NLP之文本分类
文本自动分类简称文本分类(text categorization),是模式识别与自然语言处理密切结合的研究课题。传统的文本分类是基于文本内容的,研究如何将文本自动划分成政治的、经济的、军事的、体育的、娱乐的等各种类型。
目录
文本表示
文本向量化
向量的相似性度量(similarity)
文本特征选择方法
特征权重计算方法
分类器设计
文本分类评测指标
文本分类是在预定义的分类体系下,根据文本的特征(内容或属性),将给定文本与一个或多个类别相关联的过程。因此,文本分类研究涉及文本内容理解和模式分类等若干自然语言理解和模式识别问题。
文本分类任务的最终目的是要找到一个有效的映射函数,准确地实现域D×C到值T或F的映射,这个映射函数实际上就是我们通常所说的分类器。因此,文本分类中有两个关键问题:一个是文本的表示,另一个就是分类器设计。
![]()
根据分类知识获取方法的不同,文本自动分类系统大致可分为两种类型:基于知识工程(knowledge engineering, KE)的分类系统和基于机器学习(machine learning, ML)的分类系统。90年代以后,基于统计机器学习的文本分类方法日益受到重视,这种方法在准确率和稳定性方面具有明显的优势。系统使用训练样本进行特征选择和分类器参数训练,根据选择的特征对待分类的输入样本进行形式化,然后输入到分类器进行类别判定,最终得到输入样本的类别。
文本表示
文本向量化
一个文本表现为一个由文字和标点符号组成的字符串,由字或字符组成词,由词组成短语,进而形成句、段、节、章、篇的结构。要使计算机能够高效地处理真实文本,就必须找到一种理想的形式化表示方法,这种表示一方面要能够真实地反映文档的内容(主题、领域或结构等),另一方面,要有对不同文档的区分能力。
目前文本表示通常采用向量空间模型(vecto rspace model,VSM)。
下面首先给出VSM涉及的一些基本概念。
文档(document):通常是文章中具有一定规模的片段,如句子、句群、段落、段落组直至整篇文章。
项/特征项(term/feature term):特征项是VSM中最小的不可分的语言单元,可以是字、词、词组或短语等。一个文档的内容被看成是它含有的特征项所组成的集合。
项的权重(term weight):对于含有n个特征项的文档,每一特征项tk都依据一定的原则被赋予一个权重wk,表示它们在文档中的重要程度。
这样一个文档D可用它含有的特征项及其特征项所对应的权重所表示。
一个文档在上述约定下可以看成是n维空间中的一个向量,这就是向量空间模型的由来。
因此采用向量空间模型进行文本表示时,需要经过以下两个主要步骤:
①根据训练样本集生成文本表示所需要的特征项序列D={t1,t2,…,td};
②依据文本特征项序列,对训练文本集和测试样本集中的各个文档进行权重赋值、规范化等处理,将其转化为机器学习算法所需的特征向量。
向量的相似性度量(similarity)
任意两个文档D1和D2之间的相似系数Sim(D1,D2)指两个文档内容的相关程度(degree of relevance)。设文档D1和D2表示VSM中的两个向量:
D1=D1(w11,w12,…,w1n)
D2=D2(w21,w22,…,w2n)
那么,可以借助于n维空间中两个向量之间的某种距离来表示文档间的相似系数,常用的方法是使用向量之间的内积来计算。
![]()
如果考虑向量的归一化,则可使用两个向量夹角的余弦值来表示相似系数:
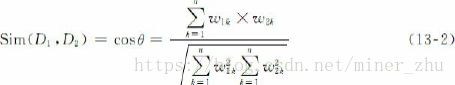
文本特征选择方法
在向量空间模型中,表示文本的特征项可以选择字、词、短语,甚至“概念”等多种元素。但是,如何选取特征,各种特征应该赋予多大的权重,选取不同的特征对文本分类系统的性能有什么影响等,很多问题都值得深入研究。目前已有的特征选取方法比较多,常用的方法有:基于文档频率(document frequency, DF)的特征提取法、信息增益(information gain, IG)法、χ2统计量(CHI)法和互信息(mutual information, MI)方法等。
1.基于文档频率的特征提取法
文档频率(DF)是指出现某个特征项的文档的频率。基于文档频率的特征提取法通常的做法是:从训练语料中统计出包含某个特征的文档的频率(个数),然后根据设定的阈值,当该特征项的DF值小于某个阈值时,从特征空间中去掉该特征项,因为该特征项使文档出现的频率太低,没有代表性;当该特征项的DF值大于另外一个阈值时,从特征空间中也去掉该特征项,因为该特征项使文档出现的频率太高,没有区分度。
