数据仓库(三)之架构篇
-
概述
架构是数据仓库建设的总体规划,从整体视角描述了解决方案的高层模型,描述了各个子系统的功能以及关系,描述了数据从源系统到决策系统的数据流程。业务需求回答了要做什么,架构就是回答怎么做的问题。
-
架构的价值

-
数据仓库架构
数据仓库的核心功能从源系统抽取数据,通过清洗、转换、标准化,将数据加载到BI平台,进而满足业务用户的数据分析和决策支持。数据仓库架构包含三个部分:数据架构、应用程序架构、底层设施。
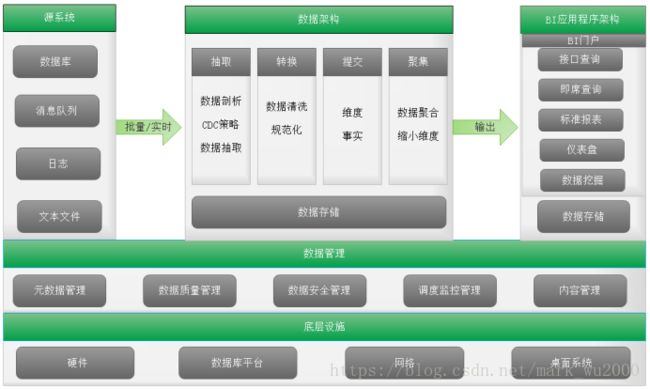
-
底层设施
底层设施为架构提供了基础,底层设施包括硬件、数据库平台、网络和桌面系统。
硬件
硬件主要指服务器硬件,主要有数据库服务器、ETL服务器、调度服务器、报表服务器、BI门户服务器、接口服务器。
数据库平台
数据库平台分为二大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing),OLAP是为数据分析而设计的数据库管理系统。主要有Oracel,MySQL,Teradata, Greenplum,Hive,Kudu。
桌面系统
数据仓库不同的应用对桌面系统也有不同的要求,开发工具主要有Window、Mac面系统,部署服务器主要有Unix桌面系统,系统BI应用程序主要有Window、Mac、移动设备桌面系统。
网络
网络是底层设施的基础,特别是大数据时代对网络的要求越来越高。
-
BI应用程序架构
数据仓库是数据处理的后台,业务用户并不关心后台怎么处理。BI应用是数据呈现的前台,是业务用户进行查询的入口。BI应用程序的体验也是衡量数据仓库是否成功的主要因素。
BI分析周期
业务分析从监视活动开始识别某个问题或时机,进而采取行动,最终回到监视该活动产生的结果上来,达到数据驱动业务增长的目的。分析周期把这个过程分为五个不同的阶段。

BI应用分类
接口查询
数据以接口的形式提供给上下游系统,供上下业务系统进行查询。主要有推和拉二种模式。
即席查询
业务用户根据自己的需求,自定义查询请求,后台自动组织SQL语句访问维度模型。
标准报表
根据业务用户的需求,进行定制报表。
仪表盘
它是向企业展示度量信息和关键业务指标现状的数据可视化工具。
数据挖掘
为数据挖掘工具提供标准基础数据。
运营查询
为了减少业务系统的大数据量查询压力,数据仓库为业务系统提供实时的查询。
数据存储

-
数据架构
数据架构主要描述数据从源系统抽取数据,然后经过清洗、规范化、提交形成标准模型,最终提交给业务用户,以及对数据的管理。
源系统
数据仓库一般会面临多个、异构数据源的问题,主要分为结构化,半结构化以及非结构化数据。为了便于管理需要对源系统建立元数据信息。
抽取
因为源系统的多样性,源抽取阶段一般选择使用工具。在抽取之前还要做以下工作:
数据剖析是对数据的技术性分析,对数据的内容、一致性和结构进行描述。对源系统的数据质量进行评估。
-
数据剖析
-
变化数据捕获策略
为了减少对源系统的影响,一般只抽取变化的数据,也需要识别物理删除的数据。CDC策略主要有:
添加审计列
在源系统追加日期字段,当数据发生变化的时候,系统会自动更新该值。如果由后台人员手工修改数据,可能就发生遗漏。
数据比较
比较源系统和数据仓库的数据,只抽取变化的数据。这种方法需要全量的数据,比较耗费资源。可以视数据量的大小而定。
读取日志
读取数据库操作日志信息,同步到数据仓库中。一般日志的有效期比较短,一旦发生要重跑的情况,可能以前的日志已经被清空了。
消息队列
把事务信息放到消息队列里,以流的形式同步到数据仓库。这种方式即可以减轻源系统的压力,又能做到实时同步。
数据转换
数据从源系统抽取过来之后,就要进入数据转换阶段。 这一阶段是数据仓库开发核心阶段。主要有以下步骤:
清洗
数据清洗是制定转换规则,筛选数据并纠正数据的过程。清洗的目的是改进源系统的数据质量,但是不要在数据仓库做过多的清洗,源系统的数据质量应该在源头处理。清洗的主要内容包括:

规范化
规范化就是整合各个源系统的数据,把数据统一命名,统一取值,建立企业标准版本数据。主要内容包括:

提交
提交就要根据维度模型生成维度表和事实表。 提交主要内容包括:
- 选择合适的缓慢变化维类型
- 为维表生成代理键
- 管理不同粒度的层次维
- 管理专项维
- 生成维度桥接表
- 生成代理键管道
- 选择合适的事实表类型
- 处理延迟到达的事实
- 生成维度表
- 生成事实表
聚集
聚集是指根据事务事实表进行更高粒度的聚合以及生成相对应的维度表。主要内容包括:

数据存储
数据存储是指在在数据的生命周期内对数据的管理,主要内容包括:
