Garbage First(G1) GC 上篇 适用场景、数据模型、GC过程
G1 GC,全称Garbage-First Garbage Collector,在jdk6版本除了体验版,jdk7正式推出,jdk9钟,被提倡为默认GC
1. G1适用场景
G1适合作为服务端垃圾收集器,应用在多处理器和大内存的条件下,可以实现高吞吐量的同时,尽可能满足垃圾收集较短可控的暂停时间,主要针对以下场景设计
- 像CMS一样,能与应用程序并发执行
- 更快速整理空闲空间
- GC停顿时间更可控
- 不会牺牲大量吞吐性能
- 服务端多核CPU、JVM内存占用较大的应用(至少大于4G)
- 应用在运行过程中会产生大量内存碎片、需要经常压缩空间
- 想要更可控、可预期的GC停顿周期;防止高并发下应用雪崩现象
2. G1 数据模型
2.1 分区Region
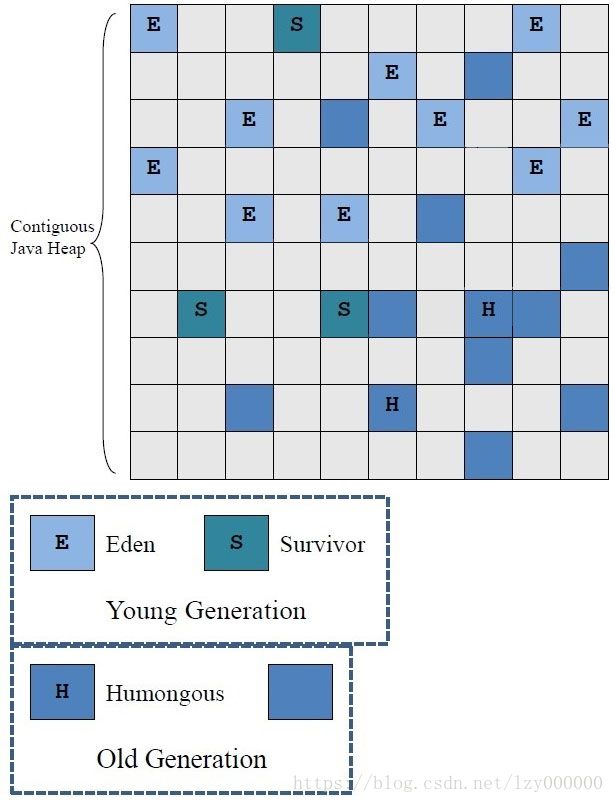
传统的GC将内存划分为新生代,老年代,永久代(JDK8取消了永久代),传统划分的各代存储地址是连续的

G1的各代存储地址是不连续的,每一代都使用了n个不连续region,每个region占有一块连续的虚拟内存,
每一个分配的Region,都可以分成两个部分,已分配的和未被分配的。它们之间的界限被称为top。总体上来说,把一个对象分配到Region内,只需要简单增加top的值。
G1收集器会维护一个空间Region的链表,每次回收的Region都会加入这个链表中,每次只有一个Region处于被分配状态(current region)。多线程情况下用TLABs为每个线程分配Buffer,即为每个线程分配一个Buffer,线程分配内存都在这个Buffer内分配
G1不要求对象存储物理上是连续的,只要逻辑上连续,每个分区也不是一定是确定的某个代,也就是每个角色(eden、survivor、old、humongous)并不强制规定大小数量,可以动态变化(新生代默认5%)。
其中humongous表示巨大对象,即大小大于登入region一半的对象
- humongous对象直接分配到了old gen,防止了反复拷贝移动。
- humongous对象在global concurrent marking阶段的cleanup 和 full GC阶段回收。
- 在分配humongous对象前,先检查是否超过 initiating heap occupancy percent和the marking threshold, 如果超过的话,就启动global concurrent marking,为的是提早回收,防止 evacuation failures 和 full GC。
-XX:G1HeapRegionSize=n
可指定分区大小(1MB~32MB,且必须是2的幂),默认将整堆划分为2048个分区。
2.2 RSet(RememberSet)、CT(CardTable)和CSet(CollectionSet)
在普通的分代收集(如CMS)中,新生代收集后,部分对象需要从新生代转移到老年代,而引用该对象的记录也需要更新,这个过程需要采用的copying算法移动对象,所以要更新引用为对象的新地址,通常叫做remembered set(简称RS)。
因为每次G1GC都是针对一部分Region回收, 所以回收时需要确定该Region的对象被哪些其他Region的对象引用着,而在G1中,CardTable是一种remembered set, 一个card代表一个范围的内存,目前采用512bytes表示一个card,cardtable就是一个byte数组,每个Region有自己的Cardtable。
维护remembered set需要mutator线程在可能修改跨Region的引用的时候通知collector, 这种方式通常叫做write barrier(和GC中的Memory Barrier不同), 每个线程都会有自己的remembered set log,相当于各自的修改的card的缓冲buffer,除此之外还有全局的buffer,mutator自己的remember set buffer满了之后会放入到全局buffer中,然后创建一个新的buffer。
