tensorboard使用方法以及代码实例
介绍
Tensorboard是Tensorflow的一个可视化工具,有效的展示出Tensorflow运行过程中的计算图、各种变量指标随着时间的变化趋势。实际工作中还是非常有用的。
方法
在训练过程中,主要用到了tf.summary()的各类方法:
tf.summary.scalar(name, tensor) # 生成一个summary
name:生成节点的名称
tensor:需要展示的tensor
tf.summary.histogram(name, tensor) # 直方图
name:节点名称
tf.summary.merge_all()
将此函数以上所有带有 summary 的变量聚合起来,使用起来比较省心
tf.summary.merge([loss_summary, accuracy_summary])
需要手动指定需要聚合的变量,存入参数列表中
tf.summary.FileWriter(train_log_dir, sess.graph)
打开一个writer,相当于python中的open函数,打开一个写句柄。
train_log_dir:要保存的目录
sess.graph:保存计算图(该参数可以为空)
test_summary_str = sess.run([merged_summary_test],feed_dict = {x: data,y: labels} )[0]
test_writer.add_summary(test_summary_str, i+1)
sess.run()之后,会得到一个summary字符串,将字符串和序号进行add_summary()保存
add_summary(string, i)
string:sess.run()出来的字符串
i:序号
代码演示
还是之前的vgg代码,只不过加上了tf.summary()操作,原版参照:Tensorflow使用VGG思想实现CIFAR-10十分类demo
# -*- coding:utf-8 -*-
"""
@author:老艾
@file: neuton.py
@time: 2018/08/22
"""
import tensorflow as tf
import os
import numpy as np
import pickle
# 文件存放目录
CIFAR_DIR = "./cifar-10-batches-py"
# tensorboard
# 1. 指定面板图上显示的变量
# 2. 训练过程中将这些变量计算出来,输出到文件中
# 3. 文件解析 ./tensorboard --logdir = dir.
def load_data( filename ):
'''read data from data file'''
with open( filename, 'rb' ) as f:
data = pickle.load( f, encoding='bytes' ) # python3 需要添加上encoding='bytes'
return data[b'data'], data[b'labels'] # 并且 在 key 前需要加上 b
class CifarData:
def __init__( self, filenames, need_shuffle ):
'''参数1:文件夹 参数2:是否需要随机打乱'''
all_data = []
all_labels = []
for filename in filenames:
# 将所有的数据,标签分别存放在两个list中
data, labels = load_data( filename )
all_data.append( data )
all_labels.append( labels )
# 将列表 组成 一个numpy类型的矩阵!!!!
self._data = np.vstack(all_data)
# 对数据进行归一化, 尺度固定在 [-1, 1] 之间
self._data = self._data / 127.5 - 1
# 将列表,变成一个 numpy 数组
self._labels = np.hstack( all_labels )
# 记录当前的样本 数量
self._num_examples = self._data.shape[0]
# 保存是否需要随机打乱
self._need_shuffle = need_shuffle
# 样本的起始点
self._indicator = 0
# 判断是否需要打乱
if self._need_shuffle:
self._shffle_data()
def _shffle_data( self ):
# np.random.permutation() 从 0 到 参数,随机打乱
p = np.random.permutation( self._num_examples )
# 保存 已经打乱 顺序的数据
self._data = self._data[p]
self._labels = self._labels[p]
def next_batch( self, batch_size ):
'''return batch_size example as a batch'''
# 开始点 + 数量 = 结束点
end_indictor = self._indicator + batch_size
# 如果结束点大于样本数量
if end_indictor > self._num_examples:
if self._need_shuffle:
# 重新打乱
self._shffle_data()
# 开始点归零,从头再来
self._indicator = 0
# 重新指定 结束点. 和上面的那一句,说白了就是重新开始
end_indictor = batch_size # 其实就是 0 + batch_size, 把 0 省略了
else:
raise Exception( "have no more examples" )
# 再次查看是否 超出边界了
if end_indictor > self._num_examples:
