python 性能提升之 并行map 线程池过亿数据量
前段时间进行单一目录下10万张图片发送,效果很差,数据积压原来越多。
性能问题提上议程。
采用多线程 多进程 感觉比较繁琐,网上有介绍 map的并行处理的,使用后性能提高明细。
网上介绍map如下
介绍:Map
Map是一个很棒的小功能,同时它也是Python并行代码快速运行的关键。给不熟悉的人讲解一下吧,map是从函数语言Lisp来的。map函数能够按序映射出另一个函数。例如
urls = ['http://www.yahoo.com', 'http://www.reddit.com']
results = map(urllib2.urlopen, urls)这里调用urlopen方法来把调用结果全部按序返回并存储到一个列表里。就像:
results = []
for url in urls:
results.append(urllib2.urlopen(url))Map按序处理这些迭代。调用这个函数,它就会返回给我们一个按序存储着结果的简易列表。
为什么它这么厉害呢?因为只要有了合适的库,map能使并行运行得十分流畅!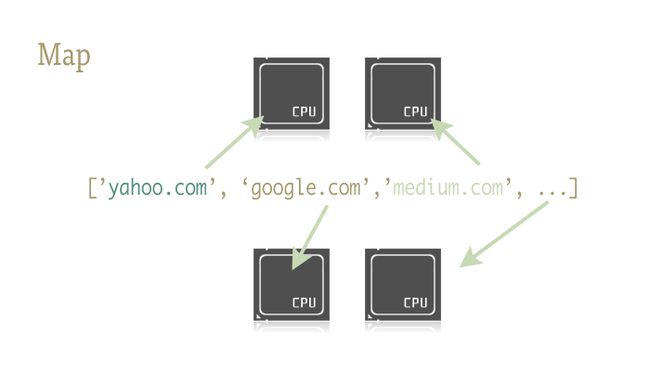
有两个能够支持通过map函数来完成并行的库:一个是multiprocessing,另一个是鲜为人知但功能强大的子文件:multiprocessing.dummy。
题外话:这个是什么?你从来没听说过dummy多进程库?我也是最近才知道的。它在多进程的说明文档里面仅仅只被提到了一句。而且那一句就是大概让你知道有这么个东西的存在。我敢说,这样几近抛售的做法造成的后果是不堪设想的!
Dummy就是多进程模块的克隆文件。唯一不同的是,多进程模块使用的是进程,而dummy则使用线程(当然,它有所有Python常见的限制)。也就是说,数据由一个传递给另一个。这能够使得数据轻松的在这两个之间进行前进和回跃,特别是对于探索性程序来说十分有用,因为你不用确定框架调用到底是IO 还是CPU模式。
准备开始
要做到通过map函数来完成并行,你应该先导入装有它们的模块:
from multiprocessing import Pool
from multiprocessing.dummy import Pool as ThreadPool再初始化:
pool = ThreadPool()这简单的一句就能代替我们的build_worker_pool 函数在example2.py中的所有工作。换句话说,它创建了许多有效的worker,启动它们来为接下来的工作做准备,以及把它们存储在不同的位置,方便使用。
Pool对象需要一些参数,但最重要的是:进程。它决定pool中的worker数量。如果你不填的话,它就会默认为你电脑的内核数值。
如果你在CPU模式下使用多进程pool,通常内核数越大速度就越快(还有很多其它因素)。但是,当进行线程或者处理网络绑定之类的工作时,情况会比较复杂所以应该使用pool的准确大小。
pool = ThreadPool(4) # Sets the pool size to 4如果你运行过多线程,多线程间的切换将会浪费许多时间,所以你最好耐心调试出最适合的任务数。
使用代码效果:
没有优化前代码,性能很差,数据处理不完,积压越来越多
import linecache
import os
import os.path
import requests
import time
import datetime
import sys
reload(sys)
sys.setdefaultencoding('utf8')
imagedir='/opt/tomcat_api/video_sendto_api/image_bak/'
def send_image(imagedir):
#扫描图片路径
for img_parent, img_dir_names, img_names in os.walk(imagedir):
for img_name in img_names:
image = os.path.join(img_parent, img_name) #拼接图片完整路径
print time.strftime("%Y-%m-%d %X"),image
#准备发送图片
file = dict(file=open(image, 'rb'))
post_data = {'mark': 'room-201', 'timestamp': 1846123456, 'random': 123}
headers = {'app_key': app_key, 'access_token': access_token}
result = requests.post(url, files=file, data=post_data, headers=headers, verify=False)
print result.content
#删除发送的图片
str_img = "rm -f " + " " + image
del_img = os.popen(str_img).readline()
print del_img
if __name__ == "__main__":
send_image(imagedir)
采用map 代码,效果处理速度明细。
拆分send_image函数。
import linecache
import os
import os.path
import requests
import time
import datetime
import sys
reload(sys)
sys.setdefaultencoding('utf8')
from multiprocessing import Pool
from multiprocessing.dummy import Pool as ThreadPool
imagedir='/opt/tomcat_api/video_sendto_api/image_bak/'
#获取扫描目录,生成列表
def get_img_path(imagedir):
list=[]
for img_parent, img_dir_names, img_names in os.walk(imagedir):
for img_name in img_names:
image = os.path.join(img_parent, img_name) #拼接图片完整路径
list.append(image)
return list
def send_images(image):
file = dict(file=open(image, 'rb'))
post_data = {'mark': 'room-201', 'timestamp': 1846123456, 'random': 123}
headers = {'app_key': app_key, 'access_token': access_token}
result = requests.post(url, files=file, data=post_data, headers=headers, verify=False)
print result.content
str_img = "rm -f " + " " + image
del_img = os.popen(str_img).readline()
print del_img
if __name__ == "__main__":
image=get_img_path(imagedir)
pool=Pool()
pool.map(send_images,image)
pool.close()
pool.join()
任务不需要长时间运行,如果程序处理完毕,添加定时任务再吊起来。
crontab 11分钟检测一次。
#!/bin/bash
counter=$(ps -C video_send2api_new|wc -l)
if [ "${counter}" -le 1 ]; then
python /opt/tomcat_api/video_sendto_api/video_send2api_new.py >>/opt/tomcat_api/video_sendto_api/logs/out.log&
fi
线程池
接到任务要发送一亿个图片,来进行系统性能和稳定性验证。本次任务采用 线程池 ThreadPoolExecutor 来解决。
from concurrent.futures import ThreadPoolExecutor实现思路:准备30万图片,图片提前生成任务列表,循环读取任务列表。
代码如下
# -*- coding:utf-8 -*-
import time
import os
from concurrent.futures import ThreadPoolExecutor
#具体实现方法
def read_url(num, url):
pass
#主要方法
def query_data():
file_path = "md5_list.txt"
num = 0
count= 100000000
begin_time = time.time()
print("开始时间:", time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
while True:
with open(file_path, 'r') as f:
urls = f.readlines()
with ThreadPoolExecutor(10) as executor:
for url in urls:
num = num +1
count -= 1
executor.submit(read_url, num, url)
if count <= 0:
break
if count <=0:
break
end_time = time.time()
print("结束:", time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
print("总时间:%f s"% (end_time - begin_time))
根据当前cpu核数,可以设置线程数量,本代码设置10