1. 问题
在IOS系统下有这么两个语句:
Arch64:
"fmla v16.4s, v14.4s, v0.4s \n"
v0 unsigned char __attribute__((ext_vector_type(16)))
(0x00, 0x00, 0x80, 0x3f,
0x00, 0x00, 0x80, 0x3f,
0x00, 0x00, 0x80, 0x3f,
0x00, 0x00, 0x80, 0x3f)
v14 unsigned char __attribute__((ext_vector_type(16)))
(0x00, 0x30, 0x97, 0x42,
0x00, 0x00, 0x86, 0x40,
0x00, 0xc0, 0x16, 0x42,
0x00, 0xc0, 0x59, 0x42)
v16 unsigned char __attribute__((ext_vector_type(16)))
(0x00, 0x30, 0x97, 0x42,
0x00, 0x00, 0x86, 0x40,
0x00, 0xc0, 0x16, 0x42,
0x00, 0xc0, 0x59, 0x42)
v0跟v14乘加到v16上,但是v16的值却跟v14一样,为何?
Arch32:
"vmla.u32 q10, q2, q13 \n"
q13 unsigned char __attribute__((ext_vector_type(16)))
(0x00, 0x00, 0x80, 0x3f,
0x00, 0x00, 0x80, 0x3f,
0x00, 0x00, 0x80, 0x3f,
0x00, 0x00, 0x80, 0x3f)
q2 unsigned char __attribute__((ext_vector_type(16)))
(0x00, 0x30, 0x97, 0x42,
0x00, 0x00, 0x86, 0x40,
0x00, 0xc0, 0x16, 0x42,
0x00, 0xc0, 0x59, 0x42)
q10 unsigned char __attribute__((ext_vector_type(16)))
(0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00)
q13跟q2乘加到q10,结果却是全0,为何?
2. 分析
float特点
float计算
float2HEX python转换接口
import struct
print struct.unpack('!f', '42f0e666'.decode('hex'))[0]
print hex(struct.unpack('>> 120.449996948
>>> 0x42f0e666
3. 结论
Arch64:
v10中的v10.s[0]:0x00, 0x00, 0x80, 0x3f,转换成 HEX 就是 0x3f800000,对应的bin值是:
0011 1111 1000 0000 0000 0000 0000 0000(32bit)
float计算就是这么算的(参考wiki):

转换例子:
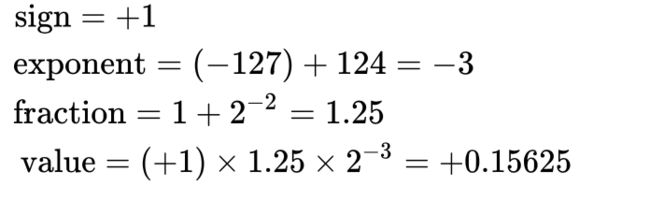
[0]011 1111 1000 0000 0000 0000 0000 0000
符号 sign = (-1)^0 = +1
0[011 1111 1]000 0000 0000 0000 0000 0000
指数 exponent = (-127) + 127 = 0
0011 1111 1[000 0000 0000 0000 0000 0000]
尾数 fraction = 1 + (0*2^-1 + 0*2^-2 + 0*2^-3 + ....)= 1.0
float value = (+1) * 1.0 * 2^0 = 1.0
因此v10中的全是1.0,乘以v14后累加到v16中当然就是v14的浮点值咯!(ps. v16初始化为0了的)
注意:NEON寄存器中数据的顺序低位在前,高位在后,在每个数据单元中高位在前低位在后,如上例所述。
Arch32:
q10之所以全为0,是因为:
#0x3f800000 * #0x42973000 = #0x1084 8068 [0000 0000]我们是以单精度也就是32bit来进行运算的,因此这里的结果值显然是溢出了(需要64bit方能存储完全),对溢出的处理默认是截取低32bit就好,这里的低32bit就刚好是0,因此就出现了两个int值相乘结果为0的“假像”,背后的本质就是值溢出,硬件截断数值。
"mov w5, #0x0000 \n"
"movk w5, #0x3f80, LSL #16 \n"
// "mov w5, #0x3f800000 \n"
"mov v0.s[0], w5 \n"
"mov v0.s[1], w5 \n"
"mov v0.s[2], w5 \n"
"mov v0.s[3], w5 \n"
"mov w6, #0x3000 \n"
"movk w6, #0x4297, LSL #16 \n"
// "mov w6, #0x42973000 \n"
"mov v1.s[0], w6 \n"
"mov v1.s[1], w6 \n"
"mov v1.s[2], w6 \n"
"mov v1.s[3], w6 \n"
"eor v2.8b, v2.8b, v2.8b \n"
"mla v2.4s, v0.4s, v1.4s \n"
ps. 上述在Arch64下的mla等价于Arch32下的VMLA.u32
附录·mov指令
mov的一些基本概念:
"mov w5, #0x3f800000 \n"
"mov v0.s[0], w5 \n"
"mov v0.s[1], w5 \n"
"mov v0.s[2], w5 \n"
"mov v0.s[3], w5 \n"
v0 (0x00, 0x00, 0x80, 0x3f,
0x00, 0x00, 0x80, 0x3f,
0x00, 0x00, 0x80, 0x3f,
0x00, 0x00, 0x80, 0x3f)
这是对的,也就是说立即数搬运只能是16bit宽度,你可以是上16bit也可以是下16bit,但是不能跨越;
"mov w5, #0x3f80 \n"
"mov v0.s[0], w5 \n"
"mov v0.s[1], w5 \n"
"mov v0.s[2], w5 \n"
"mov v0.s[3], w5 \n"
等价于0x00003f80,编译器在前面自动补零;
v0 (0x80, 0x3f, 0x00, 0x00,
0x80, 0x3f, 0x00, 0x00,
0x80, 0x3f, 0x00, 0x00,
0x80, 0x3f, 0x00, 0x00)
在数据手册里面mov指令明确指示立即数只能是16bit大小的:

可以看到Operation区域说了搬运的只能是16bit的立即数,因此下面的这个#0x42973000超出范围了(0x42970000则在范围之内,这里会被编译器解释为“高半字:0x4297),搬运直接编译就会报错的:
"mov w6, #0x42973000 \n"
现在的需求是我们要把32bit跟64bit的立即数搬运到寄存器里面去,但是指令不支持,这个怎么整?

看下这个是A64下的通用指令集,有MOVN、MOVK、MOVZ是可以加移位操作的(ps.单纯的mov指令是不可移位的哈,注意);
这三个指令有什么区别呢?
- movn就是移位之后,整个w寄存器都反转了;
"movn w6, #0x1, LSL #16 \n"
w6: 0xfffeffff
- movz就是移位之后置零,移出来的空位就置零了;
"movn w6, #0x1, LSL #16 \n"
w6: 0x00010000
- movk就是移出来的空位保持原样;
这也就是说我们先把低16bit立即数移动到w寄存器,然后用movk的方式移动高16bit就好啦!
"mov w6, #0x3000 \n" //先搬运下半16bit;
"movk w6, #0x4297, LSL #16 \n" //搬运上半16bit,同时不影响下半16bit;
w6: 0x42973000
