23REPEAT方法:软工顶会ICSE ‘23 大模型在代码智能领域持续学习 代表性样本重放(选择信息丰富且多样化的示例) + 基于可塑权重巩固EWC的自适应参数正则化 【网安AIGC专题11.22】
Keeping Pace with Ever-Increasing Data:Towards Continual Learning of Code Intelligence Models
- 写在最前面
- 论文名片
- nlp中的命名实体识别NER和关系抽取任务RE的启发
- 课堂讨论
-
- 噪声数据排除
- 基于可塑权重巩固EWC的自适应参数正则化
- 代码克隆检测准确率比较低
- 绪论
-
- 代码生成大模型
-
- PPT学习,连贯动画感(方框是后期添加的)
- 研究方法与思路
-
- 持续学习
- REPEAT方法 整体方案
- 代表性样本重放
- 可塑权重巩固(EWC)
-
- 基于可塑权重巩固(EWC)的自适应参数正则化
- 实验方案与结果
-
- 数据集
- 实验设置
- 基线对比
- 泛化能力
-
- `为什么漏洞检测和代码克隆任务上的准确率这么低`?
- 消融实验
- 创新和贡献
写在最前面
本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,本次专题主题为大模型。
黄邕灵同学@potato&&tomato:分享了Keeping Pace with Ever-Increasing Data:Towards Continual Learning of Code Intelligence Models《跟上不断增长的数据:迈向代码智能模型的持续学习》
软工顶会ICSE ‘23: Proceedings of the 45th International Conference on Software Engineering
论文主题:大模型在代码智能领域的应用,特别是它们如何持续学习并适应新数据。
将论文阐述得深入浅出,受益匪浅
这门课中最细节的PPT,对公式的每个符号都进行了解释,观感特别友好
论文:https://arxiv.org/pdf/2303.16749.pdf
论文名片
- 代码智能模型在持续学习环境中面临的挑战,特别是如何使这些模型能够从不断增长的数据集中学习而不会忘记旧知识。这种学习的难点在于防止所谓的“灾难性遗忘”,即模型在学习新数据时遗忘旧数据的情况。
以往的代码智能研究通常以离线方式在固定数据集上训练深度学习模型。然而,在实际场景中,新的代码仓库不断涌现,所携带的新知识有利于向开发者提供最新的代码智能服务。
在本文中,我们针对以下问题:如何使代码智能模型能够从不断增长的数据中不断学习?这里的一个主要挑战是灾难性的遗忘,这意味着模型在从新数据集学习时很容易忘记从以前的数据集中学习的知识。
