LSTM理论知识讲解
结构
1. RNN与LSTM的对比
RNN:

LSTM:

其中的notation:

这里要注意:上图中四个黄框,每一个都是普通的神经网络,激活函数就是框上面所标注的。
通过对比可以看出,RNN的一个cell中只有一个神经网络,而LSTM的一个cell中有4个神经网络,故一个LSTM cell的参数是一个RNN cell参数的四倍。

从上图也可以看出,原来的一个RNN cell只需要存储一个隐藏层状态h,而一个LSTM cell需要存储两个状态c和h。

LSTM比RNN多了一个细胞状态,就是最上面一条线(也就是c),像一个传送带,信息可以不加改变的流动。即Ct-2可能和Ct+1存储的信息可能非常相似,所以LSTM可以解决RNN长依赖的问题。
2. LSTM信息的流动

一个LSTM cell有3个门,分别叫做遗忘门(f门),输入门(i门)和输出门(o门)。要注意的是输出门的输出ot并不是LSTM cell最终的输出,LSTM cell最终的输出是ht和ct。
这三个门就是上图中三个标着 σ {\sigma} σ的黄色的框。sigmoid层输出0-1的值,表示让多少信息通过,1表示让所有的信息都通过。
LSTM的输入: C t − 1 C_{t-1} Ct−1, h t − 1 h_{t-1} ht−1和 x t x_{t} xt
LSTM的输出: h t h_{t} ht、 C t C_{t} Ct
f t f_{t} ft = σ {\sigma} σ( W f W_{f} Wf ⋅ \cdot ⋅ [ h t − 1 h_{t-1} ht−1, x t − 1 x_{t-1} xt−1] + b f b_{f} bf)
i t i_{t} it = σ {\sigma} σ( W i W_{i} Wi ⋅ \cdot ⋅ [ h t − 1 h_{t-1} ht−1, x t − 1 x_{t-1} xt−1] + b i b_{i} bi)
C t ~ \tilde{C_{t}} Ct~ = t a n h tanh tanh( W C W_{C} WC ⋅ \cdot ⋅ [ h t − 1 h_{t-1} ht−1, x t − 1 x_{t-1} xt−1] + b C b_{C} bC)
C t C_{t} Ct = f t f_{t} ft ∗ \ast ∗ C t − 1 C_{t-1} Ct−1 + i t i_{t} it ∗ \ast ∗ C t ~ \tilde{C_{t}} Ct~
o t o_{t} ot = σ {\sigma} σ( W o W_{o} Wo ⋅ \cdot ⋅ [ h t − 1 h_{t-1} ht−1, x t − 1 x_{t-1} xt−1] + b o b_{o} bo)
h t h_{t} ht = o t o_{t} ot ∗ \ast ∗ t a n h tanh tanh( C t C_{t} Ct)
注意上面公式中的 ∗ \ast ∗是对应元素乘,而不是矩阵的乘法
忘记门:扔掉信息(细胞状态)

