CTPN-自然文本场景检测学习笔记
文章目录
- 出发点
- 改进点(top-down)
- 基本流程
- Detecting Text in Fine-scale(细粒度) Proposals
- Recurrent Connectionist Text Proposals
- Side-refinement(边缘细化)
- 1. 文本行的构建:
- 2. 边缘细化:
- 模型输出与损失函数
- 三个疑问
- 为什么要使用BLSTM
- 如何通过"FC"卷积层输出产生Text proposals?
- Anchor为什么这么设置
- 训练和实现细节
- 参考博客以及代码地址
CTPN网络结构图

出发点
之前的方法的缺点:
自底向上(bottom-up):非文本组件过滤,文本行构建和文本行验证。(两种方法:connected-components methods, sliding-window methods)
缺点:鲁棒性和可靠性差,依赖于字符的检测结果
改进点(top-down)
- 垂直锚点机制(vertical anchor mechanism):联合预测每个文本提议的垂直位置和文本/非文本分数,从而获得出色的定位精度。
- 网内循环架构(in-network recurrent architecture):用于按顺序连接这些细粒度的文本提议,从而允许它们编码丰富的上下文信息。
- 两种方法无缝集成,以符合文本序列的性质,从而形成统一的端到端可训练模型。能够在单个过程中处理多尺度和多语言的文本,避免进一步的后过滤或细化。
- 使用VGG16模型,计算上高效,每张图像0.14s。
基本流程
-
用VGG16的前5个Conv stage(到conv5)得到feature map( W ∗ H ∗ C W*H*C W∗H∗C)
-
在Conv5的feature map的每个位置上取 3 ∗ 3 ∗ C 3*3*C 3∗3∗C的窗口的特征,这些特征将用于预测该位置k个anchor对应的类别信息,位置信息。
anchor定义:(卷积网络生成特征图之后,用这些特征图进行3 * 3的卷积,当3 * 3的卷积核滑动到特征图的某一个位置时,以当前滑动窗口中心为中心映射到原图的一个区域,以原图上的的这个区域为中心去画框,这个框就称为anchor。
* 有一点很容易弄错,从上面的解释可以看出,anchor是在原图上的,不是在特征图上的
* 特征图的每个中心点,会在原图上画出9个anchor,分别是三种不同大小的尺寸和三种不同的长宽比例(1:1,1:2,2:1)
* 尺寸的大小是根据监测的图像去设置的 -
将每一行的所有窗口对应的 3 ∗ 3 ∗ C 3*3*C 3∗3∗C的特征( W ∗ 3 ∗ 3 ∗ C W*3*3*C W∗3∗3∗C)输入到RNN(BLSTM)中,得到 W ∗ 256 W*256 W∗256的输出
-
将RNN的 W ∗ 256 W*256 W∗256输入到512维的fc层
-
fc层特征输入到三个分类或者回归层中。第二个2k scores 表示的是k个anchor的类别信息(是字符或不是字符)。第一个2k vertical coordinate和第三个k side-refinement是用来回归k个anchor的位置信息。2k vertical coordinate表示的是bounding box的高度和中心的y轴坐标(可以决定上下边界),k个side-refinement表示的bounding box的水平平移量。这边注意,只用了3个参数表示回归的bounding box,因为这里默认了每个anchor的width是16,且不再变化(VGG16的conv5的stride是16)。回归出来的box的宽度是一定的。
-
用简单的文本线构造算法,把分类得到的文字的proposal合并成文本线
Detecting Text in Fine-scale(细粒度) Proposals
允许任意大小的输入图像。它通过在feature map中密集地滑动小窗口来检测文本行,并且输出一系列细粒度的(例如,宽度为固定的16个像素)文本proposal。
论文采用,k=10,每个 proposal 设定 10 个 anchors,anchors 高度范围为 [11 - 273] pixels(每次除以 0.7),仅回归y1,y2,而不是x1, x2, y1, y2.