基于文档频率的特征选择方法可以降低向量计算的复杂度,并可能提高分类的准确率,因为按这种选择方法可以去掉一部分噪声特征。这种方法简单、易行。但严格地讲,这种方法只是一种借用算法,其理论根据不足。根据信息论我们知道,某些特征虽然出现频率低,但往往包含较多的信息,对于分类的重要性很大。对于这类特征就不应该使用DF方法将其直接排除在向量特征之外。
2.信息增益法
信息增益(IG)法依据某特征项ti为整个分类所能提供的信息量多少来衡量该特征项的重要程度,从而决定对该特征项的取舍。某个特征项ti的信息增益是指有该特征或没有该特征时,为整个分类所能提供的信息量的差别,其中,信息量的多少由熵来衡量。因此,信息增益即不考虑任何特征时文档的熵和考虑该特征后文档的熵的差值
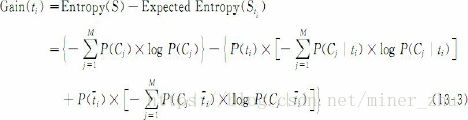
从信息增益的定义可知,一个特征的信息增益实际上描述的是它包含的能够帮助预测类别属性的信息量。从理论上讲,信息增益应该是最好的特征选取方法,但实际上由于许多信息增益比较高的特征出现频率往往较低,所以,当使用信息增益选择的特征数目比较少时,往往会存在数据稀疏问题,此时分类效果也比较差。因此,有些系统实现时,首先对训练语料中出现的每个词(以词为特征)计算其信息增益,然后指定一个阈值,从特征空间中移除那些信息增益低于此阈值的词条,或者指定要选择的特征个数,按照增益值从高到低的顺序选择特征组成特征向量。
3.χ2统计量
χ2统计量(CHI)衡量的是特征项ti和类别Cj之间的相关联程度,并假设ti和Cj之间符合具有一阶自由度的χ2分布。特征对
于某类的χ2统计值越高,它与该类之间的相关性越大,携带的类别信息也较多,反之则越少。
4.互信息法
互信息(MI)法的基本思想是:互信息越大,特征ti和类别Cj共现的程度越大。
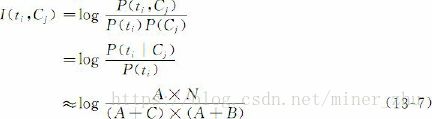
以上是文本分类中比较经典的一些特征选取方法,实际上还有很多其他文本特征选取方法,例如,DTP(distance to transition point)方法,期望交叉熵法、文本证据权法、优势率方法,以及国内学者提出的“类别区分词”的特征提取方法,组合特征提取方法,基于粗糙集(rough set)的特征提取方法TFACQ,以及利用自然语言文本所隐含规律等多种信息的强类信息词(strong information class word, SCIW)的特征选取方法等等。
另外需要指出的是,无论选择什么作为特征项,特征空间的维数都是非常高的,在汉语文本分类中问题表现得更为突出。这样的高维特征向量对后面的分类器存在不利的影响,很容易出现模式识别中的“维数灾难”现象。而且,并不是所有的特征项对分类都是有利的,很多提取出来的特征可能是噪声。因此,如何降低特征向量的维数,并尽量减少噪声,仍然是文本特征提取中的两个关键问题。
特征权重计算方法
特征权重用于衡量某个特征项在文档表示中的重要程度或者区分能力的强弱。权重计算的一般方法是利用文本的统计信息,主要是词频,给特征项赋予一定的权重。
我们将一些常用的权重计算方法归纳为表13-2所示的形式。表中各变量的说明如下:wij表示特征项ti在文本Dj中的权重,tfij表示特征项ti在训练文本Dj中出现的频度;ni是训练集中出现特征项ti的文档数,N是训练集中总的文档数;M为特征项的个数,nti为特征项ti在训练语料中出现的次数。

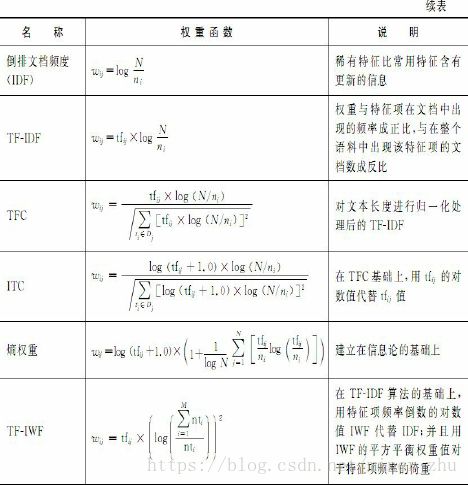
倒排文档频度(inverse document frequency, IDF)法是1972年Spark Jones提出的计算词与文献相关权重的经典计算方法,其在信息检索中占有重要地位。该方法在实际使用中,常用公式L+log ((N-ni)/ni)替代,其中,常数L为经验值,一般取为1。IDF方法的权重值随着包含 某个特征的文档数量ni的变化呈反向变化,在极端情况下,只在一篇文档中出现的特征含有最高的IDF值。TF-IDF方法中公式有多种表达形式,TFC方法和ITC方法都是TF-IDF方法的变种。
TF-IWF(inverse word frequency)权重算法也是在TF-IDF算法的基础上由Basili et al.(1999)提出来的。TF-IWF与TF-IDF的不同主要体现在两个方面:①TF-IWF算法中用特征频率倒数的对数值IWF代替IDF; ②TF-IWF算法中采用了IWF的平方,而不像IDF中采用的是一次方。R.Basili等认为IDF的一次方给了特征频率太多的倚重,所以用IWF的平方来平衡权重值对于特征频率的倚重。
除了上面介绍的这些比较常用的方法以外,还有很多其他权重计算方法。例如:Dagan et al.(1997)提出的基于错误驱动的(mistake-driven)特征权重算法,这种算法的类权重向量不是通过一个表达式直接计算出来的,而是首先为每个类指定一个初始权重向量,不断输入训练文本,并根据对训练文本的分类结果调整类权重向量的值,直到类权重向量的值大致不再改变为止。
方法。例如:Dagan et al.(1997)提出的基于错误驱动的(mistake-driven)特征权重算法,这种算法的类权重向量不是通过一个表达式直接计算出来的,而是首先为每个类指定一个初始权重向量,不断输入训练文本,并根据对训练文本的分类结果调整类权重向量的值,直到类权重向量的值大致不再改变为止。
分类器设计
文本分类本身是一个分类问题,因此,一般的模式分类方法都可用于文本分类研究。常用的分类算法包括:朴素的贝叶斯分类法
(naΪve Bayesian classifier)、基于支持向量机(support vector machines, SVM)的分类器、k-最近邻法(k-nearest neighbor, kNN)、神经网络法(neural network, NNet)、决策树(decision tree)分类法、模糊分类法(fuzzy classifier)、Rocchio分类方法和Boosting算法等。
1.朴素贝叶斯分类器
朴素贝叶斯分类器的基本思想是利用特征项和类别的联合概率来估计给定文档的类别概率。
假设文本是基于词的一元模型,即文本中当前词的出现依赖于文本类别,但不依赖于其他词及文本的长度,也就是说,词与词之间是独立的。根据贝叶斯公式,文档Doc属于Ci类的概率为
![]()
在具体实现时,通常又分为两种情况:
(1)文档Doc采用DF向量表示法,即文档向量V的分量为一个布尔值,0表示相应的特征在该文档中未出现,1表示特征在文档中出现。
(2)若文档Doc采用TF向量表示法,即文档向量V的分量为相应特征在该文档中出现的频度。
2.基于支持向量机的分类器
基于支持向量机(support vector machine, SVM)的分类方法主要用于解决二元模式分类问题。
SVM的基本思想是在向量空间中找到一个决策平面(decision surface),这个平面能“最好”地分割两个分类中的数据点。支持向量机分类法就是要在训练集中找到具有最大类间界限(margin)的决策平面。
由于支持向量机算法是基于两类模式识别问题的,因而,对于多类模式识别问题通常需要建立多个两类分类器。与线性判别函数一样,它的结果强烈地依赖于已知模式样本集的构造,当样本容量不大时,这种依赖性尤其明显。此外,将分界面定在最大类间隔的中间,对于许多情况来说也不是最优的。对于线性不可分问题也可以采用类似于广义线性判别函数的方法,通过事先选择好的非线性映射将输入模式向量映射到一个高维空间,然后在这个高维空间中构造最优分界超平面。
根据Yang and Liu (1999)的实验结果,SVM的分类效果要好于NNet、贝叶斯分类器、Rocchio和LLSF(linear least-square fit)分类器的效果,与kNN方法的效果相当。
3.k-最近邻法
kNN方法的基本思想是:给定一个测试文档,系统在训练集中查找离它最近的k个邻近文档,并根据这些邻近文档的分类来给该文档的候选类别评分。把邻近文档和测试文档的相似度作为邻近文档所在类别的权重,如果这k个邻近文档中的部分文档属于同一个类别,则将该类别中每个邻近文档的权重求和,并作为该类别和测试文档的相似度。然后,通过对候选分类评分的排序,给出一个阈值。
4.基于神经网络的分类器
神经网络(NNet)是人工智能中比较成熟的技术之一,基于该技术的分类器的基本思想是:给每一类文档建立一个神经网络,输入通常是单词或者是更为复杂的特征向量,通过机器学习获得从输入到分类的非线性映射。
根据Yang and Liu (1999)的实验结果,NNet分类器的效果要比kNN分类器和SVM分类器的效果差,而且训练NNet的时间开销远远超过其他分类方法,所以,实际应用并不广泛。
5.线性最小平方拟合法
