Recent Advances in Deep Learning for Object Detection目标检测综述
文章目录
- 1. Introduction
- 1.1 传统方法
- 1.2 深度学习方法
- 2. Detection Components
- 2.1 Detection Settings
- 2.2 Detection Paradigms
- 2.2.1 Two-stage Detectors
- 2.2.2 One-stage Detectors
- 2.3 Backbone Architecture
- 2.3.1 Basic Architecture of a CNN
- 2.3.2 CNN Backbone for Object Detection
- 2.4 Proposal Generation
- 2.4.1 Traditional Computer Vision Methods
- 2.4.2 Anchor-based Methods
- 2.4.3 Keypoints-based Methods
- 2.4.4 Other Methods
- 2.5 Feature Representation Learning
- 2.5.1 Multi-scale Feature Learning
- 2.5.2 Region Feature Encoding
- 2.5.3 Contextual Reasoning
- 2.5.4 Deformable Feature Learning
- 3. Learning Strategy
- 3.1 Training Stage
- 3.1.1 Data Augmentation
- 3.1.2 Imbalance Sampling
- 3.1.3 Localization Refinemen
- 3.1.4 Cascade Learning
- 3.1.5 Others
- 3.2 Testing Stage
- 3.2.1 Duplicate Removal
- 3.2.2 Model Acceleration
- 3.2.3 Others
- 4. Applications
- 4.1 Face Detection
- 4.2 Pedestrian Detection
- 4.3 Others
- 5. Detection Benchmarks
- 5.1 Generic Detection Benchmarks
- 5.2 Face Detection Benchmarks
- 5.3 Pedestrian Detection Benchmarks
- 6. State-of-the-art for Generic Object Detection
- 7. Concluding Remarks and Future Directions
Attention:
论文解读的博客原文发布于个人github论文合集 欢迎关注,有想法欢迎一起讨论!私信评论均可。
后面有些语法在CSDN的markdown上不支持,导致显示bug,我就懒得改了,有需求直接访问原博客查看。
| 创建人 | github论文汇总 | 个人博客 | 知乎论文专栏 |
|---|---|---|---|
| ming71 | paperdaily | chaser | 专栏 |
论文发布日期:2019.8.10
综述的主体大致分为以下几部分,图示如下:
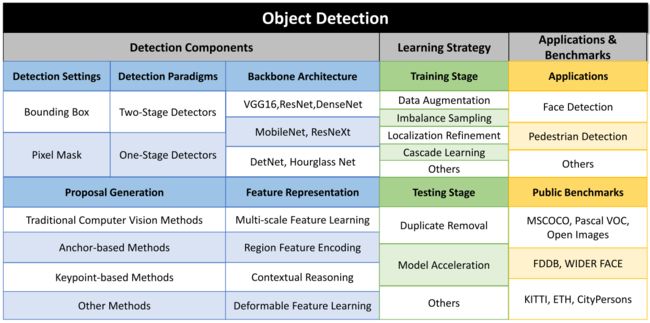
- 检测方法的组成:涵盖了检测器的分类、backbone结构、proposal设置、特征表示学习方法等
- 学习策略:训练阶段和检测阶段进行分别介绍一些学习的方法
- 应用:人脸检测、行人检测和其他