raise Exception( "batch size is larger than all example" )
# 把 batch 区间 的data和label保存,并最后return
batch_data = self._data[self._indicator:end_indictor]
batch_labels = self._labels[self._indicator:end_indictor]
self._indicator = end_indictor
return batch_data, batch_labels
# 拿到所有文件名称
train_filename = [os.path.join(CIFAR_DIR, 'data_batch_%d' % i) for i in range(1, 6)]
# 拿到标签
test_filename = [os.path.join(CIFAR_DIR, 'test_batch')]
# 拿到训练数据和测试数据
train_data = CifarData( train_filename, True )
test_data = CifarData( test_filename, False )
# 设计计算图
# 形状 [None, 3072] 3072 是 样本的维数, None 代表位置的样本数量
x = tf.placeholder( tf.float32, [None, 3072] )
# 形状 [None] y的数量和x的样本数是对应的
y = tf.placeholder( tf.int64, [None] )
# [None, ], eg: [0, 5, 6, 3]
x_image = tf.reshape( x, [-1, 3, 32, 32] )
# 将最开始的向量式的图片,转为真实的图片类型
x_image = tf.transpose( x_image, perm= [0, 2, 3, 1] )
# conv1:神经元 feature_map 输出图像 图像大小: 32 * 32
conv1_1 = tf.layers.conv2d( x_image,
32, # 输出的通道数(也就是卷积核的数量)
( 3, 3 ), # 卷积核大小
padding = 'same',
activation = tf.nn.relu,
name = 'conv1_1'
)
conv1_2 = tf.layers.conv2d( conv1_1,
32, # 输出的通道数(也就是卷积核的数量)
( 3, 3 ), # 卷积核大小
padding = 'same',
activation = tf.nn.relu,
name = 'conv1_2'
)
# 池化层 图像输出为: 16 * 16
pooling1 = tf.layers.max_pooling2d( conv1_2,
( 2, 2 ), # 核大小
( 2, 2 ), # 步长
name='pool1'
)
conv2_1 = tf.layers.conv2d( pooling1,
32, # 输出的通道数
( 3, 3 ), # 卷积核大小
padding = 'same',
activation = tf.nn.relu,
name = 'conv2_1'
)
conv2_2 = tf.layers.conv2d( conv2_1,
32, # 输出的通道数
( 3, 3 ), # 卷积核大小
padding = 'same',
activation = tf.nn.relu,
name = 'conv2_2'
)
# 池化层 图像输出为 8 * 8
pooling2 = tf.layers.max_pooling2d( conv2_2,
( 2, 2 ), # 核大小
( 2, 2 ), # 步长
name='pool2'
)
conv3_1 = tf.layers.conv2d( pooling2,
32, # 输出的通道数
( 3, 3 ), # 卷积核大小
padding = 'same',
activation = tf.nn.relu,
name = 'conv3_1'
)
conv3_2 = tf.layers.conv2d( conv3_1,
32, # 输出的通道数
( 3, 3 ), # 卷积核大小
padding = 'same',
activation = tf.nn.relu,
name = 'conv3_2'
)
# 池化层 输出为 4 * 4 * 32
pooling3 = tf.layers.max_pooling2d( conv3_2,
( 2, 2 ), # 核大小
( 2, 2 ), # 步长
name='pool3'
)
# 展平
flatten = tf.contrib.layers.flatten( pooling3 )
y_ = tf.layers.dense(flatten, 10)
# 使用交叉熵 设置损失函数
loss = tf.losses.sparse_softmax_cross_entropy( labels = y, logits = y_ )
# 该api,做了三件事儿 1. y_ -> softmax 2. y -> one_hot 3. loss = ylogy
# 预测值 获得的是 每一行上 最大值的 索引.注意:tf.argmax()的用法,其实和 np.argmax() 一样的
predict = tf.argmax( y_, 1 )
# 将布尔值转化为int类型,也就是 0 或者 1, 然后再和真实值进行比较. tf.equal() 返回值是布尔类型
correct_prediction = tf.equal( predict, y )
# 比如说第一行最大值索引是6,说明是第六个分类.而y正好也是6,说明预测正确
# 将上句的布尔类型 转化为 浮点类型,然后进行求平均值,实际上就是求出了准确率
accuracy = tf.reduce_mean( tf.cast(correct_prediction, tf.float64) )
with tf.name_scope( 'train_op' ): # tf.name_scope() 这个方法的作用不太明白(有点迷糊!)
