TensorFlow数据验证(TensorFlow Data Validation)介绍:理解、验证和监控大规模数据
本文翻译自Medium上的一篇文章,原文: https://medium.com/tensorflow/introducing-tensorflow-data-validation-data-understanding-validation-and-monitoring-at-scale-d38e3952c2f0

今天我们推出了TensorFlow数据验证(TensorFlow Data Validation, TFDV),这是一个可帮助开发人员理解、验证和监控大规模机器学习数据的开源库。学术界和工业界都非常关注机器学习算法及其性能,但如果输入数据是错误的,所有这些优化工作都白费。理解和验证数据对于少量数据来说似乎是一项微不足道的任务,因为它们可以手动检查。然而,在实践中,数据太大,难以手动检查,并且数据通常大块连续地到达,因此有必要自动化和规模化数据分析、验证和监视任务。
TFDV是TFX平台的一部分,该技术用于每天分析和验证Google高达数PB的数据。它在早期捕获数据错误方面具有良好的表现,因此有助于TFX用户维持其机器学习管线的正常运转状况。
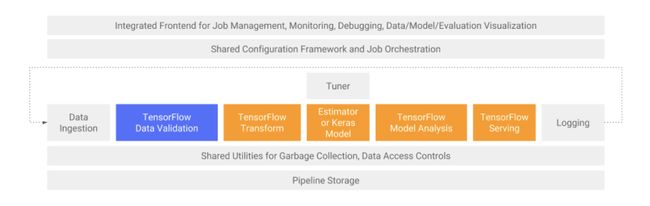
图1:TensorFlow数据验证用于TFX中的数据分析和验证
Notebook中的TensorFlow数据验证
译注:这里的Notebook指的是Jupyter Notebook,一种基于网页的交互式计算环境。
在TFDV的早期设计中,我们决定让其能在Notebook环境中使用。我们发现让数据科学家和工程师尽可能早地在他们的工作流程中使用TFDV库非常重要,以确保他们可以检查和验证他们的数据,即使他们只用一小部分数据进行探索。这将使后续过渡到大规模生产部署变得更容易。
