基于sklearn波士顿房价预测——线性回归实战
文章目录
- 一、导入库和数据
- 二、数据可视化
- 三、数据处理
- 1.异常数据处理
- 2.数据分割
- 3.数据归一化
- 四、模型训练和评估
一、导入库和数据
from sklearn.datasets import load_boston
import matplotlib.pyplot as plt
dataset = load_boston()
x_data = dataset.data # 导入所有特征变量
y_data = dataset.target # 导入目标值(房价)
name_data = dataset.feature_names #导入特征名
二、数据可视化
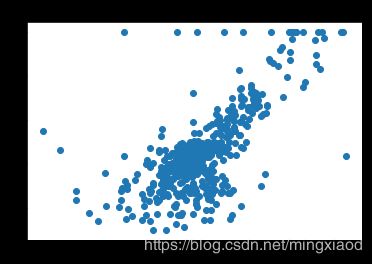
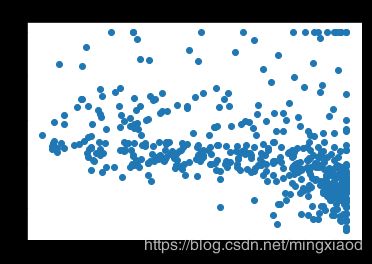
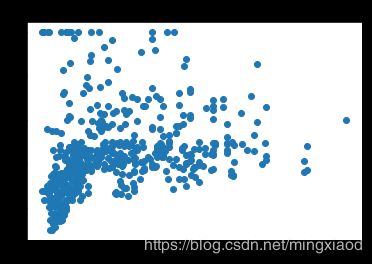
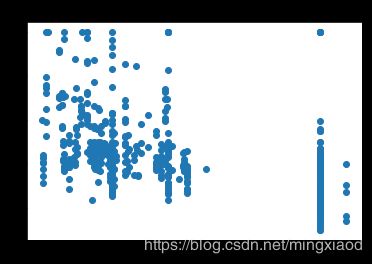
画出房价关于所有特征的散点图:
for i in range(13):
plt.subplot(7,2,i+1)
plt.scatter(x_data[:,i],y_data,s = 20)
plt.title(name_data[i])
plt.show
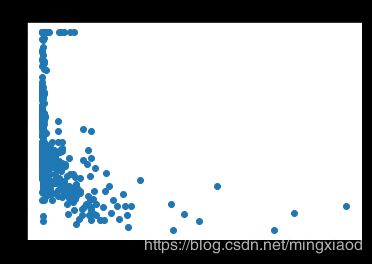
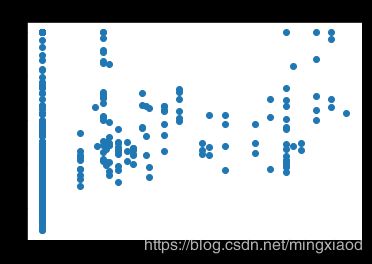
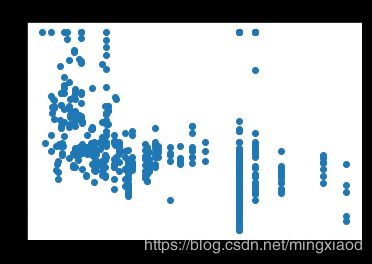

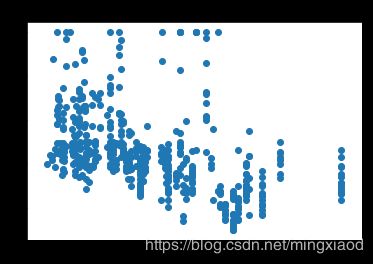

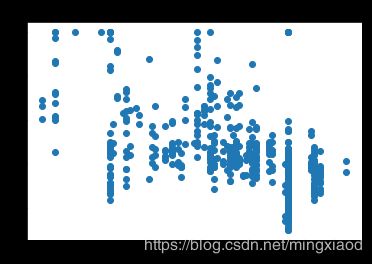
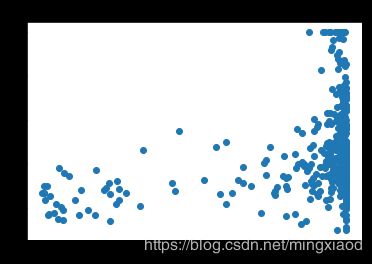
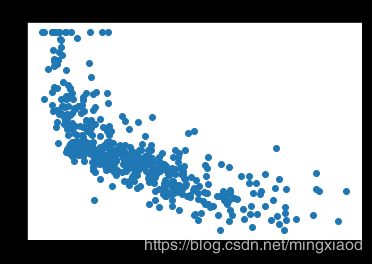
三、数据处理
1.异常数据处理
(1)有16个目标值值为50.0的数据点需要被移除。
(2)根据散点图分析,房屋的’RM’, ‘LSTAT’,'PTRATIO’特征与房价的相关性最大,所以,将其余不相关特征移除。
x_data = dataset.data
y_data = dataset.target
i_=[]
for i in range(len(y_data)):
if y_data[i] == 50:
i_.append(i)#存储房价等于50 的异常值下标
x_data = delete(x_data,i_,axis=0)#删除房价异常值数据
y_data = delete(y_data,i_,axis=0)#删除异常值
name_data = dataset.feature_names
j_=[]
for i in range(13):
if name_data[i] == 'RM'or name_data[i] == 'PTRATIO'or name_data[i] == 'LSTAT':
continue
j_.append(i)#存储其他次要特征下标