- 提出了REPEAT的新方法,该方法结合了
代表性示例重放、自适应参数正则化来解决灾难性遗忘问题。
通过这种方式,模型能够保留重要的旧知识,同时也学习新数据集提供的新知识。
为了应对这一挑战,我们提出了REPEAT,这是一种持续学习代码智能模型的新方法。具体来说,REPEAT通过
代表性示例重放、自适应参数正则化解决了灾难性的遗忘问题。
代表性示例重放组件在每个数据集中选择信息丰富且多样化的示例,并使用它们定期重新训练模型。
自适应参数正则化组件可识别模型中的重要参数,并自适应地惩罚其更改,以保留之前学习的知识。
- REPEAT方法在提高模型对新数据的适应性的同时,有效地减轻了灾难性遗忘问题。
我们在三个代码智能任务上评估了所提出的方法,包括代码摘要、软件漏洞检测和代码克隆检测。大量实验表明,REPEAT在所有任务上的表现始终优于基线方法。例如,REPEAT在代码汇总、漏洞检测和克隆检测方面分别将传统的微调方法提高了1.22、5.61和1.72。
nlp中的命名实体识别NER和关系抽取任务RE的启发
REPEAT方法提供了一系列值得借鉴的概念和技术,这些可以应用于NLP中的NER和关系抽取任务,以改进模型的持续学习能力、泛化能力和准确性。
-
持续学习
- 适应性:NLP系统需要能够适应语言的持续变化,如新词汇、新的命名实体或新的语言用法。REPEAT方法中的持续学习,涉及处理新兴词汇和不断变化的语料。
- 数据多样性:REPEAT方法中对数据多样性的关注,提示了对不同领域和语言风格的文本进行训练的重要性。
-
灾难性遗忘的处理
- 模型泛化:在NER和关系抽取中,模型在接触新数据时也面临着灾难性遗忘的问题。REPEAT方法通过
保持重要信息的、同时学习新信息的策略提供了思路。 - 参数正则化:REPEAT使用的
自适应参数正则化可以被用于调整模型中参数的更新,以维持对旧知识的记忆。
- 模型泛化:在NER和关系抽取中,模型在接触新数据时也面临着灾难性遗忘的问题。REPEAT方法通过
-
代表性样本的重要性
- 数据选择:REPEAT方法中
代表性示例重放的概念,可用于优化NER和关系抽取任务的数据选择,即选择那些能够提供最大信息量的样本进行训练。 - 减少过拟合:选择
多样化且信息丰富的样本可以帮助模型更好地泛化,减少对特定数据集的过拟合。
- 数据选择:REPEAT方法中
-
多任务的应用与评估
- 跨任务学习:REPEAT方法展示了在多个任务上成功应用一个统一方法的可能性,即可以探索在不同但相关的NLP任务上应用统一的持续学习策略。
- 多任务评估:REPEAT方法在多个任务上的评估展示了进行综合性能评估,在多个层面和多个标准上评估模型性能。
课堂讨论
噪声数据排除
噪声数据,训练损失比较大
选择训练损失更小的样本
三个不同任务,用到了三个数据集
数据集划分成了五个子数据集
特征差别不大
基于可塑权重巩固EWC的自适应参数正则化