-
RPN生成的proposal和细粒度的proposal作比较。普通目标具有明确的边界和中心,可以从它的一部分推断这个目标;文本没有明显封闭边界(笔画,字符,单词,文本行,文本区域)。由RPN进行的单词检测很难准确预测单词的水平边,因为单词中的每个字符都是孤立或者分离的。而文本行是一个序列,可以视为一系列细粒度的proposal,每一个proposal代表文本行的一部分(单个或多个笔画,字符的一部分,单个或多个字符)。
下图为RPN和细粒度的proposal对比图

-
通过固定每个anchor的水平位置来预测其垂直位置(水平位置更难预测)。垂直锚点机制:同时预测每个细粒度提议的文本/非文本分数和y轴的位置。检测一系列固定宽度文本提议中的文本行也可以在多个尺度和多个长宽比的文本上可靠地工作。
使用bounding box的高和y轴中心来衡量垂直坐标:
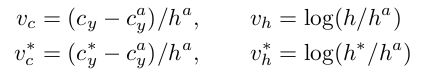
其中, v = ( v c , v h ) v=(v_c, v_h) v=(vc,vh)和 v ∗ = ( v c ∗ , v h ∗ ) v^*=(v_c^*, v_h^*) v∗=(vc∗,vh∗)分别是预测的坐标和ground truth 坐标。 c y a c_y^a cya和 h a h^a ha是anchor box的y轴中心和高度,从原图像中计算得来的。 c y c_y cy和 h h h是预测的y轴坐标, c y ∗ c_y^* cy∗和 h ∗ h^* h∗是ground truth 坐标。每个预测文本propoasl都有一个大小为h×16的边界框(在输入图像中)。一般来说,文本proposal在很大程度上要比它的有效感受野228×228要小。 -
给定输入图像,产生 W×H×C conv5 feature map(通过使用VGG16模型),其中C是feature map通道数,并且W×H是空间布置。在conv5密集地滑动3×3窗口,每个滑动窗口使用3×3×C的卷积特征来产生预测。对于每个预测,水平位置(x轴坐标)和k个anchor位置是固定的,可以通过将conv5中的空间窗口位置映射到输入图像上来预先计算。在每个窗口位置输出k个anchor的文本/非文本分数和预测的y轴坐标(v)。检测到的文本提议是从具有>0.7(具有非极大值抑制)的文本/非文本分数的anchor生成的。
结论: 通过设计的垂直anchor和细粒度的检测策略,可以通过使用单尺度图像处理各种尺度和长宽比的文本行。这进一步减少了计算量,同时预测了文本行的准确位置。
Recurrent Connectionist Text Proposals
上一步将文本行分成一系列细粒度的文本proposal,因为文本具有序列特征,上下文信息很重要,所以应用RNN(BLSTM)编码上下文信息来进行文本识别。
- RNN类型:BLSTM,每个LSTM有128个隐藏层
- RNN输入:每个滑动窗口的3*3*C的特征(可以拉成一列),同一行的窗口的特征形成一个序列
- RNN输出:每个窗口对应256维特征
下图是不使用RNN(上)的和使用RNN(下)的CTPN比较图:

在卷积层中编码这些信息,从而实现细粒度文本proposal无缝的网内连接。使用RNN的隐藏层对信息进行循环编码。
本文中:在conv5上设计一个RNN层,它将每个窗口的卷积特征作为序列输入,并在隐藏层中循环更新其内部状态:H_t
下图为RNN内部更新内部状态的公式:
![]()
其中 X t ∈ R 3 × 3 × C X_t∈R^{3×3×C} Xt∈R3×3×C是第t个滑动窗口(3×3)的输入conv5特征。滑动窗口从左向右密集移动,生成每行的 t = 1 , 2 , . . . , W t=1,2,...,W t=1,2,...,W序列特征。W是conv5的宽度。 H t H_t Ht是用当前输入 ( X t ) (X_t) (Xt)和先前状态 H t − 1 H_{t−1} Ht−1联合计算的循环内部状态。递归是通过使用非线性函数 φ φ φ来计算的,它定义了循环模型的确切形式。使用双向LSTM,以能够在两个方向上对上下文进行编码,以便能够顾及到整张图片的信息。每个LSTM使用一个128维的隐藏层,BLSTM就是256维的RNN隐藏层 H t ∈ R 256 H_t∈R^{256} Ht∈R256。
H t H_t Ht中的内部状态被映射到后面的FC层,并且输出层用于计算第t个proposal的预测,大大减少了错误检测,同时还能够恢复很多包含非常弱的文本信息的遗漏文本proposal。
Side-refinement(边缘细化)
1. 文本行的构建:
- 主要思想:每两个相近的proposal组成一个pair,合并不同的pair直到无法再合并为止(没有公共元素)
- 首先,若两个proposal B i B_i Bi和 B j B_j Bj,满足以下条件,则表示为 B j B_j Bj−> B i B_i Bi,
- B j B_j Bj是最接近 B i B_i Bi的水平距离
- 该距离小于50像素
- 它们的 o v e r l a p v overlap_v overlapv是>0.7
- 其次,如果 B j B_j Bj−> B i B_i Bi并且 B i B_i Bi−> B j B_j Bj,则将两个提议分组为一对。然后通过顺序连接具有相同proposal的对来构建文本行
2. 边缘细化:
- 问题:当两个水平边的文本proposal没有完全被实际文本行区域覆盖,或者某些边的proposal被丢弃(例如文本得分较低)时,这可能会导致不准确的定位。
- 解决:边缘细化。可以精确地估计左右两侧水平方向上的每个anchor/proposal的偏移量(称为side-anchor或side-proposal)。
与y坐标预测类似,我们计算相对偏移为:
以下是边缘细化计算相对偏移公式:
![]()
其中 x s i d e x_{side} xside是最接近当前anchor 水平边(左边或右边)的预测的x坐标。 x s i d e ∗ x^*_{side} xside∗是x轴的ground truth(GT) 边缘坐标,它是从GT bounding box和anchor 位置预先计算的。 c x a c_x^a cxa是x轴的anchor的中心。 w a w^a wa是固定的anchor宽度, w a = 16 w^a=16 wa=16。我们只使用side-proposal的偏移量来优化最终的文本bounding box。
下图为有无边缘细化对比图(CTPN检测有(红色框)和没有(黄色虚线框)边缘细化。细粒度提议边界框的颜色表示文本/非文本分数):

模型输出与损失函数
CTPN有三个输出共同连接到最后的FC层。这三个输出同时预测文本/非文本分数(textbfs),垂直坐标( v = ( v c , v h ) v=(v_c,v_h) v=(vc,vh))和边缘细化偏移( o o o)。通过k个anchor来预测它们在conv5中的每个空间位置,从而在输出层分别得到 2 k 2k 2k, 2 k 2k 2k和 k k k个参数。
损失函数:

- 带 ∗ * ∗的都是ground truth,每个anchor都是一个训练样本, i i i是在mini-batch中的anchor的索引, s i s_i si是ancho是文本的预测概率, s i ∗ s_i^* si∗是 ground truth = {0,1}。
- j是y坐标回归中有效anchor的索引,有效anchor是正anchor( s j ∗ = 1 s_j^*=1 sj∗=1)或者和ground truth text proposal有 >0.5 的 i o u iou iou, v j v_j vj和 v j ∗ v_j^* vj∗是第 j 个anchor的预测和真实的y坐标。
- k是 side-anchor 的索引,就是实际文本行边界框的左侧或右侧水平距离内的一组anchor, o k o_k ok和 o k ∗ o_k^* ok∗是第k个anchor的x的预测和实际偏移量。
- L s c l L_s^{cl} Lscl是我们使用Softmax损失区分文本和非文本的分类损失。
- L v r e L_v^{re} Lvre 和 L o r e L_o^{re} Lore 是回归损失,使用 smooth L1 函数来计算。 λ 1 \lambda_1 λ1和 λ 2 \lambda_2 λ2是损失权重,用来平衡不同的任务,根据经验设为1.0和2.0。 N s N_s Ns, N v N_v Nv和 N o N_o No是标准化参数,表示 L s c l L_s^{cl} Lscl, L v r e L_v^{re} Lvre和 L o r e L_o^{re} Lore分别使用的anchor总数。
L v r e ( v j , v j ∗ ) = s m o o t h L 1 ( v j − v j ∗ ) L_v^{re}(v_j, v_j^*) = smooth_{L1}(v_j - v_j^*) Lvre(vj,vj∗)=smoothL1(vj−vj∗)
其中 s m o o t h L 1 smooth_{L1} smoothL1公式如下( x = v j − v j ∗ x = v_j - v_j^* x=vj−vj∗):
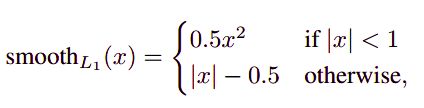
三个疑问
为什么要使用BLSTM
CTPN的网络结构与Faster-RCNN类似,只是其中加入了BLSTM层。CNN学习的是感受野内的空间信息;而且伴随网络的深入,CNN学到的特征越来越抽象。对于文本序列检测,显然需要CNN学到的抽象空间特征;另外文本所具备的sequence feature(序列特征)也有助于文本检测。对于水平的文本行,其中的每一个文本段之间都是有联系的,因此作者采用了CNN+RNN的一种网络结构,使得检测结果更加鲁棒。
如何通过"FC"卷积层输出产生Text proposals?
