最详细的tensorflow基于CNN(卷积神经网络)实战mnist手写识别(小白必看,包含各种基础知识讲解)
很荣幸您能看到这篇文章,相信通过标题打开这篇文章的都是对tensorflow感兴趣的,特别是对卷积神经网络在mnist手写识别这个实例感兴趣。不管你是什么基础,我相信,你在看完这篇文章后,都能够完全理解这个实例。这对于神经网络入门的小白来说,简直是再好不过了。
通过这篇文章,你能够学习到
- tensorflow一些方法的用法
- mnist数据集的使用方法以及下载
- CNN卷积神经网络具体python代码实现
- CNN卷积神经网络原理
- 模型训练、模型的保存和载入
Tensorflow实战mnist手写数字识别
关于这个mnist手写数字识别实战,我是跟着某课网上的教学视频跟着写的,大家有兴趣的话可以自取一下 百度云链接 提取码: 0x1f
需要导入的包
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data #mnist数据用到的包
下载mnist数据
mnist = input_data.read_data_sets('mnist_data',one_hot=True)
通过这一行代码,就可以将mnist数据集下载到本地文件夹mnist_data目录下,当然,你也可以使用绝对地址下载你想要下载的地方。这里需要注意一点是,如果第一次运行程序,由于需要下载资源的缘故,故需要一段时间,并且下载过程是没有提示的,之后下载成功时 才会提示 Success xxxxxx 。另一种方式就是直接去官网下载数据集
mnist官网 进去点击就可以直接下载了。
张量的声明
input_x = tf.compat.v1.placeholder(tf.float32,[None,28*28],name='input_x')#图片输入
output_y = tf.compat.v1.placeholder(tf.int32,[None,10],name='output_y')#结果的输出
image = tf.reshape(input_x,[-1,28,28,1])#对input_x进行改变形状,
稍微解释一下
[-1,28,28,1] -1表示不考虑输入图片的数量,28*28是图片的长和宽的像素值,1是通道数量,由于原图片是黑白的 ,所以通道是1,若是彩色图片,应为3.
取测试图片和标签
test_x = mnist.test.images[:3000]
test_y = mnist.test.labels[:3000]
[:3000]表示从列表下标为0到2999 这些数据
[1:3] 表示列表下标从1到2 这些数据
卷积神经网络第一层卷积层(用最通俗的言语告诉你什么是卷积神经网络)
#第一层卷积
conv1 = tf.layers.conv2d(inputs=image,#输入
filters=32,#32个过滤器
kernel_size=[5,5],#过滤器在二维的大小是5*5
strides=1,#步长是1
padding='same',#same表示输出的大小不变,因此需要补零
activation=tf.nn.relu#激活函数
)#形状[28,28,32]
第二层池化层
pool1 = tf.layers.max_pooling2d(
inputs=conv1,#第一层卷积后的值
pool_size=[2,2],#过滤器二维大小2*2
strides=2 #步长2
)#形状[14,14,32]
第三层卷积层2
conv2 = tf.layers.conv2d(inputs=pool1,
filters=64,
kernel_size=[5,5],
strides=1,
padding='same',
activation=tf.nn.relu
)#形状[14,14,64]
第四层池化层2
pool2 = tf.layers.max_pooling2d(
inputs=conv2,
pool_size=[2,2],
strides=2
)#形状[7,7,64]
平坦化
flat = tf.reshape(pool2,[-1,7*7*64])
使用flat.shape 输出的形状为(?, 3136)
1024个神经元的全连接层
dense = tf.layers.dense(inputs=flat,units=1024,activation=tf.nn.relu)
tf.nn.relu 是一种激活函数,目前绝大多数神经网络使用的激活函数是relu
Droupout 防止过拟合
dropout = tf.layers.dropout(inputs=dense,rate=0.5)
就是为了避免训练数据量过大,造成过于模型过于符合数据,泛化能力大大减弱。
过拟合-百度百科
10个神经元的全连接层
logits = tf.layers.dense(inputs=dropout,units=10,name="logit_1")
计算误差,使用adam优化器优化误差
#计算误差,使用交叉熵(交叉熵用来衡量真实值和预测值的相似性)
loss = tf.losses.softmax_cross_entropy(onehot_labels=output_y,logits=logits)
#学习率0.001 最小化loss值,adam优化器
train_op = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
计算精度值
accurary = tf.metrics.accuracy(
labels=tf.argmax(output_y,axis=1),
predictions=tf.argmax(logits,axis=1),)[1]
创建会话,初始化变量
sess = tf.compat.v1.Session()#创建一个会话
#初始化全局变量和局部变量
init = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
sess.run(init)
基本上到这里,这个程序就完成了,不过你也可以在此基础上加上一些数据的输出,使其更容易显示整个训练的过程。
比如我加上了这一段
for i in range(1000):
#获取以batch_size为大小的一个元组,包含一组图片和标签
batch = mnist.train.next_batch(50)
train_loss,train_op_,logits_output = sess.run([loss,train_op,logits],{input_x:batch[0],output_y:batch[1]})
if i % 100 == 0:
test_accuracy = sess.run(accurary,{input_x:test_x,output_y:test_y})
print(("step=%d,Train loss=%.4f,[Test accuracy=%.2f]") \
% (i, train_loss, test_accuracy))
输出为:
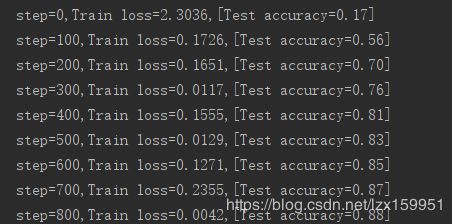
完整的代码数据文件我整理到了GitHub 下载地址 大家如果觉得可以的话,可以给个⭐
下面就回答一些我在学习过程中的遇到的问题:
【问】如何开始学习tensorflow,小白如何入门?
【答】 我的建议是先找到自己感兴趣的点,从这个点出发,通过实践将自己不明白的方法原理通过看官网,看博客,查百度,一一解决。文章开头的那个视频,我认为作为入门还不错,最好再有一本tensorflow相关书籍结合着来。
【问】 CNN卷积神经网络的流程是什么,其中的转化是什么样的?
【答】主要涉及的知识就是数组之间的计算,具体关于我对卷积神经网络的理解,可以参考这篇博客 最易懂-CNN卷积神经网络运行原理和流程
【问】训练好的模型如何保存或者直接拿来使用呢?
【答】具体看我的另一篇博客 模型的保存和使用 也是通过这个例子,教你如何保存模型和使用模型
【问】为什么中间有出现两次卷积层,两次池化层?
【答】这个不是必须的,有的比较复杂的模型需要很多层,每一层都是对上一层特征的提取,只是这个就是比较基本的模型,都是使用两次。初次咱们学习的话,就使用两次就够了,后面学习的知识多了,就可以自己根据实际情况加了。
【问】为什么全连接层有两个,里面的神经元数是固定的吗?
【答】有几个全连接层不是固定的,你就可以理解,这个全连接层就是做最后的收尾工作的,就是将前面几个层所提取到的信息,最后进行汇总 并显示,所以,最后一个全连接层的神经元必须是10,由于本次使用的ont-hot (独热码)的形式来表示图片的label,所以最后一个输出的神经元个数必须是10.至于前面的,大家可以尝试多使用几个尝试一下。
【问】one_hot独热码在咱们这个程序中是怎么使用的?
【答】其实我也是头一次听说这个编码(我是小白),举个例子吧。
0:1000000000
1:0100000000
2:0010000000
就是这种
持续更新中…