CRAFT: Character Region Awareness for Text Detection ---- 论文翻译
基于字符区域感知的文本检测
论文地址:https://arxiv.org/abs/1904.01941
论文解读:https://blog.csdn.net/m0_38007695/article/details/97946521
摘要
最近出现了基于神经网络的场景文本检测方法,并且已经显示出可观的结果。之前的方法使用严格的单词级别的边界框训练,在表示任意形状的文本区域会有所限制。在本文中,我们提出了一种新的场景文本检测方法,通过探索每个字符和字符之间的亲和力来有效地检测文本区域。为了克服缺乏单个字符级注释的缺点,我们提出的框架利用了合成图像的给定字符级注释和通过学习中间模型估计的真实图像的字符级 ground-truths。为了估计字符之间的亲和力(affinity),使用新提出的关联性表示来训练网络。在六项基准上拓展试验,包括TotalText和CTW-1500数据集,其中包含自然图像中的高度弯曲文本,表明我们的字符级文本检测明显优于最先进的检测器。根据结果,我们提出的方法保证了检测复杂场景文本图像的高度灵活性,例如任意形状的,弯曲的或变形的文本。
1. 介绍
场景文本检测由于它的众多应用在计算机视觉上引起了很大的关注,例如即时翻译,图像检索,场景解析,地理位置和盲导航。最近,在深度学习上的场景文本检测展示处理可观的表现。这些方法主要通过定位单词级别的边界框训练他们的网络。但是,它们可能会遇到困难的情况,例如弯曲,变形或极长的文本,这些是很难使用单个边框检测到。另外,通过以自下而上的方式连接连续的字符来处理具有挑战性的文本时,字符感知具有许多优点。不幸的是,大多数现有的文本数据集都没有提供字符级别的注释,而获得字符级别的ground_truth所需的工作成本太高。
在本文中,我们提出了一个新颖的检测器去定位单个字符区域,然后把连接检测到的字符连接成一个文本实例。我们的框架CRAFT使用CNN,产生字符区域分数(region score)和亲和力分数(affinity score)。使用区域分数来定位图像中的单个字符,使用亲和力分数把每一个字符进行分组到单个实例中。为了补偿字符级别注释的缺点,我们提出了一个弱监督学习框架使用单词级别的数据集估计字符级别的ground-truths。
图1是CRAFT在各种形状的文本上的可视化结果。利用字符区域感知,各种形状的文本很容易表示。我们在ICDAR数据集上进行了大量实验来验证我们的方法,实验表明,提出的方法优于最新的文本检测器。在MSRA-TD500,CTW-1500和TotalText数据集上的实验显示提出方法在复杂情况下的高度灵活性,例如长的,弯曲的,任意形状的文本。
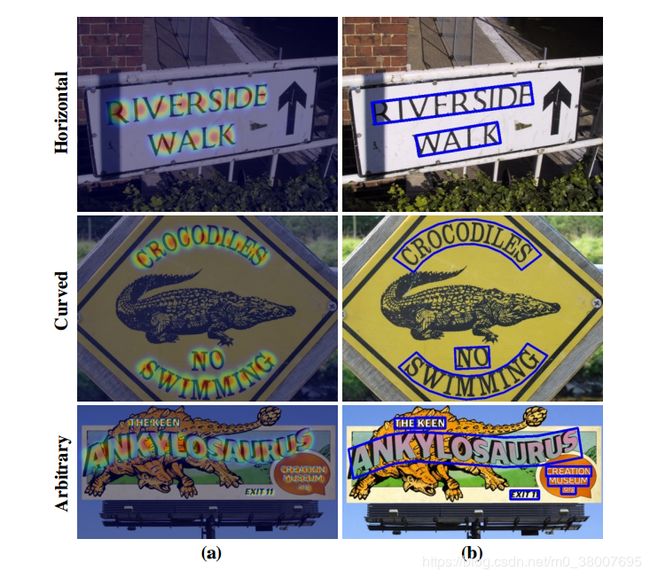
图1. 使用CRAFT的字符级检测结果
2. 相关工作
在深度学习之前,场景文本检测的主要趋势是自上而下,大多数使用手工提取特征(例如MSER 或 SWT)作为基础的组件。最近,通过采用流行的物体检测/分割方法,如SSD,Faster R-CNN和FCN,提出了基于深度学习的文本检测器。
基于回归的文本检测器 各种使用边框回归的文本检测器都是从已经提出的流行的目标检测器改动来的。与通用目标不同,文本通常以具有各种宽高比的不规则形状呈现。 为了解决这个问题,TextBoxes 修改了卷积内核和anchor,以有效地捕获各种文本形状。 DMPNet试图通过结合四边形滑动窗口来进一步减少这个问题。 最近,Rotation-Sensitive Regression Detector (RSDD) 通过旋转卷积核,充分利用了旋转不变特征。 然而,在使用这些方法时,获取自然场景下的所有形状时会有一些结构限制。
基于分割的文本检测器 另一种常见的方法是基于处理分割的工作,其目的是在像素级寻找文本区域。这些方法通过估计单词边界区域来检测文本,例如多尺度FCN,Holistic-prediction和PixelLink,也已经提出使用分割作为其基础。SSTD试图通过使用注意机制通过减少特征级别的背景干扰来增强文本相关区域,从而从回归和分割方法中受益。最近,TextSnake 通过预测文本区域和中心线以及几何属性来检测文本实例。
端到端的文本检测器 端到端方法同时训练检测和识别模块,通过利用识别结果来提高检测精度。FOTS 和EAA 结合了流行的检测和识别方法,并以端到端的方式对它们进行训练。Mask TextSpotter 利用其统一模型将识别任务视为语义分割问题。很明显,使用识别模块进行训练有助于文本检测器对像文本的背景噪点更加健壮。
大多数方法以单词为单位检测文本,但是对检测单词的范围的定义非常重要的,因为单词可以通过各种标准分隔,例如含义,空格或颜色。另外,不能严格定义分词的边界,因此词段本身没有明显的语义含义。对于回归和分割方法,单词注释的模糊性淡化了ground-truth的含义。
字符级别的文本检测器 Zhang 等人提出了一种使用 MSER 提取的文本块候选的字符级检测器。它使用MSER识别单个字符限制了它在某些情况下的检测鲁棒性,例如低对比度,曲率和光反射的场景。Yao等人使用了字符的预测 map 以及文本词区域的 map 和请求的字符级别注释的连接方向。Seglink 不是明确的字符级别预测,而是搜索文本网格(部分文本片段)并将这些片段与其他链接预测相关联。即使Mask TextSpotter 预测了字符级概率图,它也被用于文本识别而不是发现单个字符。
这项工作的灵感来自WordSup 的想法,它使用弱监督框架来训练字符级别的检测器。然而,Wordsup的一个缺点是用矩形anchor来表示字符,使其易受由各种摄像机视角引起的字符的透视变形的影响。此外,它受骨架结构性能的限制(使用SSD并受anchor数量及其尺寸的限制)。
3. 方法
我们的主要目的是 精确地定位自然图像中的每一个字符 。为此,我们训练了一个深度神经网络去预测字符区域和字符之间的亲和力。由于没有可用的公共字符集数据集,因此以弱监督的方式训练模型。
3.1 结构
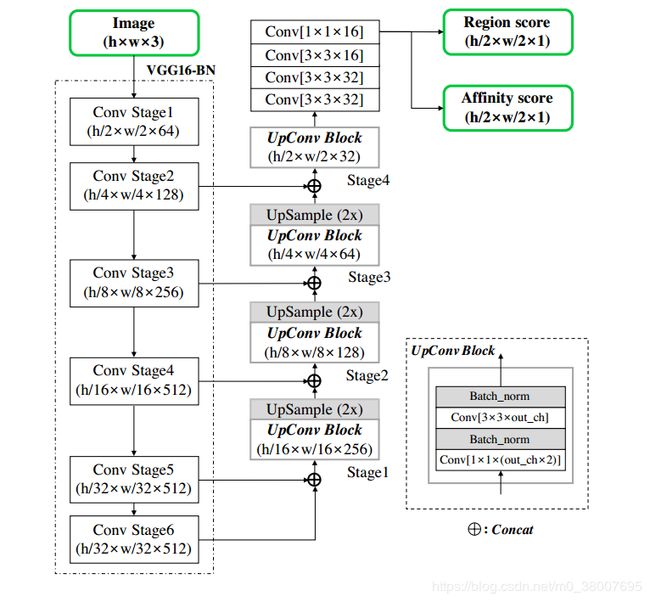
基于VGG-BN的全卷积神经网络作为主干网络。我们的模型在解码部分中跳过连接,这类似于U-net,因为它聚合了低级特征。最终的输出有两个通道作为score map:region score 和 affinity score。网络架构在图2中展示。
