NLP之CRF++安装及使用
目录
一、CRF简介
CRF VS 词典统计分词
CRF VS HMM,MEMM
CRF分词原理
二、CRF++工具包
CRF++的安装(linux)
CRF++的使用
一、CRF简介
Conditional Random Field:条件随机场,一种机器学习技术(模型)
CRF由John Lafferty最早用于NLP技术领域,其在NLP技术领域中主要用于文本标注,并有多种应用场景,例如:
- 分词(标注字的词位信息,由字构词)
- 词性标注(标注分词的词性,例如:名词,动词,助词)
- 命名实体识别(识别人名,地名,机构名,商品名等具有一定内在规律的实体名词)
本文主要描述如何使用CRF技术来进行中文分词。
CRF VS 词典统计分词
- 基于词典的分词过度依赖词典和规则库,因此对于歧义词和未登录词的识别能力较低;其优点是速度快,效率高
- CRF代表了新一代的机器学习技术分词,其基本思路是对汉字进行标注即由字构词(组词),不仅考虑了文字词语出现的频率信息,同时考虑上下文语境,具备较好的学习能力,因此其对歧义词和未登录词的识别都具有良好的效果;其不足之处是训练周期较长,运营时计算量较大,性能不如词典分词
CRF VS HMM,MEMM
- 首先,CRF,HMM(隐马模型),MEMM(最大熵隐马模型)都常用来做序列标注的建模,像分词、词性标注,以及命名实体标注
- 隐马模型一个最大的缺点就是由于其输出独立性假设,导致其不能考虑上下文的特征,限制了特征的选择
- 最大熵隐马模型则解决了隐马的问题,可以任意选择特征,但由于其在每一节点都要进行归一化,所以只能找到局部的最优值,同时也带来了标记偏见的问题,即凡是训练语料中未出现的情况全都忽略掉
- 条件随机场则很好的解决了这一问题,他并不在每一个节点进行归一化,而是所有特征进行全局归一化,因此可以求得全局的最优值。
CRF分词原理
1. CRF把分词当做字的词位分类问题,通常定义字的词位信息如下:
- 词首,常用B表示
- 词中,常用M表示
- 词尾,常用E表示
- 单子词,常用S表示
2. CRF分词的过程就是对词位标注后,将B和E之间的字,以及S单字构成分词
3. CRF分词实例:
- 原始例句:我爱北京天安门
- CRF标注后:我/S 爱/S 北/B 京/E 天/B 安/M 门/E
- 分词结果:我/爱/北京/天安门
CRF命名实体识别
基于CRF的命名实体识别实质上也是把它看做一个序列标注问题。
基本思路是:先进行分词,然后对人名、简单地名和简单组织名进行识别,最后识别复合地名和复合组织名。
用CRF进行命名实体识别属于有监督学习。需要大批已标注的语料对模型参数进行训练。
二、CRF++工具包
上面介绍了CRF技术思想以及如何用于分词,下面将介绍如何在实际开发中使用CRF进行分词工作。目前常见的CRF工具包有pocket crf, flexcrf 和crf++,目前网上也有一些它们3者之间的对比报告,个人感觉crf++在易用性,稳定性和准确性等综合方面的表现最好,同时在公司的项目开发中也在使用,因此下面将概述一下crf++的使用方法。
CRF++的安装(linux)
安装包官方下载地址:https://drive.google.com/drive/folders/0B4y35FiV1wh7fngteFhHQUN2Y1B5eUJBNHZUemJYQV9VWlBUb3JlX0xBdWVZTWtSbVBneU0?usp=drive_web#list(最新版0.58)
安装要求:
- C++ compiler (gcc 3.0 or higher)
安装操作:
1.解压安装包:tar –xvzf 软件包名
2.cd 进入解压后的目录,执行‘./configure’命令为编译做好准备
3.执行“make”命令进行软件编译
4.执行“make install”完成安装 (注意:需先执行“su”获取root用户权限)
5.执行“make clean”删除安装时产生的临时文件(可不执行)
文件主要内容:
doc文件夹:就是官方主页的内容。
example文件夹:有四个任务的训练数据、测试数据和模板文件。
sdk文件夹:CRF++的头文件和静态链接库。
crf_learn.exe:CRF++的训练程序。
crf_test.exe:CRF++的预测程序
libcrfpp.dll:训练程序和预测程序需要使用的静态链接库。
实际上,需要使用的就是crf_learn.exe,crf_test.exe和libcrfpp.dll,这三个文件。
CRF++的使用
和许多机器学习工具一样,CRF++的使用分为两个过程,一个是训练过程,一个是测试过程,我们先来直接阅读官方的使用教程(http://taku910.github.io/crfpp/)
1.训练和测试的数据格式
训练和测试文件必须包含多个tokens,每个token又包含多个列。token的定义可根据具体的任务,如词、词性等。每个token必须写在一行,且各列之间用空格或制表格间隔。一个token的序列可构成一个sentence,每个sentence之间用一个空行间隔。
注意最后一列将是被CRF用来训练的最终标签。
例子:He reckons the current account deficit will narrow to only #1.8 billion in September.
