hbase 表存储结构的详细理解,各个模块的作用介绍
1、初学hbase,最让我困惑的是cell的具体value包含几个timestamp的值,理一下

这是网上很多资料,都是这样描述cell,我们在看看hbase官网操作指南中的说法


总结:最总综合了很多说法,结合hbase权威指南,如下


– 在HBase每个cell存储单元对同一份数据有多个版本,根据唯一的时间戳来区分每个版本之间的差异,时间戳可以由HBase(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间,也可以由自己显示指定,按照时间戳倒序排序,最新的数据排在最前面。
– Cell单元格,由行和列的坐标交叉决定,由{row key,column(=
2、表的行、列、列簇
首先我们应该知道的是:最基本的单位是列(column),一列或者多列组成一行(row),并且由唯一的行键(row key)来确定存储。一个表中有很多行,每一列可能有多个版本,在每一个单元格(Cell)中存储了不同的值。
列族需要在创建表的时候就定义好,虽然后面可以对列簇进行增加和删除,但是最开始要确定好表的结构,数量也不宜过多。,创建表的时候不需要定义好列。对列的插入格式通常为family:qualifier,qualifier也可以是任意的字节数组。同一个列族里qualifier的名称应该唯一,否则就是在更新同一列,列的数量没有限制,可以达到百万级别。列值也没有类型和长度限定。都是字节数组
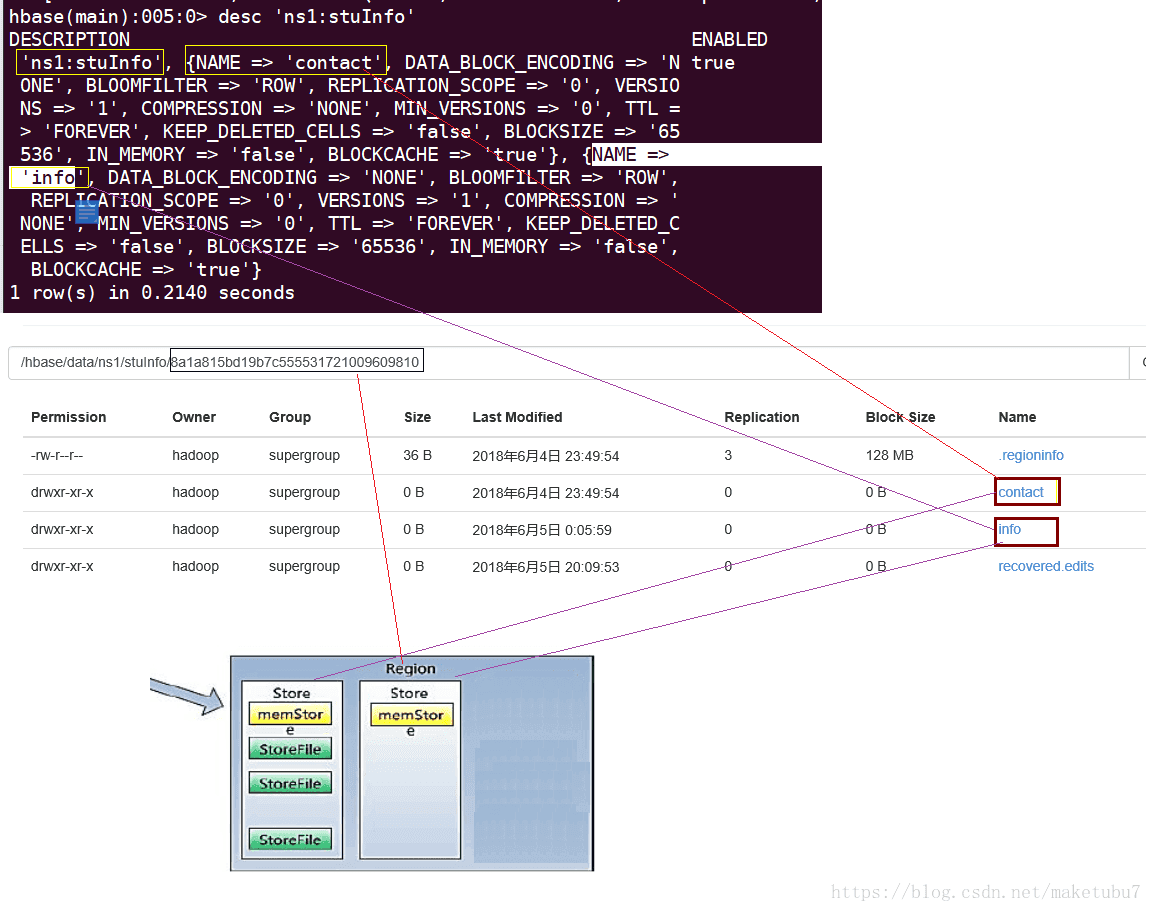
HBase会对row key的长度做检查,默认应该小于65536,因为一个表,数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,在一个行很多的表中,只是rowkey就要占用很大的储存空间,这样会极大影响HFile的存储效率;MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。
在一个表中rowkey是惟一的,如果相同的插入就是更新,整个表按照rowkey 的字典进行有序排序,通过如下的方式取得唯一的值:{namespace->table->colum_family->colum->timestamp}->唯一value
3、region & regionserver &memstore & 底层对应的储存结构
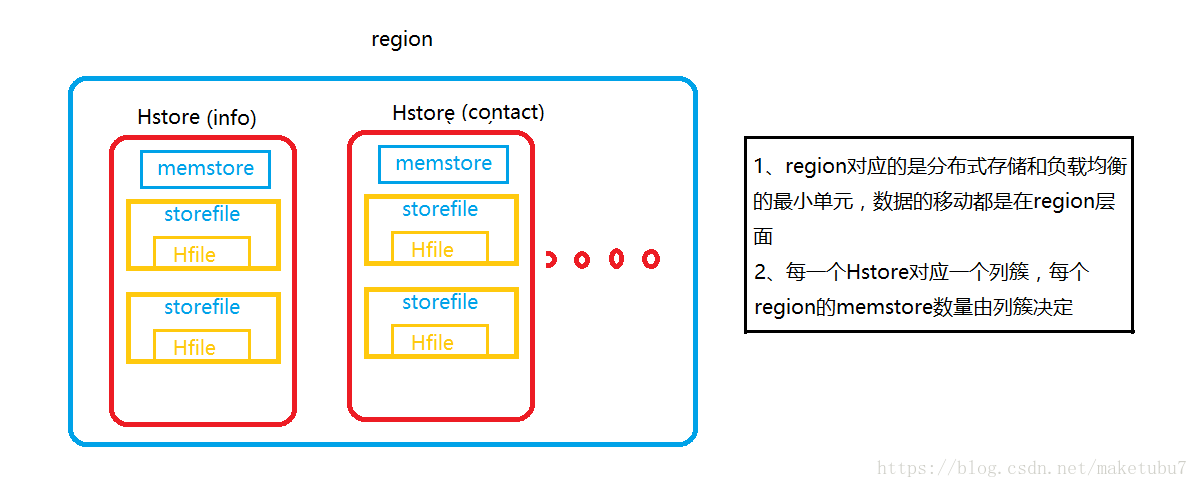
region:每个Hregionserver下有一个或多个region,每个region有一个或多个Hstore,每一个CF(column_family)对应一个Hstore,每个Hstore下有一个或多个Storefile,相当于一个Hstore实例下有多个Storefile实例,而storeFile是对Hfile的轻量级封装,每当一个memstore容量达到阈值,就会flush到hdfs上,产生一个Hfile,Hfile有对应的合并机制,这个前面已经提到了。而当其中一个CF从memstore中flush数据的时候,其他CF也会flush数据,所以这会产生大量的磁盘IO,对整个集群的压力都比较大,多以CF不宜过多,一个最好。