3.2 训练
3.2.1 Ground Truth Label 生成
对于每一张图像,我们为 region score 和 affinity score 生成带有字符级别边界框的 ground truth label。region score 表示给定的像素是字符中心的概率,affinity score 表示相邻两个字符中间空白区域中心的概率。
不像二进制分割图以离散方式标记每个像素,我们使用高斯热图对字符中心的概率进行编码。该热图表示已经用于其他应用,例如姿势估计工作,因为它在处理非严格限制的ground truth 区域时具有高度的灵活性。我们使用热图表示去学习region score和 affinity score。
图3 总结了一个合成图像的 label 生成流程。直接计算在边界框中的每一个像素的高斯分布值是非常耗时的。由于图像上的字符边界框通常通过透视投影扭曲,所以我们使用以下的步骤来近似生成 region score 和 affinity score的 ground truth:1)准备一个二维各向同性高斯映射;2)计算高斯图区域和每个字符框之间的透视变换;3)把高斯图映射到字符框区域。
对于affinity score的 ground truth,亲和(affinity)框是通过相邻字符框定义的,如图3 所示。通过连接每个字符框的对角画出对角线,生成两个三角形(我们将其成为上下三角形)。然后,对于每对相邻字符框,通过将上下三角形的中心设置为框的角来生成亲和框。

尽管使用了小的感受野,但提出的 ground truth 定义使模型能够充分检测大的或长的文本实例。另一方面,像基于边框回归先前方法在这种情况下需要大的感受野。我们的字符级检测使得卷积核可以仅关注字符内和字符间,而不是整个文本实例。
3.2.2 弱监督学习
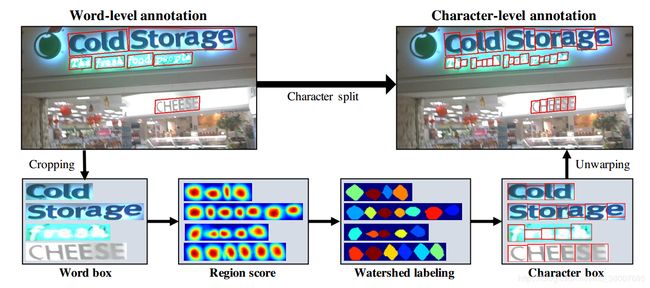
与合成数据集不同,数据集中的真实图像通常是单词级注释。 在这里,我们以弱监督的方式从每个单词级注释生成字符框,如图4所示。当提供具有单词级注释的真实图像时,学习的中间模型预测裁剪的单词图像的字符区域分数以生成字符级边界框。为了反映中间模型预测的可靠性,每个单词框上的置信度图的值与检测到的字符数除以ground truth字符的数量成比例,用于学习训练期间权重。

图6显示了分割字符的整个过程。首先,从原始图像裁剪词级图像。 其次,最新训练的模型预测了region score。 第三,分水岭算法用于分割字符区域,用于使字符边界框覆盖区域。最后,使用来自裁剪步骤的逆变换将字符框的坐标变换回原始图像坐标。region score 和 affinity score 的 pseudo-ground truths(pseudoGTs)可以通过图3中描述的步骤使用获得的四边形字符级边界框生成。
当使用弱监督训练模型时,我们被迫训练不完整的 pseudo-GTs。 如果使用不准确的区域分数训练模型,则输出可能在字符区域内模糊。为了防止这种情况,我们去衡量模型生成的每个 pseudo-GTs 的质量。幸运的是,文本注释中有一个非常有用的线索,即单词长度。 在大多数数据集中,提供了单词的转录,并且单词的长度可用于评估 pseudo-GTs 的置信度。