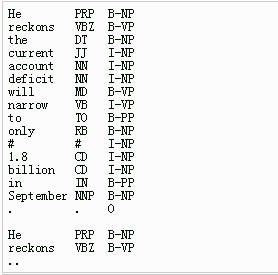
这个例子中”He reckons the current account deficit will narrow to only #1.8 billion in September .”代表一个训练语句,CRF++要求将这样的句子拆成每一个词一行并且是相同固定列数的数据,其中列除了原始输入,还可以包含一些其他信息,比如例子每个token包含3列,分别为字本身、字类型和词位标记,最后一列是Label信息,也就是标准答案yy。而不同的训练序列与序列之间的相隔,依靠一个空白行来区分。
通俗说法:训练文件由若干个句子组成(可以理解为若干个训练样例),不同句子之间通过换行符分隔,上图中显示出的有两个句子。每个句子可以有若干组标签,最后一组标签是标注,上图中有三列,即第一列和第二列都是已知的数据,第三列是要预测的标注,以上面例子为例是,根据第一列的词语和和第二列的词性,预测第三列的标注。 当然这里有涉及到标注的问题,比如命名实体识别就有很多不同的标注集。
注意:每一行的列数必须相同一致,否则系统将报错。
2.准备特征模板
CRF++训练的时候,要求我们自己提供特征模板。
2.1 模板基础
模板文件中的每一行是一个模板。每个模板都是由%x[row,col]来指定输入数据中的一个token。row指定到当前token的行偏移,col指定列位置。
由上图可见,当前token是the这个单词。%x[-2,1]就就是the的前两行,1号列的元素(注意,列也是从0开始的),即为PRP。
2.2模板类型
模板有两种类型,(模板类型)通过第一个字符指定。
Unigram template:首字符: 'U'
当给出一个"U01:%x[0,1]"的模板时,CRF++会产生如下的一些特征函数集合(func1 ... funcN) 。
这几个函数说明一下,%x[0,1]这个特征到前面的例子就是说,根据词语(第1列)的词性(第2列)来预测其标注(第3列),这些函数就是反应了训练样例的情况,func1反映了“训练样例中,词性是DT且标注是B-NP的情况”,func2反映了“训练样例中,词性是DT且标注是I-NP的情况”。
模板函数的数量是L*N,其中L是标注集中类别的数量,N是从模板中扩展处理的字符串种类数量。
Bigram template:首字符:'B'
这个模板用来描述二元特征。这个模板会自动产生当前output token和前一个output token的合并。注意,这种类型的模板会产生L * L * N种不同的特征。当类别数很大的时候,这种类型会产生许多可区分的特征,这将会导致训练和测试的效率都很低下。
Unigram feature 和 Bigram feature有什么区别呢?