train_op = tf.train.AdamOptimizer( 1e-3 ).minimize( loss ) # 将 损失函数 降到 最低
def variable_summary(var, name):
'''
一个变量的各种统计量,建立一个summary
:param var: 计算summary的变量
:param name: 指定命名空间,以防冲突
:return:
'''
with tf.name_scope(name):
mean = tf.reduce_mean(var)
with tf.name_scope('stddev'):
# 求标准差
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('mean', mean) # 均值
tf.summary.scalar('stddev', stddev) # 标准差
tf.summary.scalar('min', tf.reduce_min(var)) # 最小值
tf.summary.scalar('max', tf.reduce_max(var)) # 最大值
tf.summary.histogram('histogram', var) # 直方图 反应的是变量的分布
# 给六个卷积层添加summary
with tf.name_scope('summary'):
variable_summary(conv1_1, 'conv1_1')
variable_summary(conv1_2, 'conv1_2')
variable_summary(conv2_1, 'conv2_1')
variable_summary(conv2_2, 'conv2_2')
variable_summary(conv3_1, 'conv3_1')
variable_summary(conv3_2, 'conv3_2')
loss_summary = tf.summary.scalar('loss', loss)
# 存储的格式: 'loss':<10, 1.1>, <20, 1.08>
accuracy_summary = tf.summary.scalar('accurary', accuracy)
# 因为 x_image 是归一化之后的图像,不是一个真正的图像.所以需要一个归一化的逆过程
source_image = (x_image + 1) * 127.5
inputs_summary = tf.summary.image('inputs_image', source_image)
merged_summary = tf.summary.merge_all() # 将以上所有带有 summary 的变量聚合起来
merged_summary_test = tf.summary.merge([loss_summary, accuracy_summary])
# 指定文件保存路径
LOG_DIR = '.'
run_label = 'run_vgg_tensorboard'
# 只需要指定到 文件夹 即可
run_dir = os.path.join(LOG_DIR, run_label)
# 判断该文件夹是否已经创建
if not os.path.exists(run_dir):
os.mkdir(run_dir)
# 在该文件夹下创建两个文件夹,一个存放训练数据,一个存放测试数据
train_log_dir = os.path.join(run_dir, 'train')
test_log_dir = os.path.join(run_dir, 'test')
# 判断这两个文件夹是否存在
if not os.path.exists(train_log_dir):
os.mkdir(train_log_dir)
if not os.path.exists(test_log_dir):
os.mkdir(test_log_dir)
# 初始化变量
init = tf.global_variables_initializer()
batch_size = 20
train_steps = 100000
test_steps = 100
# 不是每一步summary都是要计算的可以定义一个范围,每过多少步计算一次
output_summary_every_steps = 100
with tf.Session() as sess:
sess.run( init ) # 注意: 这一步必须要有!!