计算和可视化描述性统计数据
TFDV的基础库里有一个功能强大的库,用于计算机器学习数据的描述性统计数据。这些统计信息用于帮助开发人员调查和了解他们的数据,以及推断出模式(稍后将详细介绍)。
TFDV API旨在使连接器能够使用不同的数据格式,并提供灵活性和扩展性。
- 连接器:TFDV使用Apache Beam来定义和处理其数据管线。因此,现有的Beam IO connectors以及用户定义的PTransforms可用于处理不同的格式和数据表示。我们为序列化的tf.Examples的CSV和TF记录提供了两个辅助函数。
# compute statistics for a CSV file
train_stats = tfdv.generate_statistics_from_csv(TRAIN_DATA)
# compute statistics for TF Record files
train_stats = tfdv.generate_statistics_from_tfrecord(TRAIN_DATA)
- 灵活性:API还允许计算自定义统计数据(除了TFDV计算的标准统计数据之外),只要此计算可以表示为Apache Beam转换。这些自定义统计信息在同一statistics.proto中序列化,可供后续的库使用。
- 扩展:TFDV创建一个Apache Beam管线,在Notebook环境中使用DirectRunner执行。同样的管线可以与其它Runner一起分发,例如 Google云平台上的DataflowRunner。Apache Flink和Apache Beam社区也即将完成Flink Runner。请关注JIRA ticket、Apache Beam博客或邮件列表获取有关Flink Runner可用性的通知。
统计信息存储在statistics.proto中,可以在Notebook中显示。
