【高性能MySQL】第六章查询性能优化 终 自定义函数 案例 总结
6.7.9使用用户自定义变量
用户自定义变量是一个用来存储内容的临时容量,在连接mysql的整个过程中都存在
![]() 可以使用=建议是:=
可以使用=建议是:=
属性和限制:
在一个连接内有效,不能做连接间的通信
5.0前,大小写敏感,注意不同版本兼容性
使用自定义变量的查询,无法使用查询缓存
优化器可能把这些变量优化掉:代码不按预想出牌
赋值符合:=优先级非常低,表达式应使用明确的括号
赋值的顺序和时间点并不总是固定的,依赖于优化器的决定
不能在使用常量或标识符的地方使用自定义变量,如表名 列名 和limit子句中
如果使用连接池或持久化连接,自定义变量可能让看起来没有关系的代码发生交互(bug)
不能显示声明自定义变量的类型(动态类型),确定未定义变量的具体类型的时机在不同,可通赋值定类型
用处:详见book
优化排名语句()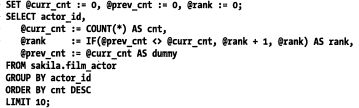 三变量:当前排名 前一排名 演员参演数量
三变量:当前排名 前一排名 演员参演数量
避免重复查询刚刚更新的数据![]() 第二个不走库
第二个不走库
统计更新和插入的数量:![]() 由于冲突导致更新时变量自增,*0不影响更新内容
由于冲突导致更新时变量自增,*0不影响更新内容
确定取值顺序: 不希望对子句的执行结果有影响却又要完成变量赋值
不希望对子句的执行结果有影响却又要完成变量赋值
编写偷懒的UNION: 第一表无数据才去第二,greatest免返额外数据
第一表无数据才去第二,greatest免返额外数据
优化器将其看作常量,so将其1、放出least等函数中,2、查询被执行前检查变量是否被赋值
6.8案例学习
6.8.1构建一个队列表
避免使用select for update
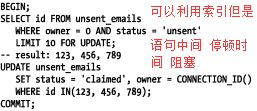
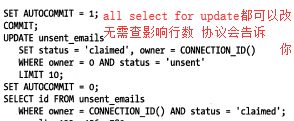
原则:
尽量少做事情,可以的话不做任何事情,尽量不要轮询
尽可能快地完成需要做的事情,尽量使用update 代替 select for update再写update的写法
某些查询是无法优化的,考虑使用不同的查询或不同的策略去实现相同的目的
有时最好的办法是将任务队列从数据库迁移出来,redis是很好的队列容器,memcached也不错
6.8.2计算两点间距离
建议使用PostgreSQL做复杂的空间信息
优化策略:
需要时,尽可能让应用程序完成一些计算
6.8.3使用用户自定义函数
大数据,使用Yves Trudeau编写计算程序(使用SSE4.2指令集)以后台程序的方式运行在通用服务器上,编写用户自定义函数,通过简单网络通信协议和前面程序做交互
6.9总结
想要写好一个查询,必须理解schema设计、索引设计等,反之亦然
mysql如何访问表和索引:
理解查询是如何被执行及时间都消耗在哪些地方(响应时间)
理解解析和优化过程的知识
优化三管齐下:不做 少做 快速做
对了、分区和缓存 也是优化的帮手哦
拾遗:
1、on duplicate key update 插入更新【源】【源】【源】
若数据表中存在相同主键的记录,就更新该记录(执行更新操作, UPDATE 后的操作),否则就插入一条新的记录,保证操作的原子性和数据的完整性;MySQL的特有语法,并不是SQL标准语法
INSERT INTO TABLE (a,c) VALUES (1,3) ON DUPLICATE KEY UPDATE c=c+1;
//如果没有记录则执行后面的update 操作,如果行作为新记录被插入,则受影响行的值为1
UPDATE TABLE SET c=c+1 WHERE a=1;replace:
在执行REPLACE后,系统返回了所影响的行数,如果返回1,说明在表中并没有重复的记录,如果返回2,说明有一条重复记录,系统自动先调用了DELETE删除这条记录,然后再记录用INSERT来插入这条记录。如果返回的值大于2,那说明有多个唯一索引(REPLACE将考虑每一个唯一索引,并对每一个索引对应的重复记录都删除,然后插入这条新记录。)有多条记录被删除和插入。
mysql之replace和ON DUPLICATE KEY UPDATE的区别(1)在没有主键或者唯一索引重复时,replace与insert .. on deplicate udpate相同。
(2)在主键或者唯一索引重复时,replace是delete老记录,而录入新的记录,如果replace语句的字段不全的话,有些原有的字段值自动填充为默认值。而insert .. duplicate update则只执行update标记之后的sql,从表象上来看相当于一个简单的update语句,它保留了所有字段的旧值,只更新update后面的语句,而replace没有保留旧值,直接删除再insert新值。
(3)从底层执行效率上来讲,replace要比insert .. on duplicate update效率要高,但是在写replace的时候,字段要写全,防止老的字段数据被删除。
2、GREATEST和LEAST函数都使用N个参数,并分别返回最大和最小值:
GREATEST(value1, value2, ...);
LEAST(value1,value2,...);
https://blog.csdn.net/jaryle/article/details/75909531