线性最小平方拟合(linear least-squares fit, LLSF)是一种映射方法其出发点是从训练集和分类文档中学习得到多元回归模型
(multivariate regression model)。其中训练数据用输入/输出向量表示,输入向量是用传统向量空间模型表示的文档
(词和对应的权重),输出向量则是文档对应的分类(带有0-1权重)。通过在向量的训练对上求解线性最小平方拟合,得到一个“单词-分类”的回归系数矩阵。
根据Yang and Liu (1999)的实验结果,LLSF算法的分类效果稍逊于kNN和SVM算法的效果。
6.决策树分类器
决策树分类器也是模式识别研究的基本方法之一,其出发点是:大量复杂系统的组成普遍存在着等级分层现象,或者说复杂任务是可以通过等级分层分解完成的,文本处理过程也不例外。
决策树是一棵树,树的根结点是整个数据集合空间,每个分结点是对一个单一变量的测试,该测试将数据集合空间分割成两个或更多个类别,即决策树可以是二叉树也可以是多叉树。每个叶结点是属于单一类别的记录。构造决策树分类器时,首先要通过训练生成决策树,然后再通过测试集对决策树进行修剪。一般可通过递归分割的过程构建决策树,其生成过程通常是自上而下的,选择分割的方法有多种,但是目标都是一致的,就是对目标文档进行最佳分割。从根结点到叶结点都有一条路径,这条路径就是一条决策“规则”。
在决定哪个属性域(field)作为目前最佳的分类属性时,一般的做法是穷尽所有的属性域,对每个属性域分裂的好坏进行量化,从而计算出最佳分裂。信息增益是决策树训练中常用的衡量给定属性区分训练样本能力的定量标准。
7.模糊分类器
按照模糊分类方法的观点,任何一个文本或文本类都可以通过其特征关键词来描述其内容特征,因此,可以用一个定义在特征关键词类上的模糊集来描述它们。
判定分类文本T所属的类别可以通过计算文本T的模糊集FT分别与其他每个文本类的模糊集Fk的关联度SR实现,两个类的关联度越大说明这两个类越贴近。
8.Rocchio分类器
Rocchio分类器是情报检索领域经典的算法,其基本思想是,首先为每一个训练文本C建立一个特征向量,然后使用训练文本的特征向量为每个类建立一个原型向量(类向量)。当给定一个待分类文本时,计算待分类文本与各个类别的原型向量(类向量)之间的距离,其距离可以是向量点积、向量之间夹角的余弦值或者其他相似度计算函数,根据计算出来的距离值决定待分类文本属于哪一类别。
Rocchio分类方法的特点是计算简单、易行,其分类效果仅次于kNN方法和SVM方法。
9.基于投票的分类方法
基于投票的分类方法是在研究多分类器组合时提出的,其核心思想是:k个专家判断的有效组合应该优于某个专家个人的判断结果。
投票算法主要有两种:Bagging算法和Boosting算法。
Bagging算法
训练R个分类器fi(i=1,2,…,R),其中,fi是利用从训练集(N篇文档)中随机抽取(取出后再放回)N次文档构成的训练集训练得到的。对于新文档D,用这R个分类器分别对D划分类别,得到的最多的那个类别作为D的最终判别类别。
Boosting算法
与Bagging算法类似,该算法需要训练多个分类器,但训练每个分量分类器的训练样本不再是随机抽取,每个分类器的训练集由其他各个分类器所给出的“最富信息”的样本点组成。基于Boosting方法有许多不同的变形,其中最流行的一种就是AdaBoost方法,该方法在文本分类领域中有着非常广泛的应用。
文本分类评测指标
针对不同的目的,人们提出了多种文本分类器性能评价方法,包括召回率、正确率、F-测度值、微平均和宏平均、平衡点(break-even point)、11点平均正确率(11-point average precision)等。
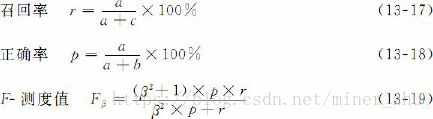
一般地讲,正确率和召回率是一对相互矛盾的物理量,提高正确率往往要牺牲一定的召回率,反之亦然。在很多情况下,单独考虑正确率或者召回率来对分类器进行评价都是不全面的。因此,1999提出了通过调整分类器的阈值,调整正确率和召回率的值,使其达到一个平衡点的评测方法。
Taghva et al.(2004)为了更加全面地评价一个分类器在不同召回率情况下的分类效果,调整阈值使得分类器的召回率分别为:0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1,然后计算出对应的11个正确率,取其平均值,这个平均值即为11点平均正确率,用这个平均正确率衡量分类器的性能。