对于训练数据的单词级注释样本 w w w, 让 R ( w ) R(w) R(w) 和 l ( w ) l(w) l(w) 分别代表样本 w w w 的边框区域和单词长度。根据字符分割流程,我们可以获得估计的字符边界框和他们相应的字符长度 l c ( w ) l^c(w) lc(w) 。然后样本 w w w 的置信分数 s c o n f ( w ) s_{conf}(w) sconf(w) 可以这样计算,
(1) s c o n f ( w ) = l ( w ) − m i n ( l ( w ) , ∣ l ( w ) − l c ( w ) ∣ ) l ( w ) s_{conf}(w) = \frac{l(w) - min(l(w), |l(w) - l^c(w)|)}{l(w)} \tag{1} sconf(w)=l(w)l(w)−min(l(w),∣l(w)−lc(w)∣)(1)
一张图像的像素级置信图 S c S_c Sc 可以这样计算,
(2) S c ( p ) = { s c o n f ( w ) p ∈ R ( w ) 1 o t h e r w i s e S_c(p) = \begin{cases} s_{conf}(w) \quad p \in R(w) \\ 1 \qquad \qquad \rm{otherwise} \end{cases} \tag{2} Sc(p)={sconf(w)p∈R(w)1otherwise(2)
其中 p p p 代表在区域 R ( w ) R(w) R(w) 中的像素。目标 L L L 定义为,
(3) L = ∑ p S c ( p ) ⋅ ( ∣ ∣ S r ( p ) − S r ∗ ( p ) ∣ ∣ 2 2 + ∣ ∣ S a ( p ) − S a ∗ ( p ) ∣ ∣ 2 2 ) L = \sum_{p} S_c(p) \cdot (||S_r(p) - S^*_r(p)||^2_2 + ||S_a(p) - S^*_a(p)||^2_2) \tag{3} L=p∑Sc(p)⋅(∣∣Sr(p)−Sr∗(p)∣∣22+∣∣Sa(p)−Sa∗(p)∣∣22)(3)
其中 S r ∗ ( p ) S^*_r(p) Sr∗(p) 和 S a ∗ ( p ) S^*_a(p) Sa∗(p) 分别代表 region score 和 affinity map 的 pseudo-ground truth , S r ( p ) S_r(p) Sr(p) 和 S a ( p ) S_a(p) Sa(p) 分别表示预测的 region score和 affinity score。使用合成数据训练时,我们可以获得真的ground truth,所以 S c ( p ) S_c(p) Sc(p) 设置为1。
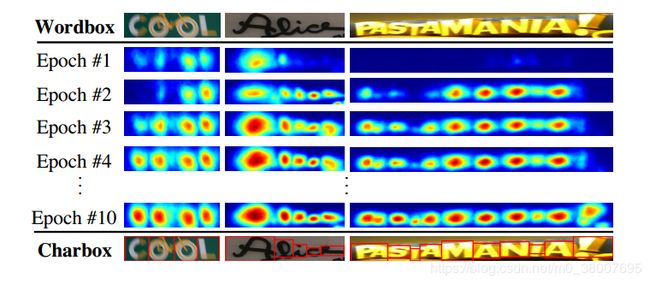
随着训练的进行,CRAFT模型可以更准确地预测字符,并且置信度得分 s c o n f ( w ) s_{conf}(w) sconf(w)也逐渐增加。图5 显示了训练期间的字符score map。在训练的早期,对于自然图像中不熟悉的文本,region score相对较低。该模型学习新文本的外观,例如不规则字体,以及与 SynthText 数据集具有不同数据分布的合成文本。