- 测试基准:一般性基准、人脸检测、行人检测基准
- 通用检测框架的SOTA方案
1. Introduction
1.1 传统方法
传统目标检测方法的思想:在多尺度图像上应用多尺度窗口进行滑窗,每个roi位置提取出固定长度的特征向量,然后采用SVM进行学习判别。这在小数据上比较奏效;传统方法的工作主要聚焦于设计更好的特征描述子,将roi信息映射为embedding feature。
传统方法的瓶颈在于:(1)大量冗余的proposal生成,导致学习效率低下,容易在分类出现大量的假正样本 (2)特征描述子都是基于低级特征进行手工设计的,难以捕捉高级语义特征和复杂内容。 (3)检测的每个步骤是独立的,缺乏一种全局的优化方案进行控制。
1.2 深度学习方法
深度学习时代以来,目标检测的发展进程部分代表的检测器如下:
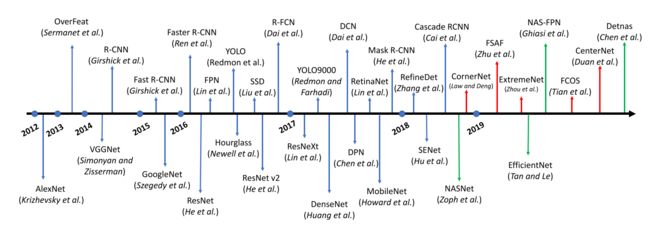
刚开始应该时面临的三个问题:(1)缺乏大规模标注数据,容易过拟合(2)算力的限制(3)可解释性不强,导致其相较SVM仍不受青睐。后来随着技术的发展,前两个的突破进展使得其应用成为现实。
2. Detection Components
2.1 Detection Settings
作者将检测设置分为两个类别:简单的目标检测任务和实例分割任务。
2.2 Detection Paradigms
分为单阶段和两阶段检测器。
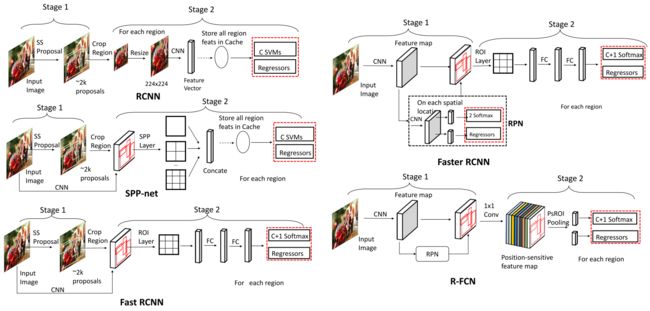
2.2.1 Two-stage Detectors
介绍了RCNN到最新的Mask Scoring RCNN等网络结构,都很常见和看过没什么值得注意的地方。图画的不错一目了然。
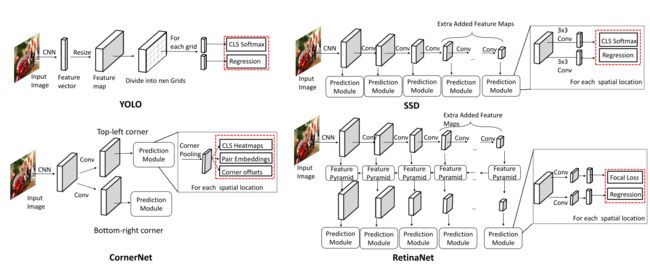
2.2.2 One-stage Detectors
从最早的OverFeat数起,到YOLO,SSD,RetinaNet,YOLOv2,CornerNet几种方法。
2.3 Backbone Architecture
2.3.1 Basic Architecture of a CNN
2.3.2 CNN Backbone for Object Detection
介绍了几种常见的backbone如VGG16,ResNet,DenseNet,ResNeXt,GoogleNet,Hourglass。
其中,提到DenseNet时指出ResNet的缺点是捷径连接中,浅层的原始特征在像素级的操作上会丢失信息,不能很好利用所有的特征;所以DenseNet采用密集连接以及concat方式充分利用之前各层的特征信息。事实证明是有效的,在较小的stage以及没有多尺度特征融合策略下提取的特征已经很丰富(但是全部的前向concat内存占用巨大)。
针对DenseNet的连接方式,在此基础上为了改进其信息组合过程中的大量冗余,提出了DPN(NIPS2017),相当于ResNet+DenseNet进行concat,既能组合新的特征,也能降低冗余。
2.4 Proposal Generation
2.4.1 Traditional Computer Vision Methods
传统方法基于低级特征如方向、边缘、色彩等,对于大的数据集不能很好地辅助表示学习,而且这个过程不能很好地嵌入到检测系统中进行统一的反馈学习和评价。虽然作者说这些方法很简单,但是实际上耗时未必就短。
2.4.2 Anchor-based Methods