# 打开一个writer句柄,向writer中写数据
train_writer = tf.summary.FileWriter(train_log_dir, sess.graph) # 参数2:显示计算图
test_writer = tf.summary.FileWriter(test_log_dir)
fixed_test_batch_data, fixed_test_batch_labels = test_data.next_batch(batch_size)
# 开始训练
for i in range( train_steps ):
# 得到batch
batch_data, batch_labels = train_data.next_batch( batch_size )
# 每 一百 次迭代,计算一次summary
eval_ops = [loss, accuracy, train_op]
should_output_summary = ((i+1) % output_summary_every_steps == 0)
if should_output_summary:
eval_ops.append(merged_summary)
# 获得 损失值, 准确率
eval_val_results = sess.run( eval_ops, feed_dict={x:batch_data, y:batch_labels} )
loss_val, acc_val = eval_val_results[0:2]
if should_output_summary:
train_summary_str = eval_val_results[-1]
train_writer.add_summary(train_summary_str, i+1)
# 因为是需要测试这里需要一个定值,方便查看,
test_summary_str = sess.run([merged_summary_test],
feed_dict = {x: fixed_test_batch_data,y: fixed_test_batch_labels} )[0]
test_writer.add_summary(test_summary_str, i+1)
# 每 500 次 输出一条信息
if ( i+1 ) % 500 == 0:
print('[Train] Step: %d, loss: %4.5f, acc: %4.5f' % ( i+1, loss_val, acc_val ))
# 每 5000 次 进行一次 测试
if ( i+1 ) % 5000 == 0:
# 获取数据集,但不随机
test_data = CifarData( test_filename, False )
all_test_acc_val = []
for j in range( test_steps ):
test_batch_data, test_batch_labels = test_data.next_batch( batch_size )
test_acc_val = sess.run( [accuracy], feed_dict={ x:test_batch_data, y:test_batch_labels } )
all_test_acc_val.append( test_acc_val )
test_acc = np.mean( all_test_acc_val )
print('[Test ] Step: %d, acc: %4.5f' % ( (i+1), test_acc ))
打开Tensorboard
命令行: tensorboard --logdir=train:‘train’,test:‘test’
浏览器: http://你的用户名:6006
可以看到如下页面,默认是SCALARS标签:
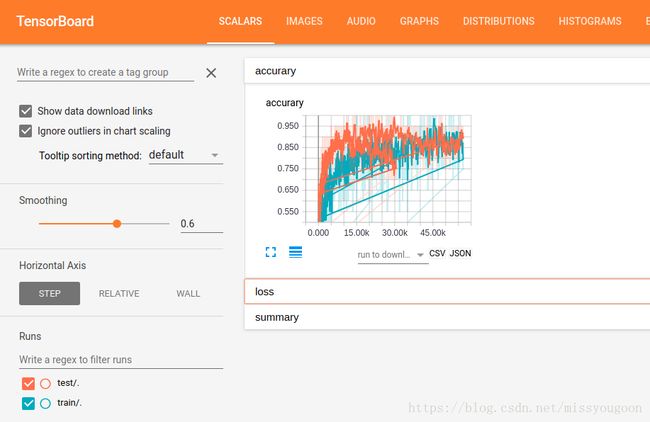
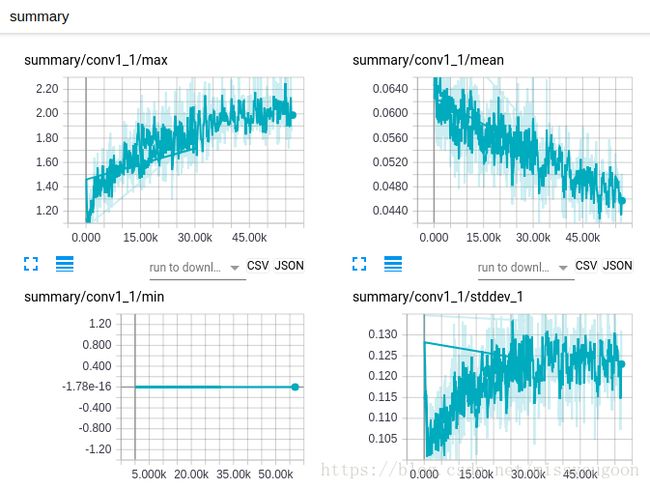
查看各个指标的状态,如各个卷积层的状态:
在IMAGES中可以查看图片:
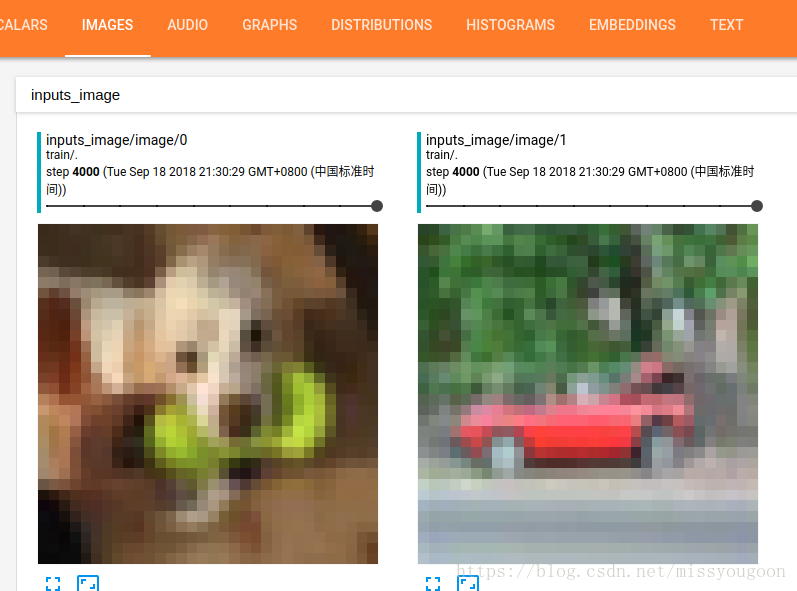
因为cifar-10数据集比较小,第一张图片应该是狗。
在GRAPHS中查看计算图
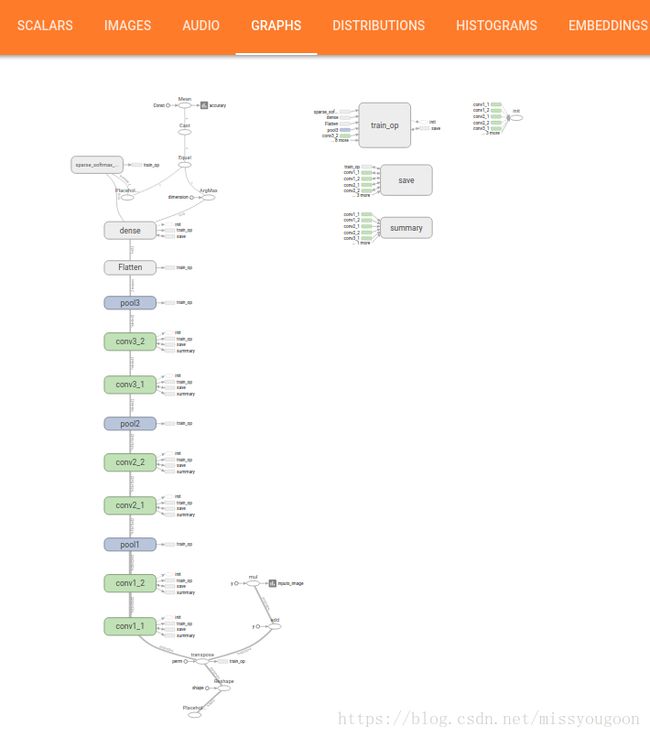
各个节点都可以点击查看详细情况
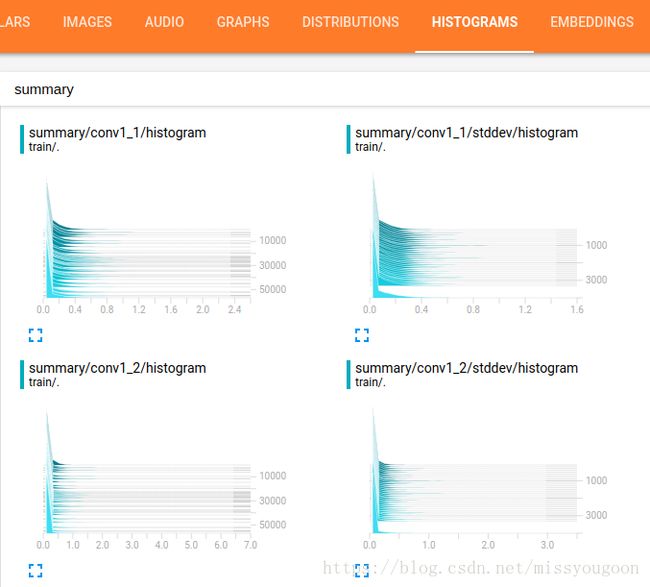
在HISTOGRAMS中查看直方图
总结
虽然写代码比较繁琐,但是还是比较好用。