spark本地工程的三种打包方案及一点经验总结
在本地的spark写成并自测通过后,需要打成jar包并提交到集群,下面是几种打包方案
第一种:通过idea的build artifacts
1.先把meta-inf这个文件夹删掉,如果是第一次build,这个文件夹自然是不存在的
2.到build中点击build artifacts, 如果这个按钮是灰的,到project structure中edit,生成的jar包在out下
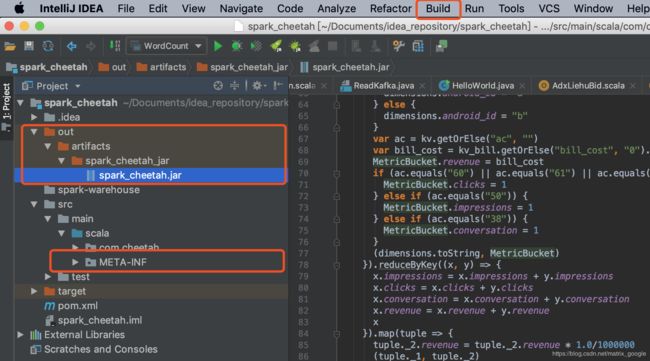
点击build的下面的build Artifact下的edit
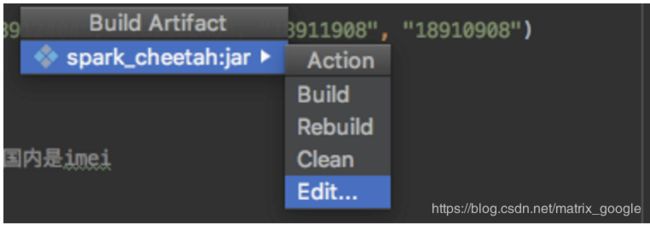
点击edit之后会进入project structure界面
3.先把原来的jar删掉,然后选中新的,然后将依赖包都删掉,只保留output目录
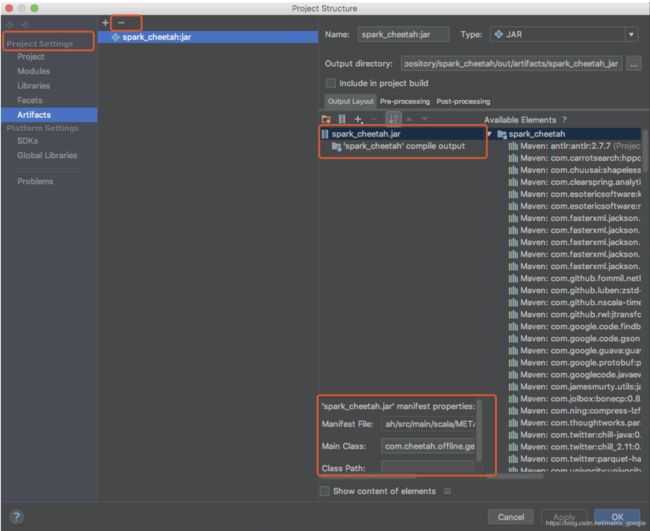
这种打包方式也是对整个工程打包,且不包含依赖jar包,在线上运行时用的spark jar包都用spark/lib包下的
这种方式的优点
1.比maven的编译速度快
2.只需要配置一次,因为是对整个工程打包
3.不包含依赖的第三方jar包
如果新建了一个class文件需要rebuild,上面这些都不用动,只需要在spark-sumbit提交时,将class名字换成你想用的那个即可,
因为build是对整个项目打包的
下面给出一个提交任务到yarn集群上的例子
spark-submit --class packagename.classname --queue queuename --master yarn-cluster --verbose --driver-memory 2G --num-executors 20 --executor-memory 30G --executor-cores 6 spark_cheetah_maven.jar "hdfs_input_file_dir" "hdfs_output_dir"
注意
1.spark的输出目录自己不要建,让程序自动建,否则会报错
2.excuter的numbe数,内存数,核数对程序运行速度的影响真的很大,越大越快,表现很明显
3.如果集群的内存有限,最后不要用cache方法,甚至其他的序列化缓存策略都不要用,我就吃过好几次亏
4.提交上线之前要注意输出目录是否删除,一定要删掉,或者在程序中自动删除
5.编译打包之前一定要把local模式改成master模式
6.如果输入文件很大,比如2T,按照块大小除一下会生成很多block,在保存文件时如果不进行repartition,会导致最后生成成千上万个part文件
这也是我最近提交任务时遇到的一些坑,特此记一下
第二种:mvn clean package
生成的jar包在target下,默认是包含第三方依赖的jar包的,如果项目中依赖的jar包很多,这种打包方式很慢
我用这个命令打的jar包测试了一下,程序完全正确运行
第三种:不包含依赖包的maven打包
这种我没有测试过,网上的实现方案很多
优点:通过命令行就可以打包;不包含第三方依赖包打包速度很快
缺点:maven中要有插件,较为麻烦
最近我在测试中发现
如果同一个包下有同名class,通过maven命令编译就会报错,但是通过第一种方式就不一定会报错
虽然第一种方式不报错,但是待运行的class和其他class同名的话,运行可能还是会报错
甚至在开发时就会莫名其妙的报错,现象为
明明自己定义了一个Dimension类,然后引用这个对象的一个属性,但这个属性总是飘红,
原因就是在同一个包下肯定还有一个Dimension类,即使这个类和你的一模一样,你也要重新命名
在拷贝别人的代码时要特别注意这点,最近在这个问题上都吃过好几次亏了