Hregionserver:主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块;当用户更新数据的时候会被分配到对应的HRegion服务器上提交修改,这些修改显示被写到MemStore写缓存和服务器的Hlog文件里面。在操作写入Hlog之后,commit()调用才会将其返回给客户端;在读取数据的时候,HRegion服务器会先访问BlockCache读缓存,如果缓存里没有改数据,才会回到Hstores磁盘上面寻找,每一个列族都会有一个HStore集合,每一个HStore集合包含很多HstoreFile文件。
memstore:存储在HDFS上的数据需要按照row key 排序。而HDFS本身被设计为顺序读写(sequential reads/writes),不允许修改。这样的话,HBase就不能够高效的写数据,因为要写入到HBase的数据不会被排序,这也就意味着没有为将来的检索优化。为了解决这个问题,HBase将最近接收到的数据缓存在内存中(in Memstore),在持久化到HDFS之前完成排序,然后再快速的顺序写入HDFS。需要注意的一点是实际的HFile中,不仅仅只是简单地排序的列数据的列表,详见Apache HBase I/O – HFile。
4、WAL(Write Ahead Log 预写日志)
region server会将数据保存到内存,直到达到阈值再将其刷写到磁盘,这样可避免很多小文件。但尽管如此仍然会有很多Hfile文件,而我们只带内存中的数据极易丢失,断电,宕机,存储在内存中的数据没来得及保存到磁盘,就会出现数据丢失,一旦丢失就找不回来。但WAL能较好的解决这个问题。每次操作都会先写入日志,只有日志写入成功后才会告知客户端写入memstore,然后服务器才按照需要批量处理内存中的数据。
如果服务器崩溃,region server会回访Hlog,通过数据回写,来恢复服务器的内存数据。下图显示了写入过程,也是一个Hbase的框架图
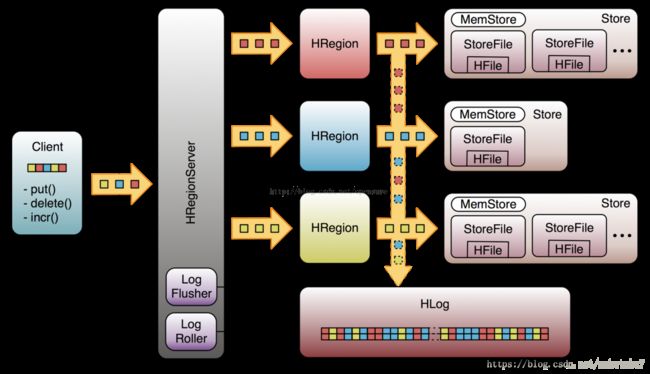
所有的操作都会先保存到WAL,然后再传给MemStore。整个过程是这样的:客户端启动一个操作来修改数据,比如Put。每次修改都封装到一个KeyValue对象实例中,通过RPC调用发送出去。这些调用会发送给含有匹配region的Region Server;KeyValue实例到达后,它们会被分配到管理对应行HRegion实例,数据被写入WAL,然后被放入实际拥有记录的MemStore中;当MemStore达到一定大小或经历一个特定时间,数据会异步的连续的写入到文件系统中(HFile)。如果写入过程出现问题,WAL能保证数据不丢失,因为WAL日志HLog存储在HDFS上。其他region server可以读取日志文件并回写修改,恢复数据。
后面的知识点,再来补充,
参考:https://blog.csdn.net/xiaoshunzi111/article/details/69844526