如果置信分数 s c o n f ( w ) s_{conf}(w) sconf(w) 低于0.5,估计的字符边界框应该忽视,因为在训练模型时,他们会产生不良影响。在这种情况下,我们假设单个字符的宽度是常数,并通过简单地将词区域 R ( w ) R(w) R(w) 除以字符数 l ( w ) l(w) l(w) 来计算字符级预测。然后, s c o n f ( w ) s_{conf}(w) sconf(w) 设置为 0.5 学习看不见的文本。
3.3 推理
在推理阶段,最终输出可以以各种形状传递,例如单词框或者字符框,以及其他多边形。对于像ICDAR这种数据集,评估方法是单词级的IoU,所以这里我们描述怎样通过一个简单且有效的后处理步骤把预测的 S r S_r Sr 和 S a S_a Sa 生成单词级的边框 Q u a d B o x QuadBox QuadBox。
生成边框的后处理总结如下。首先,覆盖图像的二进制图 M M M 初始化为0。如果 S r ( p ) > τ r S_r(p) > \tau_r Sr(p)>τr 或者 S a ( p ) > τ a S_a(p) > \tau_a Sa(p)>τa 则 M ( p ) M(p) M(p) 设置为1,其中 τ r \tau_r τr 是区域阈值, τ a \tau_a τa 是亲和力阈值。第二,在 M M M 上使用连通区域标记法(Connected Component Labeling,CCL)。最后,通过找到旋转的矩形来获得 Q u a d B o x QuadBox QuadBox,在封闭的最小区域连接对应于每个标签的组件。像OpenCV的函数 c o n n e c t e d C o m p o n e n t s connectedComponents connectedComponents 和 m i n A r e a R e c t minAreaRect minAreaRect 都可以使用。
请注意,CRAFT的一个优点是它不需要任何进一步的后处理方法,如非极大抑制(NMS)。 因为我们有通过CCL分隔的单词图像区域,因此单词的边界框仅由单个封闭的矩形框定义。另一方面,我们的字符连接过程是在像素级进行的,这与其他基于连接的方法不同,它们是依赖于明确地搜索文本组件之间的关系。
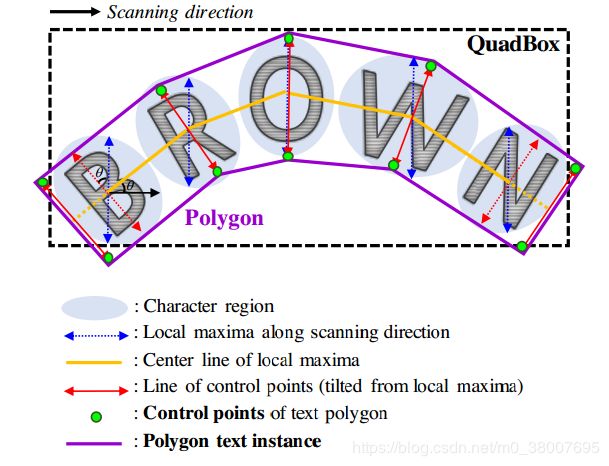
此外,我们可以围绕整个字符区域生成多边形,以有效地处理曲线文本。 多边形生成的过程如图7所示。第一步是沿扫描方向找到字符区域的局部最大值线,如图中的蓝色箭头。局部最大线的长度被相等地设置为它们中的最大长度,以防止最终的多边形结果变得不均匀。连接全部局部最大线的中点的线是中心线,在图中为黄色。然后旋转局部最大线以垂直于中心线,反映字符的倾斜角度,图中为红色。局部最大值线的端点是文本多边形的控制点的候选点。为了完全覆盖文本区域,我们沿着局部最大中心线向外移动两个最外边的倾斜的局部最大值线,形成最终控制点(绿点)。
4. 实验
4.1 数据集