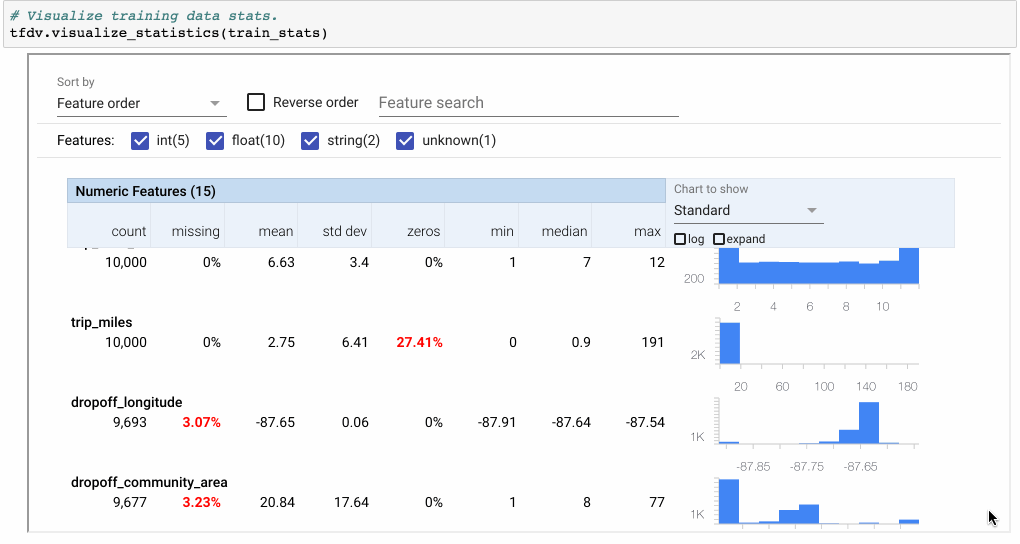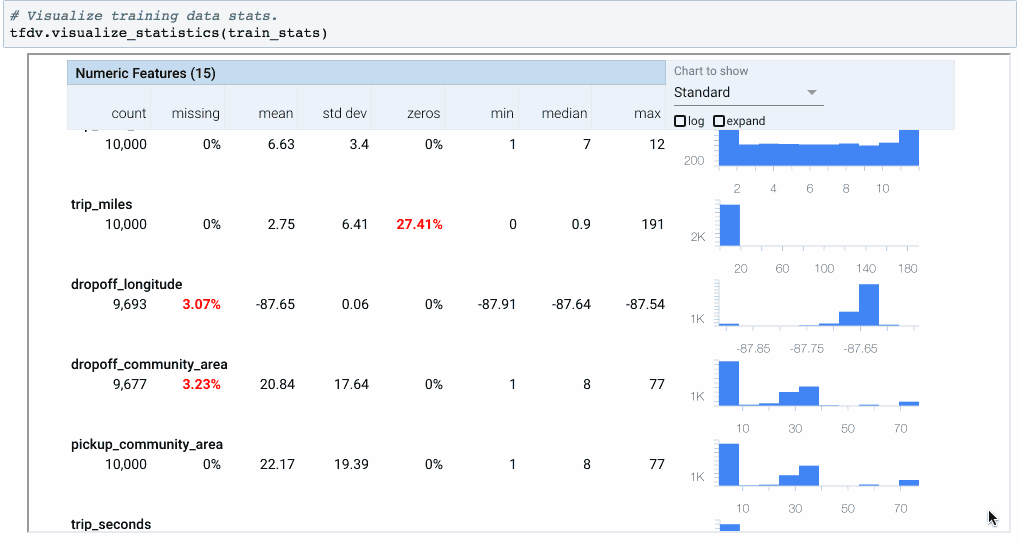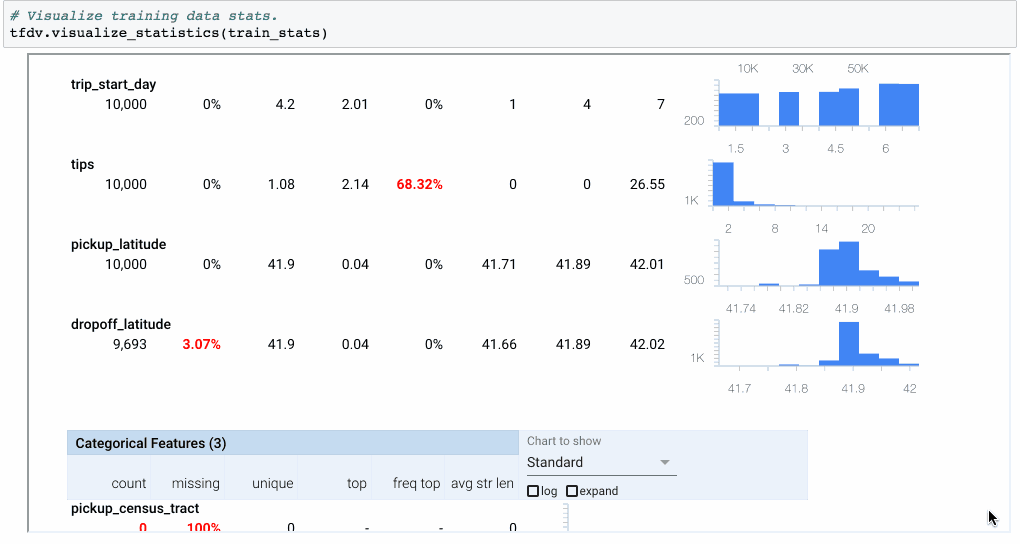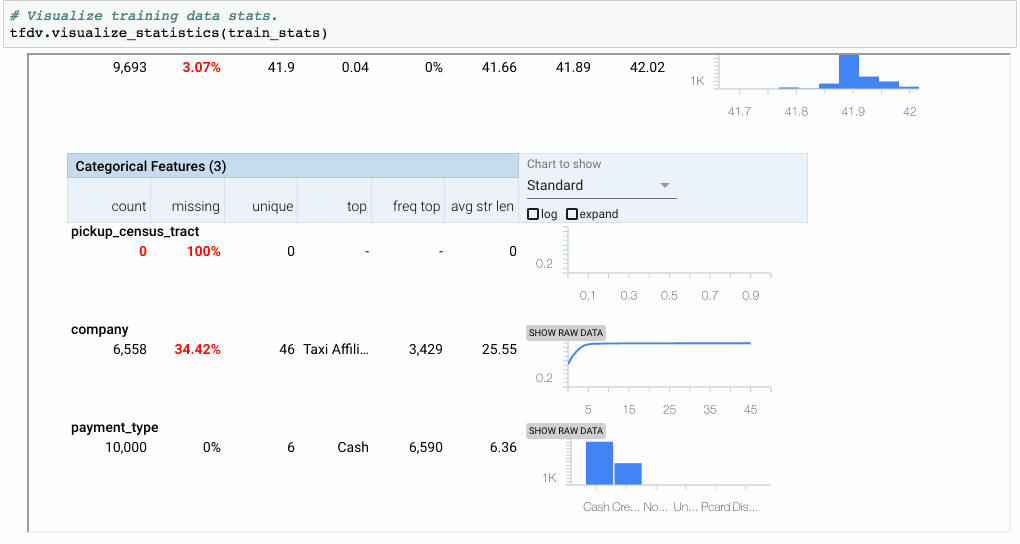
图2:statistics.proto可以可视化和内联检查(使用Facets Overview)
推断出模式(schema)
根据统计数据,TFDV推断出一种模式(由schema.proto描述),旨在反映数据的稳定特征。我们将在下面解释模式如何在TFDV中驱动数据验证。此外,该模式格式还用作TFX生态系统中其他组件的接口,例如, 它可以在TensorFlow Transform中自动解析数据。
# Infer schema based on statistics
schema = tfdv.infer_schema(train_stats)
# Display schema inline in table format
tfdv.display_schema(schema)
图3:schema.proto可以可视化和内联检查
与计算少量数据的描述性统计数据类似,编写描述训练数据期望的模式对于少量特征而言似乎微不足道。 然而,在实践中,训练数据可能包含数千个特性。infer_schema帮助开发人员首先创建一个模式(schema),然后他们可以手动优化和更新。
验证新数据
给定一个模式(schema),TFDV可以根据模式(schema)中表达的期望验证一组新数据。
# Compute statistics over a new set of data
new_stats = tfdv.generate_statistics_from_csv(NEW_DATA)