旧模型训练好的参数,新模型上再次训练
重要参数尽可能小的改变:计算每个参数的变化值,限制参数变化
代码克隆检测准确率比较低
大模型结构不太一样,
codebert基于编码器,在第一个任务上更擅长
T5的摘要更合适
REPEAT方法在漏洞检测和代码克隆任务上准确率较低可能是由几个因素造成的,了解这些因素有助于进一步优化REPEAT方法,或开发更适合这些特定任务的新方法:
-
任务本身的难度:漏洞检测和代码克隆是代码智能领域中比较复杂的任务。它们需要模型对代码的深层结构和潜在的安全漏洞有很高的理解能力。这些任务往往涉及对细微差别的识别,比如在代码克隆检测中区分微妙的代码差异、或者在漏洞检测中识别潜在的安全风险。
-
数据集的质量和多样性:如果用于训练和测试模型的数据集不够丰富或者质量不高,模型的性能可能会受到影响。在漏洞检测和代码克隆任务中,高质量、多样化的数据集对于训练有效的模型至关重要。
-
模型的泛化能力:这些任务可能要求模型在不同的编程语言和代码库中具有较好的泛化能力。如果模型在训练过程中未能充分学习到可以泛化到新情况的特征,其性能可能会降低。
-
灾难性遗忘的挑战:尽管REPEAT方法旨在减轻灾难性遗忘问题,但在实际应用中,完全避免模型在学习新任务时忘记旧任务的知识仍然是一个挑战。特别是在复杂任务如漏洞检测和代码克隆中,保持之前学习成果的难度可能更大。
-
特定任务的特性:每个代码智能任务都有其独特的特性和挑战。REPEAT方法虽然是一个通用的持续学习方法,但它可能不完全适用于某些特定任务的特定需求。
绪论
代码生成大模型

大模型是一种复杂的计算机程序,它可以学习和适应新信息。在软件开发领域,这些模型帮助自动化许多任务,比如:
◆ 文本生成代码
根据自然语言描述生成代码
◆ 代码摘要
以自然语言描述生成源代码摘要
◆ 代码翻译
将一种编程语言编写的代码转换为另一种同功能编程语言的过程
◆ 代码漏洞检测
要求 LLM 检测提示中提供的源代码中的缺陷
◆ 代码克隆检测
检测存在于代码库中两个及以上的相同或者相似的源代码片段
◆ 代码重构、代码补全、代码修复、代码搜索…
PPT学习,连贯动画感(方框是后期添加的)

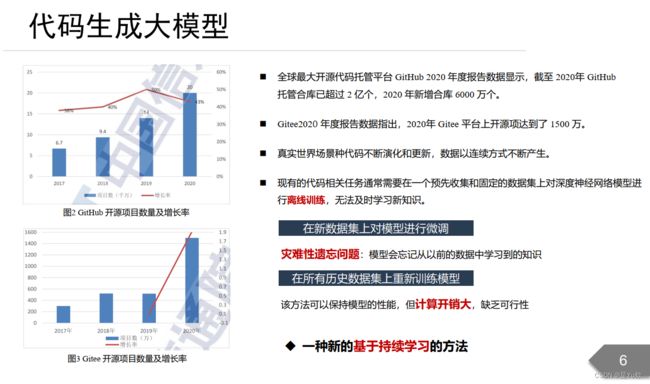
如何维护代码智能模型,使模型能够持续学习,随时间变化的知识,不断更新迭代?
- 在新数据集上对模型进行微调
灾难性遗忘问题:模型会忘记从以前的数据中学习到的知识、 - 在所有历史数据集上重新训练模型
该方法可以保持模型的性能,但计算开销大,缺乏可行性
一种新的基于持续学习的方法
研究方法与思路
持续学习
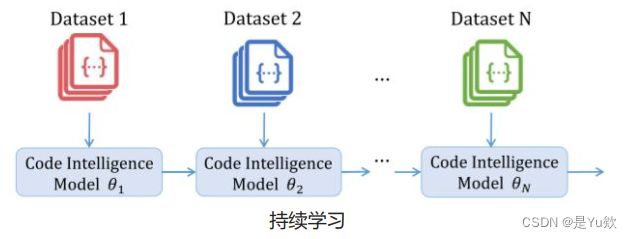
当新的代码不断出现时,模型需要不断学习这些新信息。但这里有一个挑战:当模型学习新信息时,它可能会“忘记”以前学到的内容。这就像我们在学习新语言时可能会忘记之前学过的语言。