ICDAR2013 (IC13)是在ICDAR 2013 Robust Reading Competition竞赛中对于场景文本检测提出的,包含高分辨率图像,229张训练图像和233张测试图像,包含英文文本。注释是单词矩形框。
ICDAR2015 (IC15)是在ICDAR 2015 Robust Reading Competition竞赛中附带的场景文本检测介绍的,包含1000张训练图像和500张测试图像,都包含英文文本。注释是单词四边形框。
ICDAR2017 (IC17)包含7200张训练图像,1800张验证图像,9000张测试图像,有9种语言的多语言场景文本检测。与IC15类似,在IC17中的文本区域也是通过4个顶点的四边形注释的。
MSRA-TD500 (TD500)包含500张自然图像,分为300张训练图像和200张测试图像,使用相机在室内和室外收集的。图像包含英文和中文脚本。 文本区域由旋转的矩形注释。
TotalText (TotalText)最近在ICDAR 2017上展出,包含1255个训练和300个测试图像。 它特别提供了弯曲的文本,这些文本由多边形和词级转录注释。
CTW-1500 (CTW)包含1000张训练和500张测试图像。每一张图像都有弯曲文本实例,通过14个点的多边形注释。
4.2 训练策略
训练流程包括两步:首先使用合成数据集(SynthText)训练50K个迭代,然后采用每个基准数据集来微调模型。在ICDAR 2015和ICDAR2017中的一些“DO NOT CARE”文本区域通过设置 s c o n f ( w ) = 0 s_{conf}(w) =0 sconf(w)=0 进行忽视。在全部的训练中使用 ADAM优化器。对于多GPU训练,训练和监督GPU是分开的,由监督GPU生成的 pseudo-GTs 存储在内存中。在微调期间,SynthText数据集也以1:5的比率使用,以确保字符区域肯定是分开的。为了滤除自然场景中的纹理文本,以 1 : 3 1:3 1:3 的比例使用在线硬负挖掘(On-line Hard Negative Mining)。此外,还应用了基本数据增强技术,如裁剪,旋转和/或颜色变化。
弱监督培训需要两种类型的数据;用于裁剪单词图像的四边形注释和用于计算单词长度的转录。满足这些条件的数据集是IC13,IC15和IC17。其他数据集(如MSRA-TD500,TotalText和CTW-1500)不符合要求。MSRA-TD500不提供转录,而TotalText和CTW-1500仅提供多边形注释。因此,我们仅在ICDAR数据集上训练CRAFT,并在没有微调的情况下对其他数据集进行测试。使用ICDAR数据集训练两种不同的模型。 第一个模型在IC15上进行训练,仅评估IC15。 第二个模型同时在IC13和IC17上进行训练,用于评估其他五个数据集。没有额外的图像用于训练。 微调的迭代次数设置为25k。
4.3 实验结果
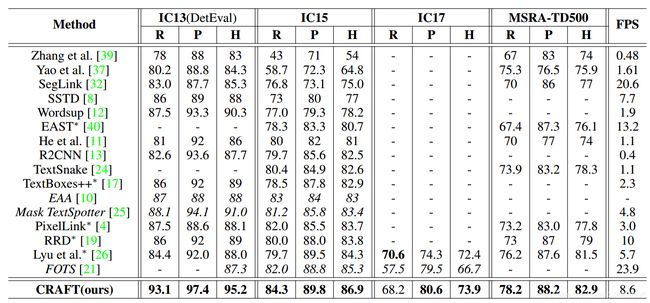
四边形数据集(ICDAR和MSRATD500) 所有实验均以单一图像分辨率进行。 IC13,IC15,IC17和MSRA-TD500中图像的较长边分别调整为960,2240,2560和1600。表1列出了ICDAR和MSRA-TD500数据集上各种方法的 h-mean 得分。为了与端到端方法进行公平比较,我们通过参考原始论文来获取其仅检测结果。我们在所有数据集上实现了最先进的表现。此外,由于简单而有效的后处理,CRAFT在IC13数据集上的运行速度为8.6 FPS,相对较快。