# Compare how new data conforms to the schema
anomalies = tfdv.validate_statistics(new_stats, schema)
# Display anomalies inline
tfdv.display_anomalies(anomalies)
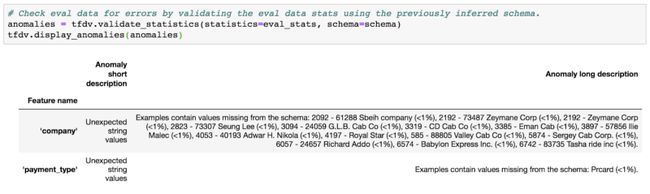
图4:异常报告概述了新数据和模式之间的差异
validate_statistics的输出存储在anomalies.proto中,描述数据如何偏离模式中编码的约束。 如果检测到的异常是数据的自然演变(例如,分类特征中的新的有效字符串值),开发人员可以检查此输出并采取措施来修复其数据中的错误或更新模式。
生产管线中的TensorFlow数据验证
在Notebook环境之外,可以使用相同的TFDV库来大规模分析和验证数据。TFX管线中TFDV的两个常见用例是连续到达数据和训练/服务偏斜检测的验证。 此外,对于TensorFlow Transform的用户,可以使用推断的模式解析预处理函数中的数据。
验证持续到达的数据
在数据连续到达的情况下,需要根据模式中编码的期望来验证新数据。在典型的设置中,模式是跨时间维护的,统计信息是根据新数据计算的,这些统计信息用于根据原始模式验证这些数据。如上所述,最初推断模式是为了方便,但它可以随着时间的推移而发展。
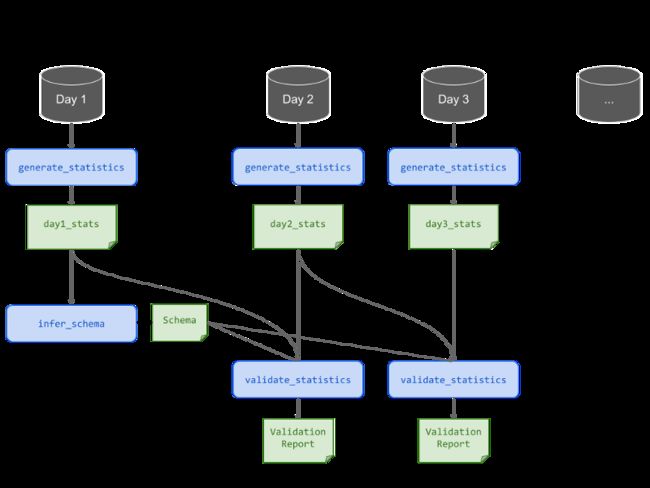
图5:使用validate_statistics验证新到达数据的示意图
还可以使用visualize_statistics命令在视觉上比较来自不同数据集(或数据的不同天数)的统计数据。
