tensorflow实战——dropout防止过拟合验证
了解dropout那得先了解什么是overfitting(过拟合),underfitting(欠拟合)
overfitting就是指Ein(在训练集上的错误率)变小,Eout(在整个数据集上的错误率)变大的过程
underfitting是指Ein和Eout都变大的过程
使用简单的模型去拟合复杂数据时,会导致模型很难拟合数据的真实分布,这时模型便欠拟合了,或者说有很大的 Bias,Bias 即为模型的期望输出与其真实输出之间的差异;有时为了得到比较精确的模型而过度拟合训练数据,或者模型复杂度过高时,可能连训练数据的噪音也拟合了,导致模型在训练集上效果非常好,但泛化性能却很差,这时模型便过拟合了,或者说有很大的 Variance,这时模型在不同训练集上得到的模型波动比较大,Variance 刻画了不同训练集得到的模型的输出与这些模型期望输出的差异。
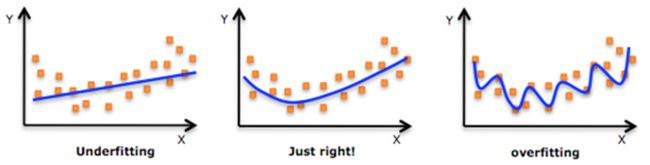
- 最左边为欠拟合,我们可以发现线条无法很好的拟合数据点的分布;
- 最右边为过拟合,我们可以发现线条可以很好的拟合数据点的分布,但好的有些过分了,以至于该拟合算法不具有推广性或者一般性,这就导致该算法对图中的数据点有很好的拟合效果,而对于具有相同规律的其他数据点比如测试集,无法有效的进行拟合!
模型处于过拟合还是欠拟合,可以通过画出误差趋势图来观察。若模型在训练集与测试集上误差均很大,则说明模型的 Bias 很大,此时需要想办法处理 under-fitting ;若是训练误差与测试误差之间有个很大的 Gap ,则说明模型的 Variance 很大,这时需要想办法处理 over-fitting。
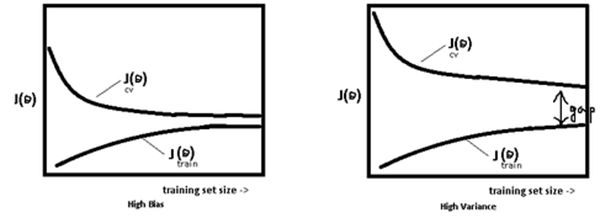
一般在模型效果差的第一个想法是增多数据,其实增多数据并不一定会有更好的结果,因为欠拟合时增多数据往往导致效果更差,而过拟合时增多数据会导致 Gap 的减小,效果不会好太多,多以当模型效果很差时,应该检查模型是否处于欠拟合或者过拟合的状态,而不要一味的增多数据量,关于过拟合与欠拟合,这里给出几个解决方法。
解决欠拟合的办法有:
1)调低正则项的惩罚参数
2)换更“复杂”的模型(如把线性模型换为非线性模型),比如核SVM 、决策树、DNN等模型;
3) 增加新特征,可以考虑加入进特征组合、高次特征,来增大假设空间;
4)多个模型级联或组合
5) Boosting ,Boosting 往往会有较小的 Bias,比如 Gradient Boosting 等.
解决过拟合的办法有:
1)增加训练数据可以有限的避免过拟合.
2)如果有正则项则可以考虑增大正则项参数 λ.