常见的就是Faster RCNN提出的RPN为开山之作,后来陆续基于此工作进行改进。如DeRPN将anchor回归的四信息维度分解成两个线段信息(AAAI2019),更易回归(但是效果而言不算特别惊艳);DeepProposal(ICCV2015)从低分辨率特征图到高分辨率特征图路线预测proposal然后精炼;RefineDet(CVPR2018)将手工设计的anchor进行逐级精炼获得更好的候选区域;Cascade RCNN(CVPR2018)通过Iou阈值的match观察,通过iou阈值的筛选逐渐提高高质量proposal的比例;MetaAnchor(NIPS2018)尝试学习如何设计anchor,但是其自定义的基础anchor组仍是手工设计的(这一点和GA相似)
2.4.3 Keypoints-based Methods
这里强行将基于关键点的检测器分为两类:corner-based 和center-based。前者直接预测一对角点,代表是CornerNet;后者预测特征图上每个位置的中心点出现的概率并在此基础上预测宽高,如FSAF;还有两种思路结合的方法,如CenterNet
2.4.4 Other Methods
其他如AZNet(CVPR2016),通过将整张图片进行不断划分子区域,生成proposal,适用于物体稀疏的场景,实际效果对于一般检测不是特别好用。
2.5 Feature Representation Learning
2.5.1 Multi-scale Feature Learning
常见的多尺度学习方法有下面几种。
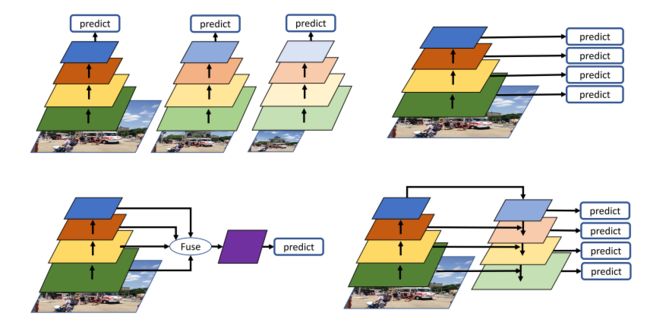
-
图像金字塔
左上所示。训练多尺度检测器进行不同尺度的检测,这样保留的图像信息最为全面,但是囿于巨大的计算消耗,一般不用。比较近的方法如SNIP使用不同样本训练独立的多尺度检测器,思路很简单并达到了不错的效果,但是这一点上有悖于严格的“通用性”。 -
特征整合
左下图所示。如ION将不同层的特征通过RoIpooling进行裁剪融合,在预测中结合了多尺度的信息;类似的还有HyperNet,Multi-scale Location-aware Kernel Representation等。这种用的不多了,一般现在都是多尺度预测,即使不是也不怎么会这样跨层直接融合(如STDN这样)。 -
预测金字塔
右上所示。最早是SSD中使用,后来还有MSCNN等使用,这种多尺度预测现在用的很多。作者还把RFBNet归到这里,RFBNet其实核心思想不是这个。 -
特征金字塔
经典的就是FPN了,针对FPN的变体十分多,思路大同小异,结果而言没有特别值得关注的新的点。
2.5.2 Region Feature Encoding
主要就是RoIPooling这部分的内容。改进从Pooling到Warping然后是Align以及清华的那个PrRoipooling,减少量化误差。其他的变式如R-FCN的PSRoIPooling;Couplenet的整合pooling输出;可变性卷积的变形RoIPooling等。
2.5.3 Contextual Reasoning
物体的出现往往和一定的上下文具有关联性,这对于网络推理信息不足的场景更适用,如遮挡、小物体等。但是其实感觉现实世界背景的关联性没有那么强,比如人可以出现在很多很复杂的环境中,这和人脸检测的强结构关联不同。所以也有文献指出盲目加上下文效果变差。
-
Global context reasoning
学习整张图片的上下文信息,并通过这些上下文信息进行目标的推断。
代表工作如ION,DeepId,改进版的Faster R-CNN。前两个都没看过,第三个是将全图embedding与区域特征concat以改善预测结果。 -
Region Context Reasoning
区域上下文推理只编码候选区域附近的上下文信息,即检测目标与其附近环境的关系。直接建模物体与其周围的关系是很难的,因为目标的周围环境具有很大的变化性,难以抽象和建模。相关工作有:
SMN模块(ICCV2017)记录关联并作为先验判断;SIN(CVPR2018)将物体作为节点,进而推理边的关系的图推理问题;设计了一种Relation Network(CVPR2018)替代掉传统的NMS过程;扩大proposal滑窗尺寸得到更广域的上下文信息然后和本ROI进行concat融合(ECCV2016);GBDNet (ECCV2016)学习门函数选择上下文信息的融合。
2.5.4 Deformable Feature Learning
可变形卷积为代表。
3. Learning Strategy
3.1 Training Stage
3.1.1 Data Augmentation
3.1.2 Imbalance Sampling
proposal的样本不平衡可分为:类别不平衡和难分程度不平衡。
-
类别不平衡
主要是proposal的背景数远多于正样本。解决方法有不均衡采样,如Faster RCNN的1:3采样;SSD中提出困难样本采样策略,将难分proposal喂给网络更新参数。 -
难度不平衡
focal loss,GHM,OHEM。
3.1.3 Localization Refinemen
这部分主要是对proposal的位置精修以便获得更准确的bbox。方法有:
(1)得到更高质量的proposal
(2)Fast R-CNN的smoothL1回归损失
(3)LocNet的连续回归(感觉和IoUNet一样)
(4)Multipath Network多尺度Roi以及多个不同阈值IoU分类器的共同学习
(5)Grid RCNN
3.1.4 Cascade Learning
级联学习其实出现地很早,并不是由Cascade RCNN先发明的。
(1)(CVPR2001)在人脸检测器中提出级联学习的思想。在早期将大量样本拒绝掉,把困难样本送到下一个stage
(2)在不同层的不同尺度目标应用layer-wise cascade classifier(CVPR2016)。思想和之前类似,将多个分类器放在不同阶段的特征图,进行样本拒绝后送入后面。
(3)Cascade RCNN的多级回归。
3.1.5 Others
-
Adversarial Learning
典型的对抗学习思想就是GAN。还有网络的对抗样本训练有助于提高网络的鲁棒性。 -
Training from Scratch
出发点是分类与检测任务不同,分类预训练模型可能对检测的初始化带来不好的对抗偏置(但是实际来看,预训练能解决很多问题,这个说法有点牵强)。
最早提出Training from Scratch的是DSOD,后来陆续有基于此的结构改进以便实现从头训练的更好收敛。包括Detnet就以这个为标准进行了比较。但是何恺明的Rethinking imagenet pre-training表示只要数据够大(10k),直接训练不逊色于fine-tune的,无关具体结构,这间接否定了一些这方面设计的工作。 -
Knowledge Distillation
两篇论文:Revisiting rcnn: On awakening the classification power of faster rcnn和Mimicking very efficient network for object detection
3.2 Testing Stage
3.2.1 Duplicate Removal
介绍NMS,soft-NMS,还有可学习的Learning NMS
3.2.2 Model Acceleration
主要是针对两阶段检测器耗时问题的解决。针对R-FCN的heavy位敏特征图,Light Head R-CNN进行简化取得不错的速度和性能的tradeoff;backbone方面有MobileNet深度可分离卷积加速特征提取;非线性计算部分有PVANet采用CReLU激活函数加速;还有一些离线加速方法,如模型压缩量化,剪枝等。