对于MSRA-TD500,提供的是行注释,包括框中单词之间的空格。 因此,需要组合单词框的后处理步骤。如果一个框的右侧和另一个框的左侧足够接近,则将两个框组合在一起。即使没有在TD500训练集上进行微调,CRAFT仍然优于表1所示的所有其他方法。
多边形数据集 (TotalText和CTW-1500)在TotalText和CTW-1500上直接训练模型是一项挑战,因为它们的注释形状为多边形,这使得在弱监督训练期间分割字符框的文本区域裁剪变得复杂化。因此,我们只使用了IC13和IC17的训练图像,并且没有进行微调以学习这些数据集提供的训练图像。在推理步骤中,我们使用region score通过后处理生成的多边形来应对提供的多边形类型注释。
这些数据集的实验也是以单一图像分辨率执行的。 TotalText和CTW-1500中图像的较长边分别调整为1280和1024。 多边形数据集的实验结果如表2所示。与其他方法相比,CRAFT的字符定位能力使我们能够在检测任意形状的文本方面实现更强大和更优越的性能。特别地,TotalText数据集具有各种变形,包括如图8所示的弯曲文本,对于这些变形,基于四边形的文本检测器的推断是不可行的。因此,可以在这些数据集上评估非常有限数量的方法。
在CTW-1500数据集的情况下,两个困难的特征共存,即提供的行注释和任意形状的多边形。为了在这种情况下帮助CRAFT,我们称之为LinkRefiner的小型连接细化网络与CRAFT结合使用。LinkRefiner的输入是regoin score,affinity score 和CRAFT的中间 feature map 的拼接,输出是针对长文本调整的refined affinity score(精确亲和力分数)。为了组合字符,使用 refined affinity score 代替原始的affinity score,然后生成多边形的方式与TotalText生成多边形的方式相同。固定住CRAFT,只在CTW-1500数据集上训练 LinkRefiner。 LinkRefiner的详细实现在补充材料中。如表2所示,所提出的方法实现了最先进的性能。

4.4 讨论
尺度变化的鲁棒性 我们仅在所有数据集上进行单尺度实验,即使文本的大小非常多样化。这与大多数其他方法不同,他们依靠多尺度测试来处理尺度变化问题。这个优势来自于我们方法是定位单个字符而不是整个文本。相对较小的感受野足以覆盖大图像中的单个字符,这使得CRAFT在检测尺度变化文本时具有鲁棒性。
多语言问题 IC17数据集包含孟加拉语和阿拉伯语字符,这些字符未包含在合成文本数据集中。 而且,两种语言都难以单独分割成字符,因为每个字符都是很草地写成的。因此,我们的模型无法区分孟加拉语和阿拉伯语,以及拉丁语,韩语,中文和日语。在东亚字符的情况下,它们可以很容易地以恒定的宽度分开,这有助于通过弱监督训练模型的高性能。