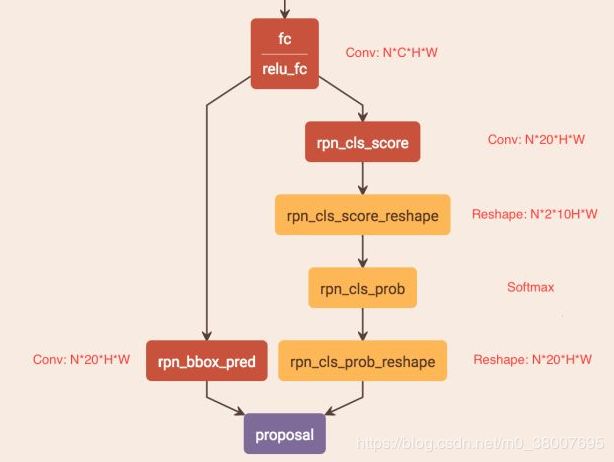
CTPN通过CNN和BLSTM学到一组“空间 + 序列”特征后,在"FC"卷积层后接入RPN网络。这里的RPN与Faster R-CNN类似,分为两个分支:
- 左边分支用于bounding box regression。由于fc feature map每个点配备了10个Anchor,同时只回归中心y坐标与高度2个值,所以rpn_bboxp_red有20个channels
- 右边分支用于softmax分类Ancho
Anchor为什么这么设置
- 保证在x方向上,Anchor覆盖原图每个点且不相互重叠。
- 不同文本在 y方向上高度差距很大,所以设置Anchors高度为11-283,用于覆盖不同高度的文本目标。
训练和实现细节
- 训练标签。
对于文本/非文本分类,二值标签分配给每个正(文本)anchor或负(非文本)anchor。它通过计算与实际边界框的IoU重叠(除以anchor位置)来定义。正anchor被定义为:(i)与任何实际边界框具有>0.7的IoU重叠;或者(ii)与实际边界框具有最高IoU重叠。通过条件(ii),即使是非常小的文本模式也可以分为正anchor。这对于检测小规模文本模式至关重要,这是CTPN的主要优势之一。这不同于通用目标检测,通用目标检测中条件(ii)的影响可能不显著。 - 训练数据。
在训练过程中,每个小批量样本从单张图像中随机收集。每个小批量数据的anchor数量固定为N_s=128,正负样本的比例为1:1。如果正样本的数量少于64,则会用小图像块填充负样本。在3000张自然图像上训练,其中包括来自ICDAR 2013训练集的229张图像。还自己收集了其他图像,并用文本行边界框进行了手工标注。在所有基准测试集中,所有自我收集的训练图像都不与任何测试图像重叠。为了训练,通过将输入图像的短边设置为600来调整输入图像的大小,同时保持其原始长宽比 - 实现细节。
在ImageNet数据上预先训练非常深的VGG16模型。我们通过使用具有0均值和0.01标准差的高斯分布的随机权重来初始化新层(例如,RNN和输出层)。通过固定前两个卷积层中的参数进行端对端的训练。我们使用0.9的动量和0.0005的权重衰减。在前16K次迭代中,学习率被设置为0.001,随后以0.0001的学习率再进行4K次迭代
参考博客以及代码地址
论文地址: https://arxiv.org/abs/1609.03605
论文翻译: https://blog.csdn.net/quincuntial/article/details/79475339
解读博客: https://blog.csdn.net/zchang81/article/details/78873347
Caffe代码:https://github.com/tianzhi0549/CTPN
TensorFlow代码:https://github.com/eragonruan/text-detection-ctpn
BLSTM讲解 https://blog.csdn.net/weixin_41722370/article/details/80869925
参考文章 http://www.neurta.com/node/390