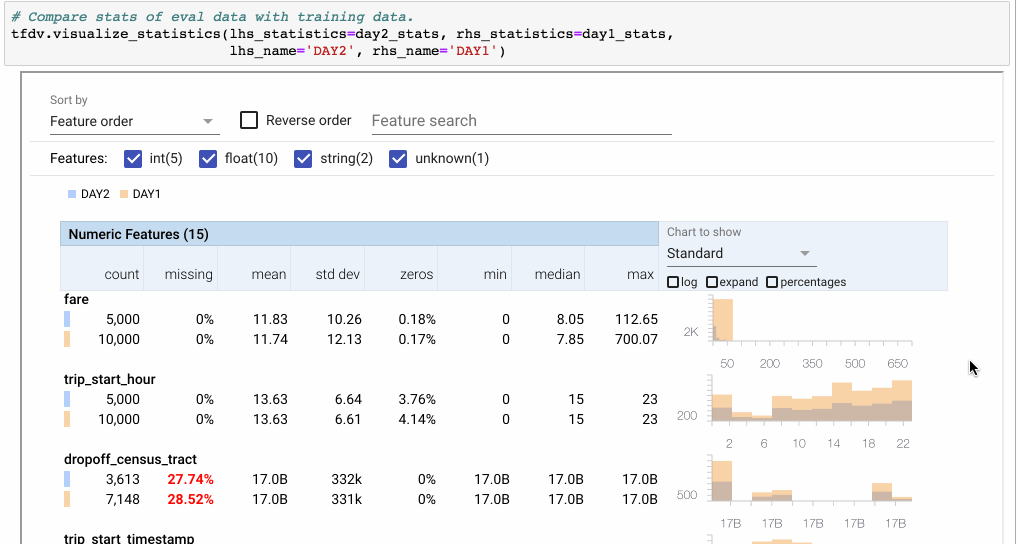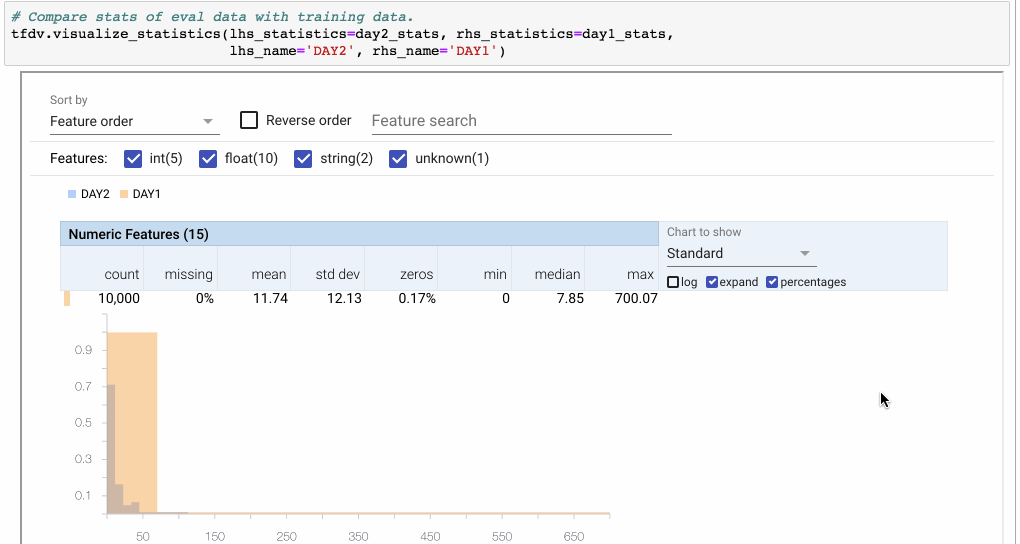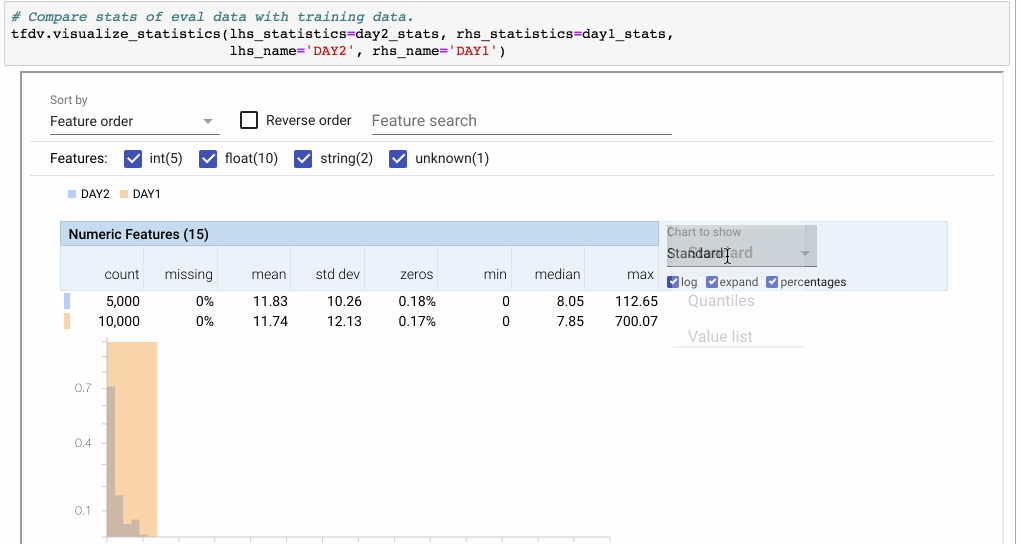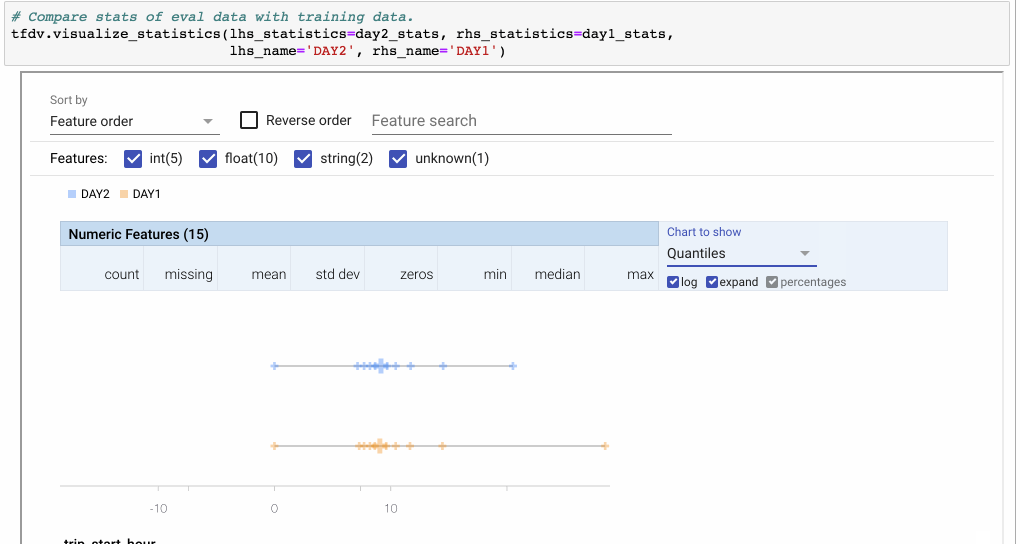
图6:使用Facets overview可视化来比较两组数据。在这里,我们比较两天之间的功能’费用’。 因为DAY2只有DAY1的一半示例,所以我们切换到百分比。 然后我们点击“展开”以放大图表。“Quantiles”视图显示分布类似,但DAY1数据集中的异常值除外。
TFDV还可以检测连续版本的训练数据之间的分布漂移。与其余验证一样,漂移的约束可以在模式中表示。TFDV使用这些约束来比较连续数据版本之间的统计信息。如果检测到漂移,则在生成的异常中包括适当的消息。
训练/服务偏斜检测
训练/服务偏斜是指用于训练模型的数据与服务系统观察到的数据之间的特征值或分布的差异。与训练数据的连续验证类似,TFDV可以计算服务日志的统计数据并使用模式执行验证,同时考虑训练和服务数据之间的任何预期差异(例如,标签存在于训练数据中但不存在于服务日志中,或者分布存在少量偏移)。 此外,Facets可以并排显示训练和服务数据的统计数据,从而突出显示潜在的错误或漂移。
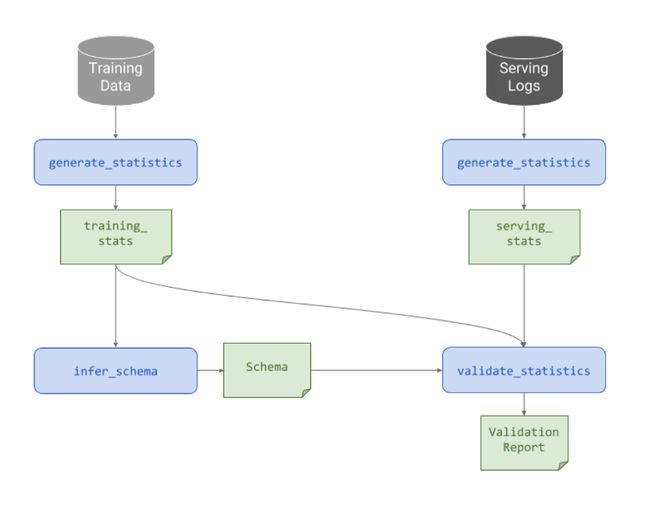
图7:使用validate_statistics比较训练和服务数据的示意图
TFDV和TensorFlow变换
TensorFlow Transform(TFT)是一个用于TensorFlow的开源库,允许用户定义预处理管线并使用大规模数据处理框架运行这些管线,同时还以导出管道,可以作为TensorFlow图的一部分运行。用户通过组合模块化Python函数来定义管线,然后tf.Transform随Apache Beam(一个用于大规模,高效,分布式数据处理的框架)执行。