- 基于情景记忆的方法
◼ 基于情景记忆的方法通过保存一些之前任务的样例进行记忆回放来缓解灾难性遗忘,这些样本/伪样本既可用于联合训练,也可用于约束新任务损失的优化,以避免干扰先前任务。 - 基于正则化的方法
◼ 通过为损失增添额外损失项,对权重进行约束,保护巩固已学习的知识,但这样可能会制衡新任务的学习性能,无法很好的权衡新旧任务。该类方法不需要保存任何以前的数据,只需要对每个任务进行一次训练。但是,随着任务数量的不断增加,可能导致特征漂移现象。 - 基于动态结构的方法
◼动态的对网络结构进行调整,使其适应新的任务,也可以扩展网络结构来学习新的任务,使用更多的神经元或网络层。然而随着任务数量的不断增多,模型结构会不断变大,因此这样的方法无法应用到大规模数据中,影响其在实际场景中的使用。
另外,该类方法也不能从任务之间的正向迁移中获益。
REPEAT方法 整体方案
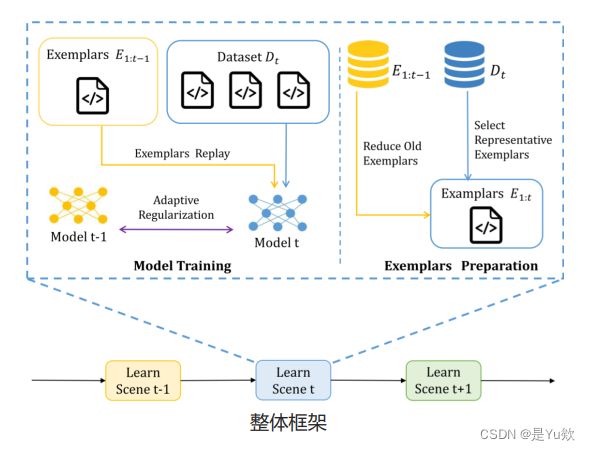
为了解决上述挑战,研究人员提出了一个称为“REPEAT”的新方法。这个方法通过两个关键步骤来帮助模型更好地学习:
- 选择性记忆:REPEAT从以前的数据中挑选最有价值的信息,帮助模型记住关键内容。
- 平衡学习:REPEAT确保在学习新内容的同时,不会丢掉老知识。
针对代码智能数据集中存在各种数据模式和噪声数据的问题,提出一种新的代表性样本重放方法,保留数据集中更具信息量的多样性样本。
考虑到软件开发中存在较多的代码重用,提出了一种基于数据集之间共享知识的自适应参数正则化机制来控制参数更新的程度。
在三个代码智能任务上与两个先进的模型进行了对比,实验结果证明该方法对于缓解灾难性问题具有较好效果。
代表性样本重放

针对样本大小有限,如何缓解模型对保存的样本过拟合并忘记其他样本的问题
- 多样性样本选择
使用TF-IDF(词频-逆文档频率)算法向量化代码样本
使用K-means算法将样本划分为K类,从每个类中分别选取样本 - 信息性样本选择
噪声数据具有较大的训练损失
滤除高损失样本,保留具有高信息量的样本数据 - 样本移除
确定当前数据集中的代表性样本后,从先前的数据集中移除相应数量样本,以保持数据集大小恒定
可塑权重巩固(EWC)

利用重要度矩阵,即: Fisher信息矩阵,度量网络参数对旧任务的重要程度;
L2正则化用于在训练新任务B时对完成任务A重要的网络
计算两个数据集之间的相似度,相似度越大,新知识权重越小。
因为旧模型中已经学习到了很多相似的知识
基于可塑权重巩固(EWC)的自适应参数正则化
- No penalty
训练完猫狗识别后,模型在猫狗识别的任务上有很不错的表现,此时直接用该模型继续训练狮虎识别模型
学完任务B后将会遗忘任务A - L2正则化
