Pytorch----搭建网络
面向对象编程
面向对象编程——类class和对象object
- class是一种类型(Type),object是类的实例(Instance)
- 每一个类方法都必须在参数列表开头有一个固定参数self,当调用该方法时python会自动加上self这个参数。因此如果方法没有参数,也必须加上self
- init方法:
__init__方法会在对象被实例化时自动运行(初始化)
继承:
- 要想使用继承,在定义类时我们需要在类后面跟一个包含基类名称的元组。
- 如果子类中定义了
__init__方法,则基类中的__init__方法将不会被自动调用,需要手动调用,此时需要显示调用self;相反,如果子类中未定义__init__方法,则子类的__init__方法将被自动调用。
class Student(SchoolMember):
'''代表一位学生。'''
def __init__(self, name, age, marks):
SchoolMember.__init__(self, name, age)
- 在子类中调用父方法,都需要显式调用self
- super(),先简单认为成继承父类
super(子类, self).父类方法(参数),相当于父类.方法(self, 参数)
类和对象
在面向对象编程中,理解和认出类和对象十分重要
程序中有很多类的结构,一般都要建立该类的对象。例如在LeNet项目中,LeNet5是一个class,在main.py中有net = LeNet5(),即是创建了LeNet5的对象net。
面向对象编程并不是全部由类和对象组建程序的,也有函数,和普通变量
- 变量:有普通数值型变量和Tensor,普通型例如train_loss,大部分都是Tensor型变量
- 函数:例如
torch.max(output),可以写作output.max(),这是函数的应用
总结
class ConvReLU(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=0):
super(ConvReLU, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding)
def forward(self, x):
x = self.conv(x)
x = F.relu(x)
return x解释:
- 定义了
ConvReLU()类,继承了nn.Module父类。 - 定义了
__init()__方法,在实例化ConvReLU()类时自动调用__init()__方法。
2.1 输入参数除了必须有的self,还有要想实例化一个{ConvReLU()}的对象需要的参数
2.2 因为子类定义了__init()__方法,父类的__init()__方法不再自动执行,需要显式执行,nn.Module父类的__init()__方法不需要输入参数,所以super调用不需要输入参数
2.3 定义了对象变量self.conv,属性是{nn.Conv2d()}对象,实际上self.conv是{nn.Conv2d()}类的实例化,实例化时需要参数。 - 定义了
forward()方法,对输入进行操作
3.1 对数据操作需要函数,第一行x = self.conv(x)实际上为x = self.conv.forward(x),调用了nn.Conv2d()的forward()函数,由于大家都继承了nn.Module父类,根据nn.Module的使用方法,.forward()不写,直接写object(input)
3.2 第二行x = F.relu(x)直接调用了函数,对输入进行操作
笔记:nn.ReLU与F.ReLU的区别
import torch.nn as nn
import torch.nn.functional as F
import torch.nn as nn
class AlexNet_1(nn.Module):
def __init__(self, num_classes=n):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
)
def forward(self, x):
x = self.features(x)
class AlexNet_2(nn.Module):
def __init__(self, num_classes=n):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
)
def forward(self, x):
x = self.features(x)
x = F.ReLU(x)在如上网络中,AlexNet_1与AlexNet_2实现的结果是一致的,但是可以看到将ReLU层添加到网络有两种不同的实现,即nn.ReLU和F.ReLU两种实现方法。
其中nn.ReLU作为一个层结构,必须添加到nn.Module容器中才能使用,而F.ReLU则作为一个函数调用,看上去作为一个函数调用更方便更简洁。具体使用哪种方式,取决于编程风格。在PyTorch中,nn.X都有对应的函数版本F.X,但是并不是所有的F.X均可以用于forward或其它代码段中,因为当网络模型训练完毕时,在存储model时,在forward中的F.X函数中的参数是无法保存的。也就是说,在forward中,使用的F.X函数一般均没有状态参数,比如F.ReLU,F.avg_pool2d等,均没有参数,它们可以用在任何代码片段中。
循环与迭代
batchsize:在深度学习中,一般采用SGD训练,即每次训练在训练集中取batchsize个样本训练;
iteration:中文翻译为迭代,1个iteration等于使用batchsize个样本训练一次;
一个迭代 = 一个正向通过+一个反向通过
epoch:迭代次数,1个epoch等于使用训练集中的全部样本训练一次;
一个epoch = 所有训练样本的一个正向传递和一个反向传递
举个例子,训练集有1000个样本,batchsize=10,那么:
训练完整个样本集需要:
100次iteration,1次epoch。
torch.nn.XX VS torch.nn.functional.XX
既有torch.nn.Conv2d,又有torch.nn.Functional.Conv2d,区别在于:
nn.Module实现的layer是由class Layer(nn.Module)定义的特殊类,会自动提取可学习参数nn.Parameter;nn.functional中的函数更像是纯函数,由def function(input)定义
- nn.Conv2d是一个类,把卷积当作一个层时使用
- F.conv2d()是一个函数,把卷积当作一个运算函数时使用
- nn.Conv2d的forward()函数实现是用F.conv2d()实现的。
class Conv2d(_ConvNd):
def forward(self, input):
return F.conv2d(input, self.weight, self.bias, self.stride,
self.padding, self.dilation, self.groups)
