文献阅读笔记—Deep contextualized word representations
迁移学习在nlp领域的应用之pretrain language representation,四连载,建议按顺序看,看完对该方向一定会非常清楚的!
(一)ELMO:Deep contextualized word representations
(二)Universal Language Model Fine-tuning for Text Classification
(三)openAI GPT:Improving Language Understanding by Generative Pre-Training
(四)BERT: Pretraining of Deep Bidirectional Transformers for Language Understanding
1. 问题描述
这是NAACL 2018的最佳论文。本笔记结合原文使用更佳哦。
以前的词向量都是与上下文无关的词向量,比如用word2vec训练的时候,使用单层神经网络,通过几个周围单词预测中心单词,但是这几个周围单词的顺序并不重要,而且生成的词向量只是代表一种统计意义上最大概率上的语义,即生成的词向量与句法、放入某个特定环境的语义等没有太多关联。
本文采用多层、双向LSTM结构,采用上述词向量,subword向量(使用cnn生成character的上下文无关向量)作为输入,输出和上下文有关的词向量,因为LSTM会结合上下文,提取句法特征,并且多层结构更能提取出语义特征,因此生成的词向量引入了句法、语义等要素。并且对多层结构的hidden state做一个线性组合,不同的线性组合可以适用于不同的task。
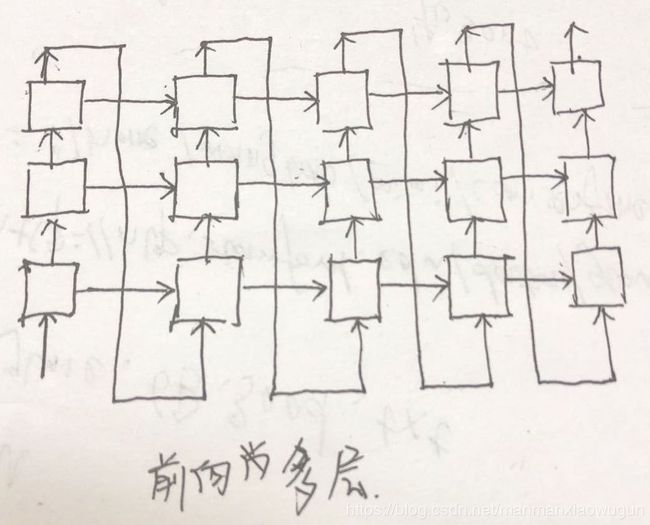
2. 双向语言模型
训练语料是单语哦!不需要双语哦!因为它和word2vec一样都是在单语上建立语言模型哦!怎么建立呢!类似于最大似然估计!
前向语言模型如下图所示,反向语言模型就是把下图方向反一下即可,相当于两个方向的decoder啦。
目标函数为
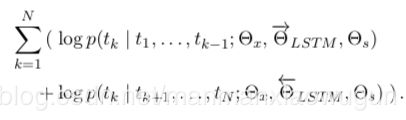
3. ELMO词向量
L层LSTM,对于每个token来说,前向有L个hidden state,反向有L个hidden state,加上输入语言模型的原始词向量,总共2L+1个向量的线性组合,就是ELMO词向量。有的只采用最上层的hidden state(cove就是)。一般情况就如下式:
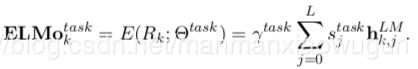
![]() 是对生成的ELMO词向量整体放大或者缩小,一方面平衡加权平均形成的ELMO词向量的大小,一方面更适合某个task。
是对生成的ELMO词向量整体放大或者缩小,一方面平衡加权平均形成的ELMO词向量的大小,一方面更适合某个task。
也可以对每一层的LSTM 的hidden state做normalization,类似于batch normalization的作用啦。
4. ELMO词向量于nlp task结合
先用其他大型语料pretrain好ELMO词向量,再用该task的语料fine tuningELMO词向量,然后固定该ELMO词向量的参数,将ELMO词向量 concat 原始词向量后作为task model的输入,在这个过程中不断的学习![]() 这个线性权重参数。部分task中是将ELMO词向量用在输出那部分的,是将ELMO词向量 concat task model最后的hidden state,其实就是作为最后全连接层的输入,也是不断的学习
这个线性权重参数。部分task中是将ELMO词向量用在输出那部分的,是将ELMO词向量 concat task model最后的hidden state,其实就是作为最后全连接层的输入,也是不断的学习![]() 这个线性权重参数。
这个线性权重参数。
在实验中还会对ELMO做了dropout、对线性权重参数做正则化。
5. 实验
本文使用双层LSTM,hidden state是4096维,hidden state到output的全连接为4096*512,两层之间加residual network,character embedding是通过cnn+highway network做的,cnn是2048卷积核,卷积核到output的全连接映射为2048*512。这些网络改编自2016年Jo ́zefowicz的CNN-BIG-LSTM。character embedding可以解决OOV问题。
1. 本文在Question answering、Textual entailment、Semantic role labeling、Coreference resolution、Named entity extraction、Sentiment analysis六个方向都做了实验。
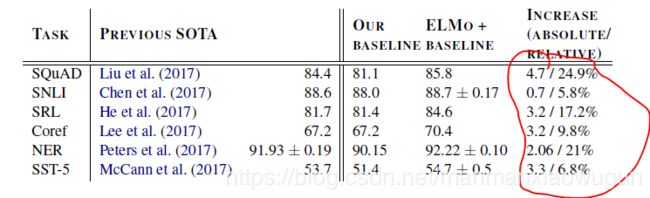
可以看到使用ELMO词向量提升很大。
2. 正则化项,![]() =1时,因为比较大,对线性权重限制较大,所以线性权重比较均匀,
=1时,因为比较大,对线性权重限制较大,所以线性权重比较均匀,![]() =0.001时, 因为比较小,对线性权重限制较小,所以线性权重变化比较大,因此线性权重起的作用比较大,因此效果相对好一点。
=0.001时, 因为比较小,对线性权重限制较小,所以线性权重变化比较大,因此线性权重起的作用比较大,因此效果相对好一点。
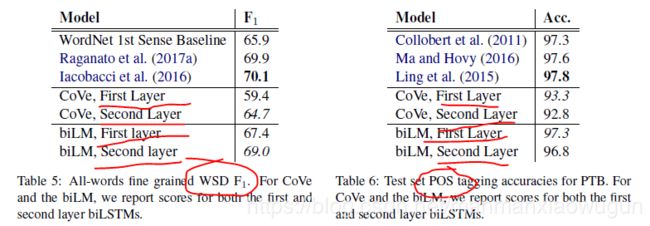
3. 多层双向LSTM结构,低层更能提取句法特征,高层更能提取出语义特征,可以将LSTM相应层的hidden state直接应用在pos tagging和word sense disambiguation上对比的。
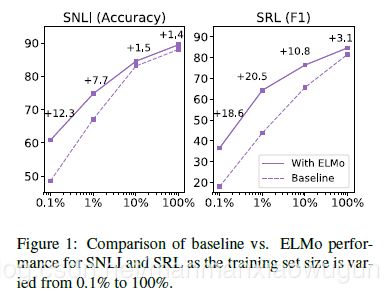
4. 训练效率问题,使用ELMO词向量可以少98%epoch就能训练好,对于数据量越少的情况,使用ELMO效果好的越多。
代码 http://allennlp.org/elmo