L2正则化倾向于生成更小、更分 散的权重向量,鼓励分类器考虑 所有输入维数,防止模型过拟合。
L2正则项没有考虑不同参数对任务的重要性 - EWC
让模型参数受限地变动,限制对任务A 特别重要的参数,改变非重要参数。参数矩阵里面,某些参数对猫狗识别非常重要,在训练狮虎识别时,记下这些参数原本的值,加一个损失函数阻碍它们的变化,模型在样本空间中,猫狗识别的数据样本区域分类器的超平面变化不大。
通过控制优化方向,使得其能够处于两个区域的交集部分,在旧任务与新任务上都有良好的性能。
实验方案与结果
通过一系列实验,研究人员发现REPEAT方法比旧方法更有效。它不仅帮助模型更好地记住旧信息,还提高了在新任务上的表现。
数据集
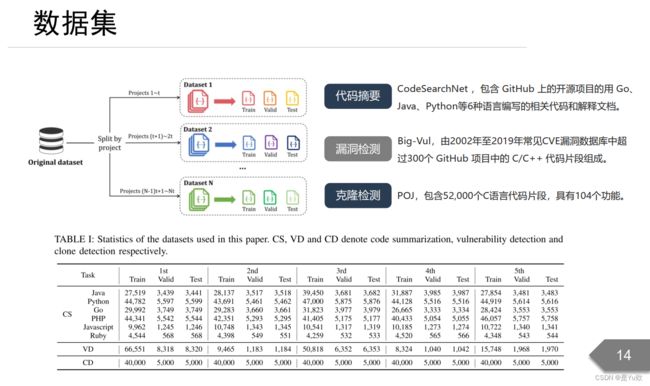
- 代码摘要
CodeSearchNet ,包含 GitHub 上的开源项目的用 Go、Java、 Python等6种语言编写的相关代码和解释文档。 - 漏洞检测
Big-Vul,由2002年至2019年常见CVE漏洞数据库中超过300个 GitHub 项目中的 C/C++ 代码片段组成。 - 克隆检测
克隆检测 POJ,包含52,000个C语言代码片段,具有104个功能。
实验设置

- 预训练模型
◼ CodeBERT: 2020年微软&合工大提出的NL-PL(自然语言-编程语言)双模预训练模型
◼ CodeT5 : 2021年提出的编码器-解码器模型,它以不同前缀的序列到序列范式表述所有任务,并在各种代码智能任务上实现了最先进的性能。 - Baseline
◼ FT:直接针对每个新任务对模型进行微调,持续学习领域的下届基线系统。
◼ EMR :基于样本重放的方法,使用从以前的任务中随机选择的旧样本重新训练模型。
◼ EWC:采用弹性权重固结来规范参数的变化,每个参数的重要性由Fisher矩阵确定。
◼ Upper:用当前数据集和所有历史数据集的数据训练模型,该方法可以用于提供上届参考 - 评估指标
代码摘要、漏洞检测/代码克隆、持续学习
基线对比
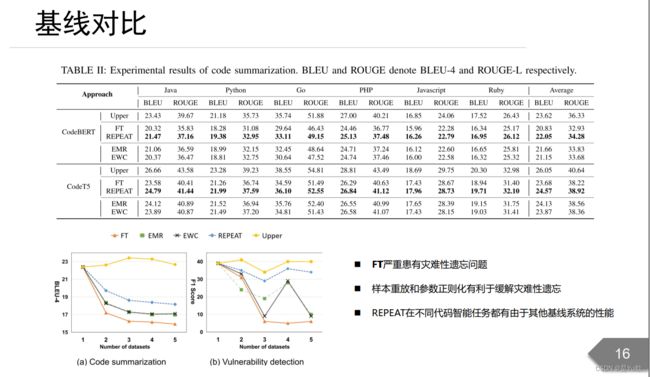
◼ FT严重患有灾难性遗忘问题
◼ 样本重放和参数正则化有利于缓解灾难性遗忘
◼ REPEAT在不同代码智能任务都有由于其他基线系统的性能
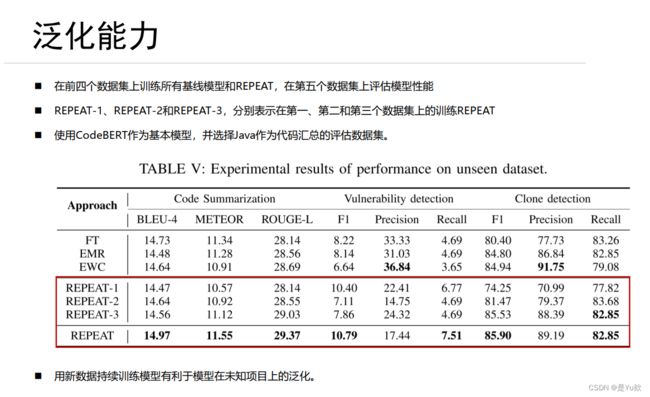
泛化能力
◼ 在前四个数据集上训练所有基线模型和REPEAT,在第五个数据集上评估模型性能
◼ REPEAT-1、 REPEAT-2和REPEAT-3,分别表示在第一、第二和第三个数据集上的训练REPEAT
◼ 使用CodeBERT作为基本模型,并选择Java作为代码汇总的评估数据集。
◼ 用新数据持续训练模型有利于模型在未知项目上的泛化。
为什么漏洞检测和代码克隆任务上的准确率这么低?