在调用Conv2d()操作时执行forward方法,可以看到真正进行操作的还是F.conv2d()函数
import 和from... import
- 可以import的单位是
package和module
.py文件是一个Module
可以from...import...的单位是package,module和class/function
- 导入文件将导入所有的class,用某个class时需要
package.class
导入类可以直接使用该类
例如:torchvisonpakage有3个package和一个module

import torchvision
导入class
在导入MNIST数据集时需要用class MNIST,这个class包含于torchvison.datasets.mnist文件中,因此正确引用的方式有:from torchvision.datasets.mnist import MNIST,使用时直接用MNISTimport torchvision.datasets.mnist as mnist,使用时用mnist.MNIST
导入module
from torchvision import datasetsimport torchvion.datasets as datasets
net中input的维度
应有四个维度:batch_size, channels, size_len, size_width,如果读取单张图片没有batch_size维度,需要手动添加image = image.view(1, image.size(0), image.size(1), image.size(2))
技巧 - 建一个class ConvReLU()
把Conv2d和ReLU()合起来做
class ConvReLu(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super(ConvReLu, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding)
def forward(self, x):
x = self.conv(x)
x = F.relu(x)
return x
使用方法:
class Layer1and2(nn.Module):
def __init__(self):
super(Layer1and2, self).__init__()
self.op = nn.Sequential(
ConvReLu(3, 64, 7, 2, 2),
nn.MaxPool2d(3, 2),
nn.BatchNorm2d(64),
ConvReLu(64, 64, 1, 1),
ConvReLu(64, 192, 3, 1, 1),
nn.BatchNorm2d(192),
nn.MaxPool2d(3, 2)
)
def forward(self, x):
x = self.op(x)
return x
把ConvReLU当作一个整体来用
好处
- 省事,提高代码结构化
- 在调试的时候可以看到卷积之后的效果,只有
forward()中的操作可以调试跟踪,在__init()__中nn.Sequential中的操作是无法跟踪的。
技巧 - forward函数中尽量别把许多步骤合成一个Sequential
否则没办法调试跟踪每一步之后的结果。
技巧 -- nn.Sequential()最后一个元素别加逗号
否则最后一个元素将被忽略。
假设构建一个网络模型如下:
卷积层--》Relu层--》池化层--》全连接层--》Relu层--》全连接层
首先导入几种方法用到的包:
| 1 2 3 |
|
第一种方法:
|
|
第二种方法:
|
|
第三种方法:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
第四种方法:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
torch.nn.Module类的简介
https://blog.csdn.net/qq_27825451/article/details/90550890
初始化神经网络的参数
对神经网络的初始化往往放在模型的__init__()函数中,如下所示:
class Net(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(Net, self).__init__()
***
*** #定义自己的网络层
***
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
***
*** #定义后续的函数
***也可以采取另一种方式:
定义一个权重初始化函数,如下:
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv2d') != -1:
init.xavier_normal_(m.weight.data)
init.constant_(m.bias.data, 0.0)
elif classname.find('Linear') != -1:
init.xavier_normal_(m.weight.data)
init.constant_(m.bias.data, 0.0)
在模型声明时,调用初始化函数,初始化神经网络参数:
model = Net(*****)
model.apply(weights_init)pytorch api torch.nn.Linear
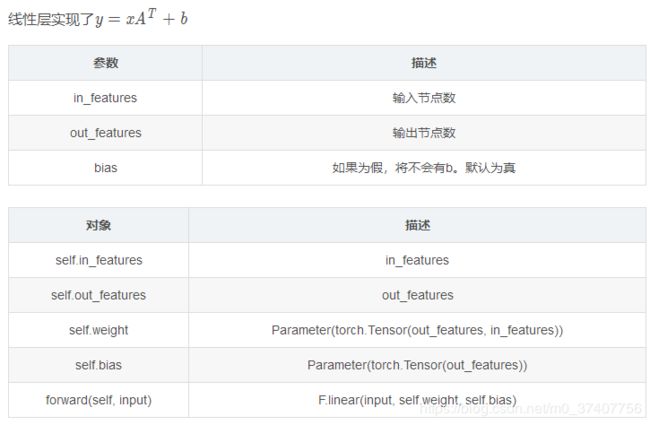
pytroch resnet构建过程理解
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=0, ceil_mode=True) # change 第一次pooling
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
# it is slightly better whereas slower to set stride = 1
# self.layer4 = self._make_layer(block, 512, layers[3], stride=1)
self.avgpool = nn.AvgPool2d(7)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x解释nn.Sequential
一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数。
看一下例子:
# Example of using Sequential
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Example of using Sequential with OrderedDict
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))