3) 交叉检验,通过交叉检验得到较优的模型参数;
4)特征选择,减少特征数或使用较少的特征组合,对于按区间离散化的特征,增大划分的区间。
5)换更“简单”的模型(如把非线性模型换为线性模型)6)使用dropout策略
下面我们使用tensorflow来看看dropout的效果,代码如下:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
tf.set_random_seed(1)
np.random.seed(1) #每次生成是一定的随机数,但np.random.randn(N_SAMPLE)生成不同随机数
N_SAMPLE = 20
N_HIDDEN = 300
LR = 0.01
x = np.linspace(-1, 1, N_SAMPLE)[:, np.newaxis] #增加列
y = x + 0.3 * np.random.randn(N_SAMPLE)[:, np.newaxis] #(20,1)
test_x = x.copy()
test_y = test_x + 0.3 * np.random.randn(N_SAMPLE)[:, np.newaxis]
#plt.scatter(x,y,c='magenta',s=100,alpha=0.5,label='train')
plt.scatter(test_x, test_y, c='cyan', s=50, alpha=0.5, label='test')
plt.legend(loc='upper left')
plt.ylim((-2.5, 2.5))
#plt.show()
tf_x = tf.placeholder(tf.float32, [None, 1])
tf_y = tf.placeholder(tf.float32, [None, 1])
tf_is_training = tf.placeholder(tf.bool, None)
# overfitting net
o1 = tf.layers.dense(tf_x, N_HIDDEN, tf.nn.relu)
o2 = tf.layers.dense(o1, N_HIDDEN, tf.nn.relu)
o_out = tf.layers.dense(o2, 1)
o_loss = tf.losses.mean_squared_error(tf_y, o_out)
o_train = tf.train.AdamOptimizer(LR).minimize(o_loss)
# dropout net
d1 = tf.layers.dense(tf_x, N_HIDDEN, tf.nn.relu)
d1 = tf.layers.dropout(d1, rate=0.5, training=tf_is_training)
d2 = tf.layers.dense(d1, N_HIDDEN, tf.nn.relu)
d2 = tf.layers.dropout(d2, rate=0.5, training=tf_is_training)
