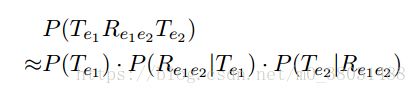关于关系抽取(Relation Extraction)的三篇论文
关系抽取被广泛的应用于NLP领域的多个任务中,而远程监督方法的兴起为关系抽取添加了一把双刃剑。一方面远程监督可以基于少量的标注语料自动的扩展出大量的标注数据。另一方面,错误标签带来的大量无关噪声也为关系抽取的准确度带来了不小的挑战。
本文从三篇NLP顶级会议论文出发来分析解决这个问题。如图一所示,我们的挑战主要来自两个方面。首先如何将输入句子向量化的表示,采用何种算法或者手段进行特征提取,如何将word embedding之后的句子进行提取特征,使得句子数字化的同时而又最大程度的保留了原始信息。其次,我们如何解决错误标签问题,使得大量带噪声的数据对我们实验结果的影响最小,如果不对错误标签进行消噪的话,我们特征提取的越准确,那么可能对我们分类器的错误影响也就越大。

Distant Supervision for Relation Extraction via Piecewise
Convolutional Neural Networks (EMNLP 2015)
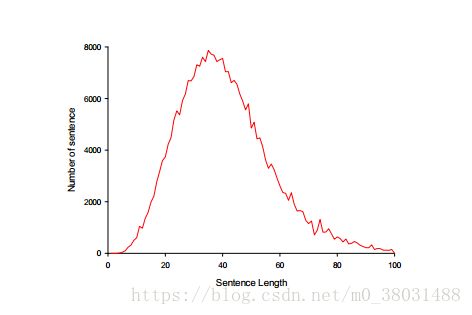
PCNN提出的原因:McDonald and Nivre(2007) 研究发现句法分析的准确性随着句子长度的增加而明显的下降。而我们的实验数据如下图所示往往又是较长的句子。
Vector Representation
Word Embeddings :使用word2vector进行单词短语的向量化表示
Position Embeddings :对于一个包含两个实体的句子,我们对每个单词加上位置信息,即该单词到实体1的距离和到实体2的距离。
Vector:d = dw + dp ∗2
Convolution
在关系抽取特征提取这块卷积神经网络被青睐的原因。我们所处理的输入是一个仅包含一对已被标记实体的句子,且基于远程监督学习的大胆假设这对实体仅表达一个关系。我们可以理解为输入为一个向量矩阵,而输出为一个实值概率。所以我们仅需从所有的局部特征中预测出全局关系即可,应用卷积神经网络就成为了一个很自然的想法了。但对于关系抽取中联合学习的一个变种就不太适用了,其根本想法是将一个输入句子转化为一个带标签的序列,在利用规定好的标签规则完成关系的确定。所以其本质是序列到序列的训练,使用LSTM会获得良好的表现。
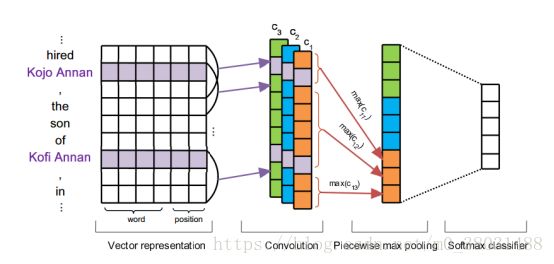
我们对句子的Vector Representation 进行卷积操作,W代表卷积核,q代表所对应的输入,j-w+1:j代表所对应的输入的区域

对输入句子进行不同角度的特征提取,我们使用不同的卷积核来完成此操作,本文中卷积核的数量为3。

Piecewise Max Pooling
我们根据两个实体将句子分成三段,对每段分别进行最大池化操作。
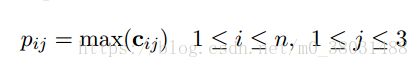
最后进行非线性转化为向量g,它的维度大小为3*n,n为卷积核的个数。

Neural Relation Extraction with Multi-lingual Attention (ACL2017)
Multi-lingual data will benefit relation extraction for the following two reasons:
1. Consistency.
2. Complementarity.
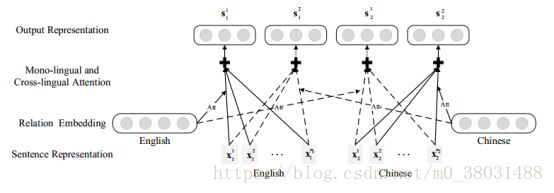
Sentence Encoder :
Input Representation :
word embedding
position embedding
Convolution, Max-pooling and Non-linear Layers :(PCNN)
Multi-lingual Attention
Mono-lingual Attention :

其中αijαji是对应句子向量xijxji的Attention权值,其计算方法如下:
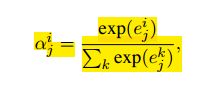
e为衡量句子向量与关系r之间的关联度:
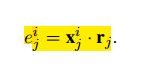
Cross-lingual Attention
假设j与k分别代表两种不同语言,那么cross-lingual representation Sjk Sjk计算方法如下:
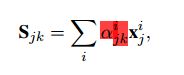
其中α是对应句子向量x的Attention权值,其计算方法如下
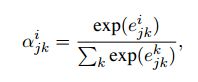
其中e为衡量句子向量与关系r之间的关联度,其计算方式为:
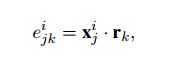
也就是说我们在第k中语言中的句子向量加的权重值不是在第k中语言中生成的权重值,而是在第j种语言中的权重值。通俗的讲我们认为在汉语中这个句子对最后分类器的影响大不大不是由汉语中的权重来控制的,而是由该句子在英文中的翻译句子在英文语料库中占的权重来控制的。宏观的来讲这反应了语言的一致性,我们认为一个句子表达某种关系不应当是受语言种类影响的,若中文中一个句子表达某种关系,并且对应的英文翻译也表达这种关系,那么我们认为它才是正真的表达此关系。
Prediction
对于每一个实体对以及对应的句子集在m中语言中,我们通过multi-lingual attention可以获得m*m的向量{Sjk|j,k∈(1,...,m)Sjk j,k∈(1,...,m)}(一种语言的句子向量对应m中语言的权重矩阵),当j = k时,即为mono-lingual attention vectors,不相等时cross-lingual attention vectors.
![]()
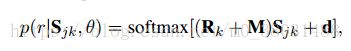
Global Normalization of Convolutional Neural Networks
for Joint Entity and Relation Classification(EMNLP 2017)
任务:给定一个句子和两个查询实体,论文中的模型识别出实体类型和它们的对应关系。
Input :
识别实体类型:以某一实体为界限将输入句子分成三部分。
识别实体间的关系类型:两个实体将输入句子分成五个部分。

Sentence Representation :
对实体:训练一个CNN层(卷积核的尺寸较context的小)
对上下文:训练另一个CNN层(卷积核的尺寸较实体的大)

在卷积之后,我们使用k-max pooling对实体和上下文进行连接。
concatenated vector Cz ∈R(Cz ) z ∈ {EC, RE}
![]()
Global Normalization Layer
Vz:the size of the output classes N = Nec+ Nre:
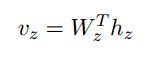
For a sentence classification task, the input sequence for the CRF layer is not inherentely clear. Therefore, we propose to model the joint entity and relation classification problem with the following sequence of scores
![]()