第一步是决定从细胞状态里扔掉什么信息(也就是保留多少信息)。将上一步细胞状态中的信息选择性的遗忘 。
实现方式:通过sigmoid层实现的“忘记门”。以上一步的 h t − 1 h_{t-1} ht−1和这一步的 x t x_{t} xt作为输入,然后为 C t − 1 C_{t-1} Ct−1里的每个数字输出一个0-1间的值,记为 f t f_{t} ft,表示保留多少信息(1代表完全保留,0表示完全舍弃)
例子:让我们回到语言模型的例子中来基于已经看到的预测下一个词。在这个问题中,细胞状态可能包含当前主语的类别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
例如,他今天有事,所以我… 当处理到‘’我‘’的时候选择性的忘记前面的’他’,或者说减小这个词对后面词的作用。
输入层门:存储信息(细胞状态)
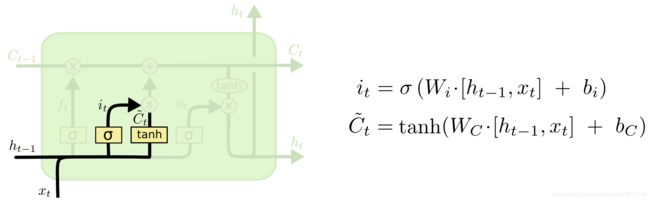
第二步是决定在细胞状态里存什么。将新的信息选择性的记录到细胞状态中。 实现方式:包含两部分,
- sigmoid层(输入门层)决定我们要更新什么值,这个概率表示为 i t i_{t} it
- tanh层创建一个候选值向量 C t ~ \tilde{C_{t}} Ct~,将会被增加到细胞状态中。 我们将会在下一步把这两个结合起来更新细胞状态。
例子:在我们语言模型的例子中,我们希望增加新的主语的类别到细胞状态中,来替代旧的需要忘记的主语。 例如:他今天有事,所以我…
当处理到‘’我‘’这个词的时候,就会把主语我更新到细胞中去。
更新细胞状态(细胞状态)

注意上面公式中的 ∗ \ast ∗是对应元素乘,而不是矩阵的乘法
更新旧的细胞状态 实现方式: f t f_{t} ft 表示忘记上一次的信息 C t − 1 C_{t-1} Ct−1的程度, i t i_{t} it
表示要将候选值 C t ~ \tilde{C_{t}} Ct~加入的程度, 这一步我们真正实现了移除哪些旧的信息(比如一句话中上一句的主语),增加哪些新信息,最后得到了本细胞的状态 C t C_{t} Ct。
输出层门:输出(隐藏状态)

最后,我们要决定作出什么样的预测。 实现方式:
- 我们通过sigmoid层(输出层门)来决定输出的本细胞状态 C t C_{t} Ct 的哪些部分;
- 然后我们将细胞状态通过tanh层(使值在-1~1之间),然后与sigmoid层的输出相乘得到最终的输出 h t h_{t} ht。
所以我们只输出我们想输出的部分。 例子:在语言模型的例子中,因为它就看到了一个 代词,可能需要输出与一个 动词相关的信息。例如,可能输出是否代词是单数还是复数,这样如果是动词的话,我们也知道动词需要进行的词形变化。
例如:上面的例子,当处理到‘’我‘’这个词的时候,可以预测下一个词,是动词的可能性较大,而且是第一人称。 会把前面的信息保存到隐层中去。
LSTM的各个变量

⊙ 是element-wise乘,即按元素乘
介绍下各个变量的维度,LSTM cell的输出 h t h_{t} ht 的维度是黄框里隐藏层神经元的个数,记为d,即矩阵 W f W_{f} Wf , W i W_{i} Wi, W c W_{c} Wc, W o W_{o} Wo的行数。t 时刻LSTM cell的输入 x t x_{t} xt的维度记为 n,最终的输入是 h t − 1 h_{t-1} ht−1和 x t x_{t} xt的联合,即[ h t − 1 h_{t-1} ht−1, x t x_{t} xt] ,其维度是 d + n d+n d+n,所有矩阵(包括 W f W_{f} Wf , W i W_{i} Wi, W c W_{c} Wc, W o W_{o} Wo)的维度都是[ d d d, d d d+ n n n],所有的向量包括( b f b_{f} bf , b i b_{i} bi, b c b_{c} bc, b o b_{o} bo, f t f_{t} ft, i t i_{t} it, o t o_{t} ot, h t h_{t} ht, h t − 1 h_{t-1} ht−1, C t − 1 C_{t-1} Ct−1, C t C_{t} Ct和 C t ~ \tilde{C_{t}} Ct~)维度都是 d d d。(为了表示、更新方便,我们将bias放到矩阵里)
以 W f W_{f} Wf举例:

同理:

合并为一个矩阵就是:

转载自:https://blog.csdn.net/wjc1182511338/article/details/79285503 , 个别地方有补充