深度学习笔记——Word2vec和Doc2vec原理理解并结合代码分析
一直在用Word2vec和Doc2vec做Word Embedding和Sentence/Document EMbedding,但是刚开始用的时候对其原理一直是一知半解,只是知道怎么用而已。古人云:既要知其然,也要知其所以然。所以,结合作者论文,以及网上各位前辈的博客和开源代码之后,抽空写写自己对Word2vec和Doc2vec原理的理解,以及结合代码做一些分析。希望能够有用,有错误也请各位朋友批评指正!
将Deep Learning运用到NLP领域的朋友们肯定都接触过Embedding这个概念,Embedding其实是将词或者句子/文档向量化。想要让机器理解自然语言,首先肯定要找到一种方法将自然语言(符号)数学化。
NLP中最直观常用的一种词表示方法是one-hot方法,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。
举个例子来说:“科比”可能表示为[0001000000.....],而“篮球”可以表示为[0000000100000......]
one-hot的表示方法是一种稀疏表示方式,虽然在很多情况下one-hot表示方法已经取得了不错的效果,但是这种词表示方法也引起了一些问题。首先,one-hot表示方法可能造成维数灾难,如果词表很大,则每一个词就表示为除了该词所在的索引处为1外,其他全为0的一个很长的向量,这会给机器运算造成很大的困难。其次,one-hot表示方法表示的两个词的词向量是孤立的,不能从两个词的向量中看出两个词之间的语义关系。
为了解决one-hot的这两个缺点,又逐渐发展出了Distributed representation词向量表示方法,以及现在最火最好用的Word2vec词向量表示方法。
Word2vec
Word2vec其实是语言模型训练的一个副产品,传统的统计词向量模型使用单词在特定上下文中出现的概率表征这个句子是自然语言的概率:p(sentence) = p(word|context)。上下文context是指单词前面的特定的单词。N-gram模型又称为n元组模型, 所谓n元组是单词和它的上下文(即它前面的n-1个单词)组成的词组。
N-gram模型的另一个问题在于计算量过大, 计算一次条件概率就要扫描一遍语料库, 使得可以实际应用的深度(N值)一般为2或3。这个问题可以采用拟合的方法来解决即预测法。神经网络模型即计算部分概率值用于训练神经网络, 然后使用神经网络预测其它概率值。
其实,Word2vec的训练过程可以看做是通过神经网络机器学习算法来训练N-gram 语言模型,并在训练过程中求出word所对应的vector的方法。根据语言模型的不同,又可分为“CBOW”和“Skip-gram”两种模型。而根据两种降低训练复杂度的方法又可分为“Hierarchical Softmax”和“Negative Sampling”。两种模式和两种方法进行组合,所以实际上是有四种实现。
接下来我们先看看“CBOW”和“Skip-gram”这两种模型:
CBOW
CBOW(Continuous Bag-of-Word Model)又称连续词袋模型,是一个三层神经网络。如下图所示,该模型的特点是输入已知上下文,输出对当前单词的预测。
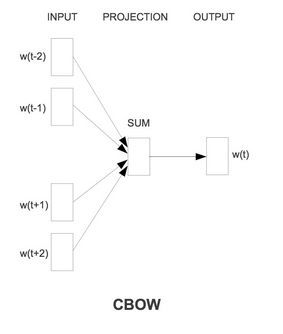
CBOW模型的训练过程如下图所示:
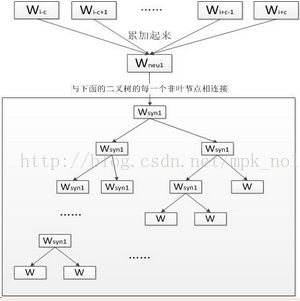
第一层是输入层,首先选定一个窗口大小,当前单词为Wi,每一个词随机初始化一个K维向量,则CBOW模型的输入是当前词的上下文窗口内的词的词向量,中间层(隐层)将上下文词的向量累加(或者求均值)得到中间向量(K维),第三层是一颗哈夫曼树,叶节点代表语料里所有的词(语料含有V个独立的词,则二叉树有|V|个叶节点)。对于一个叶节点(即语料库中的一个词),如果记左子树为1,右子树为0,就会有一个全局的编码,例如“01001”。接下来,隐层的每一个节点(K维)都会跟哈夫曼树的非叶结点有联系,每一个非叶结点其实是一个二分类的Softmax,它将中间向量的每一个节点分到树的左右子树上。
整个训练过程如下:
1.根据语料库建立词汇表V,V中的所有词均初始化一个K维向量,并根据词频构建哈夫曼树;
2.将语料库中的文本依次进行训练,以一个文本为例,将单词Wi的上下文窗口内的词向量输入模型,由隐层累加(或求均值),得到K维的中间向量Wnew。Wnew在哈夫曼树中沿着某个特定的路径到达某个叶子节点(即当前词Wi);
3.由于已知Wi,则根据Wi的哈夫曼编码,可以确定从根节点到叶节点的正确路径,也确定了路径上所有分类器(非叶结点)上应该作出的预测。举例来说,如果Wi的编码为“01101”,则从哈夫曼树的根节点开始,我们希望中间向量与根节点相连经过Softmax计算分为0的概率接近于1,在第二层输入1的概率接近于1,以此类推,直至到达叶子节点;
