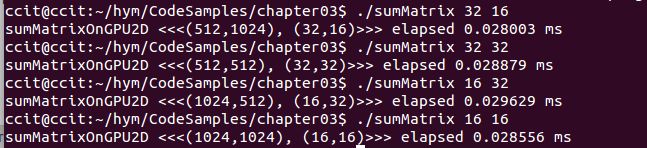
$ nvprof --metrics achieved_occupancy ./sumMatrix 32 32
32 32: Achieved Occupancy 0.758286
32 16: Achieved Occupancy 0.777452
16 32: Achieved Occupancy 0.783850
16 32: Achieved Occupancy 0.810251
$ nvprof --metrics gld_throughput ./sumMatrix 32 32
32 32: Global Load Throughput 69.013GB/s
32 16: Global Load Throughput 71.597GB/s
16 32: Global Load Throughput 67.425GB/s
16 32:Global Load Throughput 70.240GB/s
$ nvprof --metrics gld_efficiency ./sumMatrix 32 32