REPEAT方法在漏洞检测和代码克隆任务上准确率较低可能是由几个因素造成的,了解这些因素有助于进一步优化REPEAT方法,或开发更适合这些特定任务的新方法:
-
任务本身的难度:漏洞检测和代码克隆是代码智能领域中比较复杂的任务。它们需要模型对代码的深层结构和潜在的安全漏洞有很高的理解能力。这些任务往往涉及对细微差别的识别,比如在代码克隆检测中区分微妙的代码差异、或者在漏洞检测中识别潜在的安全风险。
-
数据集的质量和多样性:如果用于训练和测试模型的数据集不够丰富或者质量不高,模型的性能可能会受到影响。在漏洞检测和代码克隆任务中,高质量、多样化的数据集对于训练有效的模型至关重要。
-
模型的泛化能力:这些任务可能要求模型在不同的编程语言和代码库中具有较好的泛化能力。如果模型在训练过程中未能充分学习到可以泛化到新情况的特征,其性能可能会降低。
-
灾难性遗忘的挑战:尽管REPEAT方法旨在减轻灾难性遗忘问题,但在实际应用中,完全避免模型在学习新任务时忘记旧任务的知识仍然是一个挑战。特别是在复杂任务如漏洞检测和代码克隆中,保持之前学习成果的难度可能更大。
-
特定任务的特性:每个代码智能任务都有其独特的特性和挑战。REPEAT方法虽然是一个通用的持续学习方法,但它可能不完全适用于某些特定任务的特定需求。
消融实验
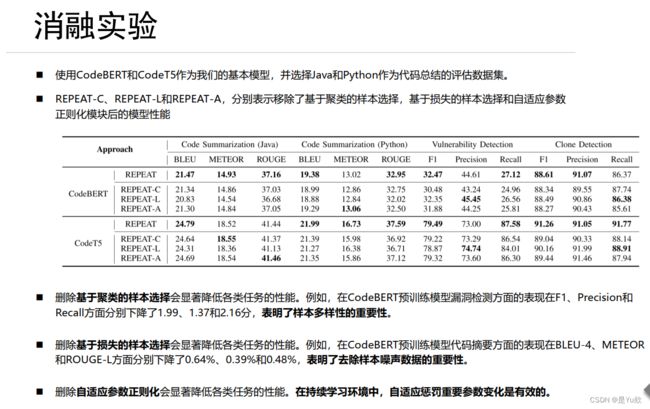
◼ 使用CodeBERT和CodeT5作为我们的基本模型,并选择Java和Python作为代码总结的评估数据集。
◼ REPEAT-C、 REPEAT-L和REPEAT-A,分别表示移除了基于聚类的样本选择,基于损失的样本选择和自适应参数正则化模块后的模型性能。
◼ 删除基于聚类的样本选择会显著降低各类任务的性能。例如,在CodeBERT预训练模型漏洞检测方面的表现在F1、 Precision和Recall方面分别下降了1.99、 1.37和2.16分, 表明了样本多样性的重要性。
◼ 删除基于损失的样本选择会显著降低各类任务的性能。例如,在CodeBERT预训练模型代码摘要方面的表现在BLEU-4、 METEOR和ROUGE-L方面分别下降了0.64%、 0.39%和0.48%, 表明了去除样本噪声数据的重要性。
◼ 删除自适应参数正则化会显著降低各类任务的性能。 在持续学习环境中,自适应惩罚重要参数变化是有效的。
创新和贡献
◼ 第一个在持续学习场景下探索代码智能模型性能的工作。
◼ 为了防止代码智能模型灾难性地遗忘所学知识,提出了一种新的基于持续学习的方法REPEAT,该方法采用了代表性示例重放和自适应参数正则化技术。
◼ 使用两个最先进的模型对三个代码智能任务进行了广泛的实验。实验结果证明了重复记忆的有效性及其减轻灾难性遗忘问题的能力。