TFT需要指定模式以将数据解析为张量。并非手动指定模式(通过指定每个特征的类型),而是使用TFDV推断模式从根本上简化了TFT的使用。
feature_spec = schema_utils.schema_as_feature_spec(schema).feature_spec
schema = dataset_schema.from_feature_spec(feature_spec)
如何上手TensorFlow数据验证
我们已经开源TFDV并在GitHub上通过Apache 2.0许可证在github.com/tensorflow/data-validation上发布。此版本包括如何在Notebook中使用TFDV库的示例notebook。
我们还更新了我们的端到端示例,展示了TFDV如何与TensorFlow Transform、TensorFlow Estimators、TensorFlow Model Analysis和TensorFlow Serving一起使用。我们建议您阅读并试用此示例,开始使用TFX。
我们要感谢Sudip Roy,Paul Suganthan,Ming Zhong和Martin Zinkevich的核心贡献。我们还要感谢以下同事:Ahmet Altay,Deepak Bhaduria,Robert Bradshaw,Mike Case,Charles Chen,Yifei Feng,Chuan Yu Foo,Robbie Haertel,Abhijit Karmarkar,Gus Katsiapis,Lak Lakshmanan,Billy Lamberta,Raz Mathias ,Kester Tong,Zohar Yahav,Xing Yan,Paul Yang,Xin Zhang,Lana Webb,Jarek Wilkiewicz。