x_data = delete(x_data,j_,axis=1)#在总特征中删除次要特征
print(shape(y_data))
print(shape(x_data))
输出:
(490,)
(490, 3)
即最后剩余3个主要特征,490个样本值,490个房价值
2.数据分割
数据需要被分割为训练集和测试集:
from sklearn.cross_validation import train_test_split
import numpy as np
#随机擦痒20%的数据构建测试样本,剩余作为训练样本
X_train,X_test,y_train,y_test=train_test_split(x_data,y_data,random_state=0,test_size=0.20)
print(len(X_train))
print(len(X_test))
print(len(y_train))
print(len(y_test))
输出:
392
98
392
98
3.数据归一化
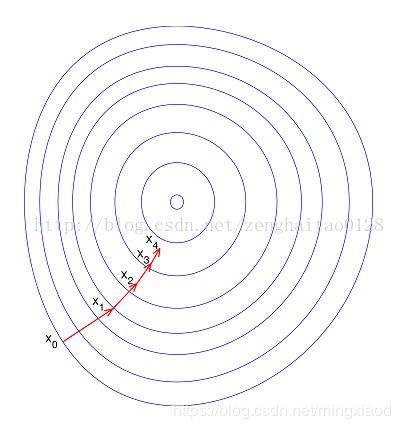
通过上面的散点图可得,每个特征的数据范围相差较大,为了加快梯度下降求最优解的速度,将它们进行归一化处理,均转化为0~1之间的数据。
归一化加速优化的原理图如下:
(1)数据未处理时:
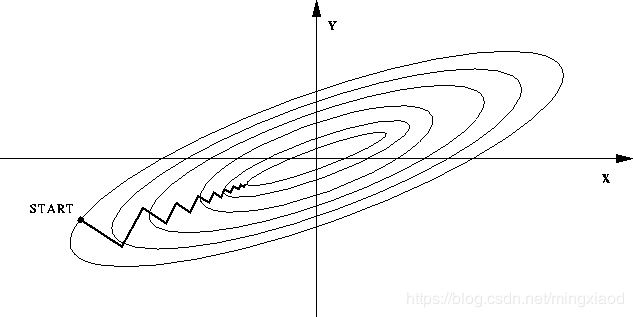
(2)归一化处理之后:
采用最大最小标准化:
#数据标归一化处理
from sklearn import preprocessing
#分别初始化对特征和目标值的标准化器
min_max_scaler = preprocessing.MinMaxScaler()
#分别对训练和测试数据的特征以及目标值进行标准化处理
X_train=min_max_scaler.fit_transform(X_train)
X_test=min_max_scaler.fit_transform(X_test)
y_train=min_max_scaler.fit_transform(y_train.reshape(-1,1))#reshape(-1,1)指将它转化为1列,行自动确定
y_test=min_max_scaler.fit_transform(y_test.reshape(-1,1))#reshape(-1,1)指将它转化为1列,行自动确定
四、模型训练和评估
(1)采用线性回归模型进行训练
#使用线性回归模型LinearRegression对波士顿房价数据进行训练及预测
from sklearn.linear_model import LinearRegression
lr=LinearRegression()
#使用训练数据进行参数估计
lr.fit(X_train,y_train)
#回归预测
lr_y_predict=lr.predict(X_test)
(2)使用R2_score对模型评估
r2_score()函数计算R^2,即确定系数,可以表示特征模型对特征样本预测的好坏。
from sklearn.metrics import r2_score
score = r2_score(y_test, lr_y_predict)
输出得分:
0.7091901425426