4.根据3中一直进行下去,把一路上计算得到的概率想乘,即可得到Wi在当前网络下的概率P,那么残差就是(1-P),于是就可以采用梯度下降法调整路径中非叶结点的参数,以及最终上下文词的向量,使得实际路径向正确路径靠拢,经过n次迭代收敛后,即可得到每个词的向量表示。
Skip-gram
Skip-gram模型的最大特点是:由当前词预测上下文词
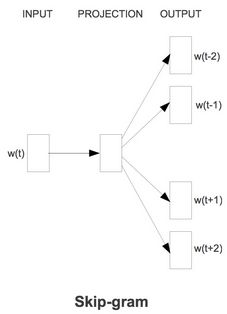
Skip-gram模型的训练过程如下图所示:

与CBOW模型不同的是,Skip-gram模型输入层不再是多个词向量,而是只有一个词向量,所以不用做隐层的向量累加。此外,Skip-gram模型需要用当前词预测上下文窗口中的每一个词。
具体的训练过程如下:
1.根据语料库建立词汇表V,V中的所有词均初始化一个K维向量,并根据词频构建哈夫曼树;
2.将语料库中的文本依次进行训练,以一个文本为例,将当前单词Wi的词向量输入模型;
3.由于已知Wi的上下文词,则根据Wi上下文词的哈夫曼编码,可以确定从根节点到叶节点的正确路径,也确定了路径上所有分类器(非叶结点)上应该作出的预测,则将当前词的向量输入哈夫曼树的根节点一路行进到某个叶子节点,即为完成了一次预测,根据梯度下降算法更新路径中非叶结点的参数以及Wi的向量;
4.重复3中的步骤,直到预测完所有的上下文词。
使用哈夫曼树的作用:如果不适用哈夫曼树,而是直接从隐层计算每一个输出的概率——即传统的Softmax,则需要对词汇表V中的每一个词都计算一遍概率,这个过程的时间复杂度是O|V|,而如果使用了哈夫曼树,则时间复杂度就降到了O(log2(|V|))。另外,由于哈夫曼树的特点,词频高的编码短,这样就更加快了模型的训练过程。
其实,上面介绍的CBOW和Skip-gram模型就是在Hierarchical Softmax方法下实现的,还记得我们一开始提到的还有一种Negative Sampling方法么,这种方法也叫作负采样方法。从上面我们可以看出,无论是CBOW还是Skip-gram模型,其实都是分类模型。对于机器学习中的分类任务,在训练的时候不但要给正例,还要给负例。对于Hierarchical Softmax来说,负例其实就是哈夫曼树的根节点。对于Negative Sampling,负例是随机挑选出来的。据说Negative Sampling能提高速度、改进模型质量。
还记得刚开始我们提到的么,Word2vec其实是N-gram模型训练的副产品,以CBOW模型为例,我们的目标函数是最大化:L=P(u|context),如果采用Negative Sampling,如果u是正例,则P(u|context)越大越好,如果u是负例,则P(u|context)越小越好。另外,需要注意,负采样应该保证频次越高的样本越容易被采样出来。
接下来我们结合代码来看一下Word2vec的实现细节:
CBOW模型对输入context的向量求和,经由along_huffman方法进行一次预测并得到误差,最后根据误差更新context的词向量:
def CBOW(self, word, context):
if not word in self.word_dict:
return
# get sum of all context words' vector
word_code = self.word_dict[word]['code']
gram_vector_sum = np.zeros([1, self.vec_len])
for i in range(len(context))[::-1]:
context_gram = context[i] # a word from context
if context_gram in self.word_dict:
gram_vector_sum += self.word_dict[context_gram]['vector']
else:
context.pop(i)
if len(context) == 0:
return
# update huffman
error = self.along_huffman(word_code, gram_vector_sum, self.huffman.root)
# modify word vector
for context_gram in context:
self.word_dict[context_gram]['vector'] += error