逻辑上说每个Region都有一个RSet,RSet记录了其他Region中的对象引用本Region中对象的关系,但在G1中,并没有使用point-out,这是由于一个分区太小,分区数量太多,如果用point-out,会造成大量扫描浪费,有些根本不需要GC的分区引用也扫描了。所以G1使用points-into结构(谁引用了我的对象)。而Card Table则是一种points-out(我引用了谁的对象)的结构,每个Card 覆盖一定范围的Heap(一般为512Bytes)。G1的RSet是在Card Table的基础上实现的:每个Region会记录下别的Region有指向自己的指针,并标记这些指针分别在哪些Card的范围内。 这个RSet其实是一个Hash Table,Key是别的Region的起始地址,Value是一个集合,里面的元素是Card Table的Index。
RSet、CardTable和Region的关系(出处)

上图中有三个Region,每个Region被分成了多个Card,在不同Region中的Card会相互引用,Region1中的Card中的对象引用了Region2中的Card中的对象,蓝色实线表示的就是points-out的关系,而在Region2的RSet中,记录了Region1的Card,即红色虚线表示的关系,这就是points-into。
3. G1 GC过程
G1提供了两种GC模式,Young GC和Mixed GC,两种均是完全Stop The World的。
- Young GC:选定所有年轻代里的Region。通过控制年轻代的region个数,即年轻代内存大小,来控制young GC的时间开销。
- Mixed GC:选定所有年轻代里的Region,外加根据global concurrent marking统计得出收集收益高的若干老年代Region。在用户指定的开销目标范围内尽可能选择收益高的老年代Region。
3.1 G1 YoungGC
- 阶段1:根扫描
静态和本地对象被扫描 - 阶段2:更新RSet
处理dirty card队列更新RSet - 阶段3:处理RSet
检测从新生代指向老年代的对象 - 阶段4:对象拷贝
拷贝存活的对象到survivor/old区域 - 阶段5:处理引用队列
软引用,弱引用,虚引用处理
3.2 G1 Mix GC
在G1 GC中,它主要是为Mixed GC提供标记服务的,并不是一次GC过程的一个必须环节。global concurrent marking的执行过程分为五个步骤:
- 初始标记(initial mark,STW)
在此阶段,G1 GC 对根进行标记,是STW的。 - 根区域扫描(root region scan)
G1 GC 标记了从GC Root开始直接可达的对象,在初始标记的存活区扫描对老年代的引用,并标记被引用的对象。该阶段与应用程序(非 STW)同时运行,并且只有完成该阶段后,才能开始下一次 STW 年轻代垃圾回收。 - 并发标记(Concurrent Marking)
G1 GC 在整个堆中查找可访问的(存活的)对象。该阶段与应用程序同时运行(非STW),可以被 STW 年轻代垃圾回收中断 - 最终标记(Remark,STW)
该阶段是 STW 回收,帮助完成标记周期。G1 GC 清空 SATB 缓冲区,跟踪未被访问的存活对象,并执行引用处理。 - 清除垃圾(Cleanup,STW)
在这个最后阶段,G1 GC 执行统计和 RSet 净化的 STW 操作。在统计期间,G1 GC 会识别完全空闲的区域和可供进行混合垃圾回收的区域。清理阶段在将空白区域重置并返回到空闲列表时为部分并发。
1. 并发标记阶段(Concurrent Marking Phase):
在不产生stop-the-world,与程序进程并发的情况下,活跃度(可达性分析)被分析出来。
活跃度越低,代表回收的效率越高,越值得优先回收。
2. 复制、清理阶段(Copying/Cleanup Phase)
年轻代、老年代在这个阶段同时被回收掉。老年代被回收的region,是根据这个region的存活度来选择的。
本章节简单介绍了G1的概念,数据模型和GC过程,下一章节会对G1相关算法进行一些讲解总结。