与端到端方法的比较 我们的方法仅使用 ground truth 实例框进行检测,但与其他端到端方法相当,如表3所示。通过对失败案例的分析,我们期望我们的模型能够从识别结果中受益,特别是当 ground truth 词语被语义分离而不是视觉线索时。
泛化能力 我们的方法在3个不同的数据集上实现了最新的性能,无需额外的微调。这表明我们的模型能够捕获文本的一般特征,而不是过度拟合特定的数据集。
5. 结论
我们提出了一种名为CRAFT的新型文本检测器,它可以检测单个字符,即使没有给出字符标注。 所提出的方法提供了字符 region score 和字符affinity score,它们一起以自下而上的方式完全覆盖各种文本形状。由于提供了字符级注释的真实数据集很少,我们提出了一种弱监督学习方法,可以从中间模型生成 pseudo-ground truthes。CRAFT在大多数公共数据集上展示了最先进的性能,并通过显示这些性能而无需微调来展示泛化能力。作为我们未来的工作,我们希望以端到端的方式使用识别模型训练我们的模型,以了解CRAFT的性能,稳健性和普遍性是否转化为更好的场景文本定位系统。
CTW-1500数据集的 LinkRefiner
CTW-1500数据集只提供了多边形注释,没有文本转录。而且只有行级注释,没有空格。这远非我们对亲和力的假设,即对于在它们之间具有空格的字符,亲和力的分数为零。
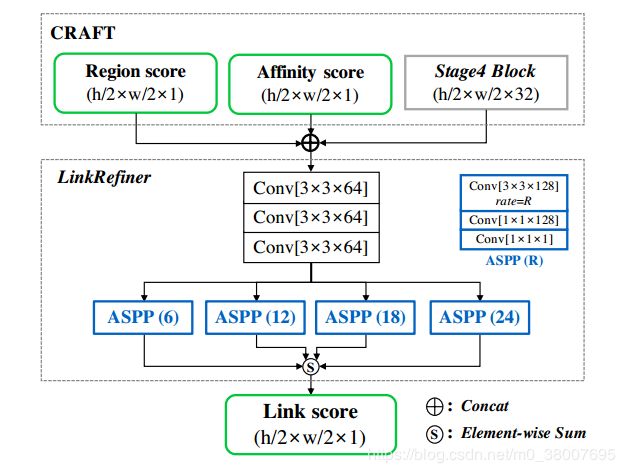
为了从检测到的字符中获取单个长的多边形,我们使用一个网络进行连接细化,即所谓的LinkRefiner。结构如图9所示。LinkRefiner的输入是 region score 和 affinity score 和网络中间 feature map的拼接,中间feature map是原始CRAFT模型的Stage4的输出。采用ASPP来确保用于将字符和单词组合到统一文本行的大感受野。
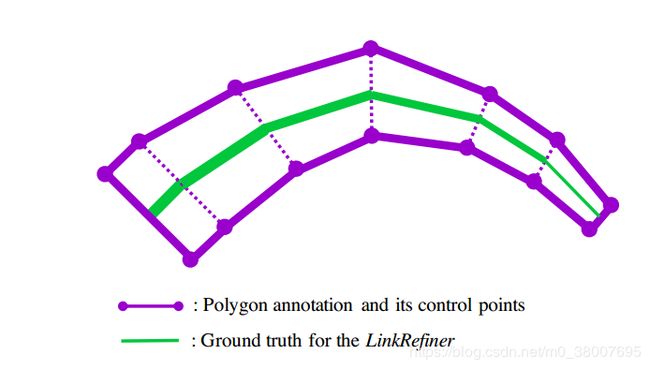
对于 LinkRefiner 的 ground truth,简单地在注释多边形的成对控制点的中心之间绘制线,这类似于中使用的文本线生成。每条线的宽度与成对控制点之间的距离成比例。LinkRefiner的ground truth生成如图10所示。这个模型的输出称为 link score。对于训练,固定CRAFT不变,只在CTW1500数据集上训练Linkrefiner。
训练后,我们得到模型产生的输出,即region score,affinity score和 link score。link score被用来代替 affinity score,文本多边形完全通过与TotalText相同的过程获得。CRAFT模型定位单个字符,LinkRefiner模型将字符以及由空格分隔的单词组合在一起,用来做CTW1500评估。CTW-1500的结果如图11所示。通过所提出的方法成功地检测到有挑战的具有长文本和弯曲文本。此外,利用我们的多边形表示,可以将曲线图像校正为直文图像,这也在图11中示出。我们相信这种整改能力可以进一步用于识别任务。



对于每一类,输入图像(上),region score(中左),link score(中右),弯曲文本的修正多边形结果(底部,箭头下方)。请注意,未在CTW-1500数据集中呈现亲和力分数并且未使用它们。