self.word_dict[context_gram]['vector'] = preprocessing.normalize(self.word_dict[context_gram]['vector'])Skip-gram模型用当前词预测上下文词,对于context中的每一个词都要进行一次迭代预测,每一次迭代都进行一次更新:
def SkipGram(self, word, context):
if not word in self.word_dict:
return
word_vector = self.word_dict[word]['vector']
for i in range(len(context))[::-1]:
if not context[i] in self.word_dict:
context.pop(i)
if len(context) == 0:
return
for u in context:
u_huffman = self.word_dict[u]['code']
error = self.along_huffman(u_huffman, word_vector, self.huffman.root)
self.word_dict[word]['vector'] += error
self.word_dict[word]['vector'] = preprocessing.normalize(self.word_dict[word]['vector'])along_huffman方法进行一次预测,并得到误差:
def along_huffman(self, word_code, input_vector, root):
node = root
error = np.zeros([1, self.vec_len])
for level in range(len(word_code)):
branch = word_code[level]
p = sigmoid(input_vector.dot(node.value.T))
grad = self.learn_rate * (1 - int(branch) - p)
error += grad * node.value
node.value += grad * input_vector
node.value = preprocessing.normalize(node.value)
if branch == '0':
node = node.right
else:
node = node.left
return errorDoc2vec
虽然Word2vec表示的词性量不仅考虑了词之间的语义信息,还压缩了维度。但是,有时候当我们需要得到Sentence/Document的向量表示,虽然可以直接将Sentence/Document中所有词的向量取均值作为Sentence/Document的向量表示,但是这样会忽略了单词之间的排列顺序对句子或文本信息的影响。基于此,大神Tomas Mikolov 提出了 Doc2Vec方法。Doc2vec模型其实是在Word2vec模型的基础上做出的改进,基本思路很接近,所以在这里就简单总结一下Doc2vec特有的一些东西。
与Word2vec一样,Doc2Vec也有两种模型,分别为:Distributed Memory(DM)和Distributed Bag of Words(DBOW)。DM模型在给定上下文和文档向量的情况下预测单词的概率,DBOW模型在给定文档向量的情况下预测文档中一组随机单词的概率。其中,在一个文档的训练过程中,文档向量共享(意味着在预测单词的概率时,都利用了真个文档的语义)。
其实,知道Word2vec原理的朋友们一看就会知道,Doc2vec的DM模型跟Word2vec的CBOW很像,DBOW模型跟Word2vec的Skip-gram很像。
接下来,我们先看一下Doc2vec的DM模型:
DM

DM模型在训练时,首先将每个文档ID和语料库中的所有词初始化一个K维的向量,然后将文档向量和上下文词的向量输入模型,隐层将这些向量累加(或取均值、或直接拼接起来)得到中间向量,作为输出层softmax的输入。在一个文档的训练过程中,文档ID保持不变,共享着同一个文档向量,相当于在预测单词的概率时,都利用了真个句子的语义。
DBOW

DBOW模型的输入是文档的向量,预测的是该文档中随机抽样的词。
Word2Vec和Doc2vec的一些开源实现
Word2vec和Doc2vec的现在已经有了各个版本的实现,有C语言实现的版本,Java语言实现的版本,Python语言实现的版本。我只用过Java版本和Python版本,所以这里列一下这两个版本。
Java版本实现:Java版本Word2vec和Doc2vec
Python版本实现:Python版本Word2vec和Doc2vec
再次声明,本文只是自己学习过程中的个人总结,如有错误,还请包涵指正。