3.2.3 Others
图像金字塔的多尺度测试;数据增强。但是这些办法的问题都是时间耗费大。
4. Applications
4.1 Face Detection
人脸检测和一般性检测的区别在于:(1)人脸检测具有更大的尺度变化性、遮挡和模糊的情况 (2)只有一个类别,具有很强的结构联系信息。代表工作部分:
- S3FD(ICCV2017):侧重尺度不变性的单阶段检测器
- SSH(ICCV2017): 尺度无关性的快速单阶段人脸检测
- Finding tiny faces(CVPR2017): 级联RPN的变尺度小目标人脸检测器(慢)
- Face MegNet(WACV2018):加上下文(头发等信息比较固定),小目标转置卷积得到大特征图更好地定位
4.2 Pedestrian Detection
人脸检测和一般性检测的区别在于:(1)行人检测具有近乎固定的宽高比,但是尺度上仍有较大变化性 (2)真实世界行人检测更容易面临密集人群、遮挡、模糊等问题。例如数据集CityPersons中,验证集有3157个行人标注,其中标注gt与另一个gt的重合IoU在0.1以上的占比为48.8%;IoU为0.3以上的有26.4%,可见遮挡和拥挤十分严重。 (3)由于行人所处的复杂环境,容易产生更多的困难负样本(如交通灯、邮筒等)。
传统方法中主流的是HOG+SVM,因为行人形态的特殊性,往往HOG描述子能够起到较好的效果;深度学习应用以后就都采用深度学习 的方法,主要推出的文章解决的也是尺度问题和样本不均衡问题,其中稍有特色的:
- Repulsion Loss(CVPR2018)
- OR-CNN(ECCV2018)
4.3 Others
商标检测,视频目标检测,关节检测,车辆检测等(不感兴趣略)
5. Detection Benchmarks
常用数据集及其对应的评价指标:

5.1 Generic Detection Benchmarks
-
Pascal VOC2007
包含20个类,划分为训练/验证/测试集各2501/2510/5011张图片。 -
Pascal VOC2012
与VOC2007同样的20类,三个数据集划分为5717/5823/10991张图片。 -
MSCOCO
包含80个类,划分为训练/验证/测试集各118287/5000/40670张图片。 -
ImageNet
200类,数据量十分庞大,一般不用于检测而是分类。
5.2 Face Detection Benchmarks
常用数据集有WIDER FACE, AFW, FDDB and Pascal Face。
5.3 Pedestrian Detection Benchmarks
常用数据集有Caltech, ETH, INRIA, CityPersons and KITTI。
6. State-of-the-art for Generic Object Detection
下面的数据其实存疑,都是从别人论文里直接拿过来的,有的对比不是很合理,不用太认真比较
VOC数据集
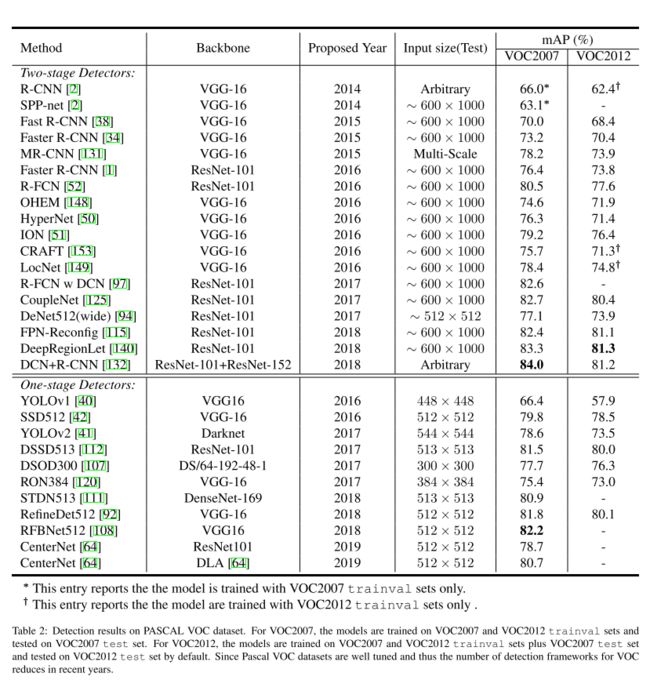
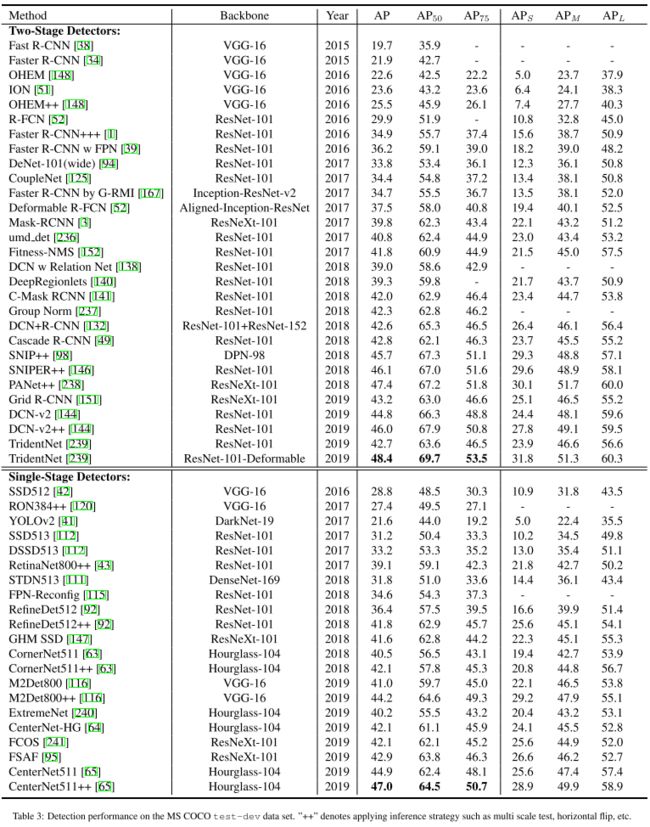
7. Concluding Remarks and Future Directions
作者认为的可能方向:
- proposal的anchor生成方式
- 对上下文信息更有效的编码
- AutoML
- 更好更大的数据集
- Low-shot目标检测
- 适用于检测任务的backbone
- 其他,如batch的大小、增强学习等