d_out = tf.layers.dense(d2, 1)
d_loss = tf.losses.mean_squared_error(tf_y, d_out)
d_train = tf.train.AdamOptimizer(LR).minimize(d_loss)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
plt.ion() #开启交互模式
for t in range(500):
sess.run([o_train, d_train], feed_dict={tf_x: x, tf_y: y, tf_is_training: True})
if t % 10 == 0:
plt.cla()
[o_loss_, d_loss_, o_out_, d_out_] = sess.run([o_loss, d_loss, o_out, d_out],
feed_dict={tf_x: test_x, tf_y: test_y, tf_is_training: False})
plt.scatter(x, y, c='magenta', s=50, alpha=0.3, label='train')
plt.scatter(test_x, test_y, c='cyan', s=50, alpha=0.3, label='test')
plt.plot(test_x, o_out_, 'r-', lw=3, label='overfitting')
plt.plot(test_x, d_out_, 'b--', lw=3, label='dropout(50%)')
plt.text(0, -1.2, 'overfitting loss = %.4f' % o_loss_, fontdict={'size': 10, 'color': 'red'})
plt.text(0, -1.5, 'dropout loss=%.4f' % d_loss_, fontdict={'size': 10, 'color': 'blue'})
plt.legend(loc='upper left')
plt.ylim((-2.5, 2.5))
plt.pause(0.1)
plt.ioff() #关闭交互模式
plt.show()
sess.close()实验结果如下:
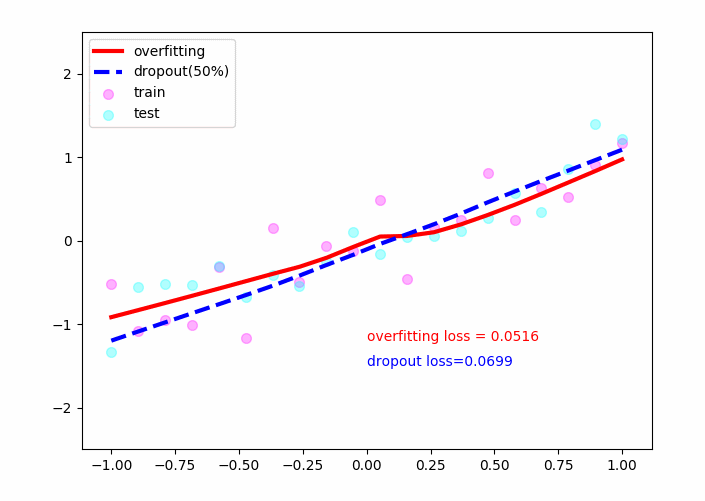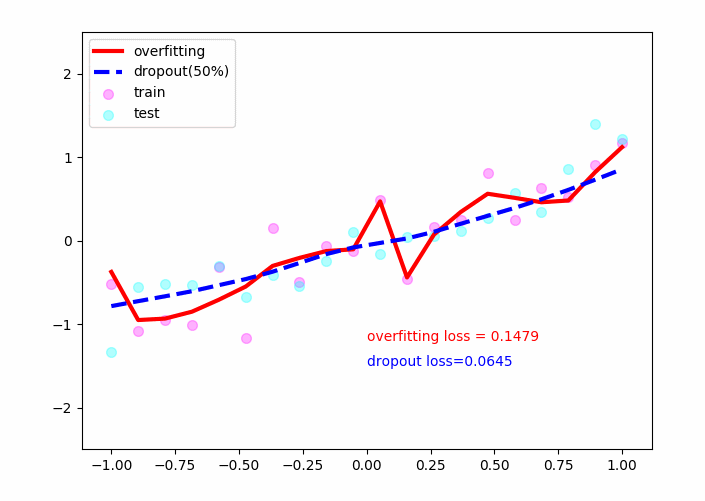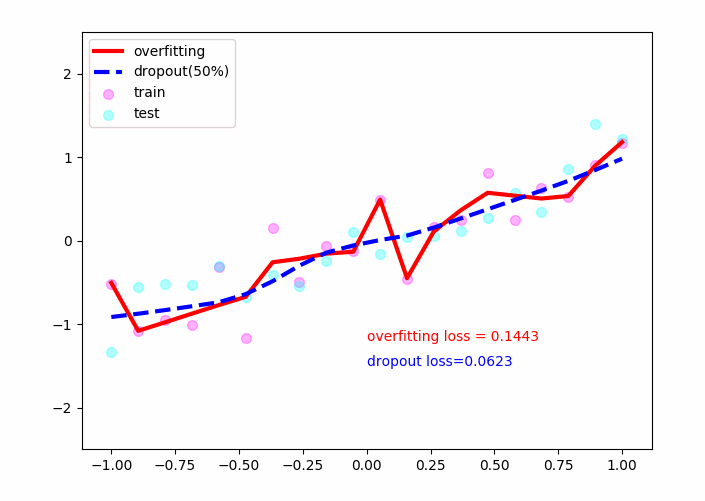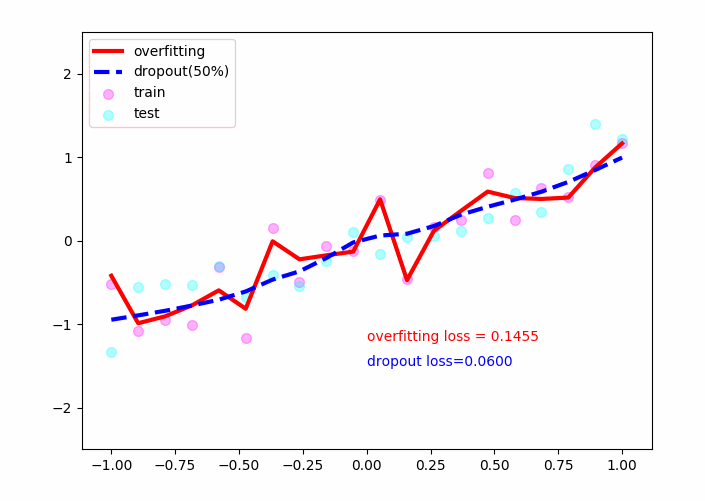
红色的线为未使用dropout的线,可以看见它对于训练的散点(粉红)有着较好的拟合效果,但其对于测试数据点(青绿)效果不佳,并且loss=0.14左右,即其不具有推广性!
蓝色的线为采用了dropout的线,可以看见它在测试数据集上也取得了不错的效果,最后loss稳定在了0.05左右,具有推广性!
因此dropout策略可以较好的解决过拟合问题。