unigram/bigram很容易混淆,因为通过unigram-features也可以写出类似%x[-1,0]%x[0,0]这样的单词级别的bigram(二元特征)。而这里的unigram和bigram features指定是uni/bigrams的输出标签。
这里的一元/二元指的就是输出标签的情况,这个具体的例子我还没看到,example文件夹中四个例子,也都是只用了Unigram,没有用Bigarm,因此感觉一般Unigram feature就够了。
2.3使用标识符区分相对位置
如果用户需要区分token的相对位置时,可以使用标识符。比如在下面的例子中,"%x[-2,0]"和"%x[1,0]"都代表“北”,但是它们又是不同的“北“。
北 CN B
京 CN E
的 CN S >> 当前token
北 CN S
部 CN S
为了区分它们,可以在模型中加入一个唯一的标识符(U01: 或 U02:),即:
U01:%x[-2,0]
U02:%x[1,0]
在这样的条件下,两种模型将被认为是不同的,因为他们将被扩展为”U01:北“和”U02:北”。只要你喜欢,你可以使用任何标识符,但是使用数字序号区分更很有用,因为它们只需简单的与特征数相对应。
2.4 这是CoNLL 2000的Base-NP chunking任务的模板例子。只使用了一个bigram template ('B')。这意味着只有前一个output token和当前token被当作bigram features。“#”开始的行是注释,空行没有意义。
3.训练(编码)
命令行:
% crf_learn template_file train_file model_file
其中,template_file和train_file需由使用者事先准备好。crf_learn将生成训练后的模型并存放在model_file中。
一般的,crf_learn将在STDOUT上输出下面的信息。
- iter: 迭代次数
- terr: tags的错误率(错误的tag数/所有的tag数)
- serr:sentence的错误率(错误的sentence数/所有的sentence数)
- obj:当前对象的值。当这个值收敛到一个确定的值时,CRF模型将停止迭代
- diff:与上一个对象值之间的相对差
这个训练过程的时间、迭代次数等信息会输出到控制台上(感觉上是crf_learn程序的输出信息到标准输出流上了),如果想保存这些信息,我们可以将这些标准输出流到文件上,命令格式如下:
% crf_learn template_file train_file model_file >> train_info_file
有四个主要的参数可以调整:
-a CRF-L2 or CRF-L1
规范化算法选择。默认是CRF-L2。一般来说L2算法效果要比L1算法稍微好一点,虽然L1算法中非零特征的数值要比L2中大幅度的小。
-c float
这个参数设置CRF的hyper-parameter。c的数值越大,CRF拟合训练数据的程度越高。这个参数可以调整过度拟合和不拟合之间的平衡度。这个参数可以通过交叉验证等方法寻找较优的参数。
-f NUM
这个参数设置特征的cut-off threshold。CRF++使用训练数据中至少NUM次出现的特征。默认值为1。当使用CRF++到大规模数据时,只出现一次的特征可能会有几百万,这个选项就会在这样的情况下起到作用。
-p NUM
如果电脑有多个CPU,那么那么可以通过多线程提升训练速度。NUM是线程数量。
带两个参数的命令行例子:
% crf_learn -f 3 -c 1.5 template_file train_file model_file
4.测试(解码)
命令行:
% crf_test -m model_file test_files
在测试过程中,使用者不需要指定template file,因为,mode file已经有了template的信息。test_file是你想要标注序列标记的测试语料。
有两个参数-v和-n都是显示一些信息的,-v可以显示预测标签的概率值,-n可以显示不同可能序列的概率值,对于准确率,召回率,运行效率,没有影响,这里不说明了。
与crf_learn类似,输出的结果放到了标准输出流上,而这个输出结果是最重要的预测结果信息(测试文件的内容+预测标注),同样可以使用重定向,将结果保存下来,命令行如下。
% crf_test -m model_file test_files >> result_file
参考文章:
CRF++使用小结
CRF 及CRF++ 安装与解释
CRF++源码解读
CRF++代码分析CRF++使用教程