yolov3神经网络训练(采集图片 制作数据集 分析训练结果)
本文主要是记录yolov3的一个完整的训练分析流程,以后忘了的时候自己看一看就能想起来了,附上所有代码(主要是提醒自己一些细节,不保证代码在别处也直接可以使用),可能适合有一定基础的人
一 采集图片
使用机器人平台上的工业相机,在ros上保存相机数据为rosbag形式,在将rosbag中相片导出来,方法为写一个roslaunch文件
参考http://wiki.ros.org/rosbag/Tutorials/Exporting%20image%20and%20video%20data
默认以每秒10帧的形式将图片解析出来(可能和相机采样率不一致)
二 制作数据集
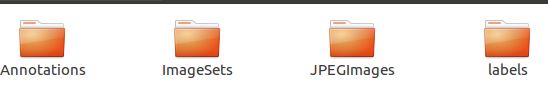
数据集文件夹中主要包含这四个部分,第一个文件中为标注图片的xml文件
第二个文件夹中建一个main文件夹,里面放上训练的图片的名称和测试图片名称的txt文件(图片名称不要带.jpg\png的后缀名)
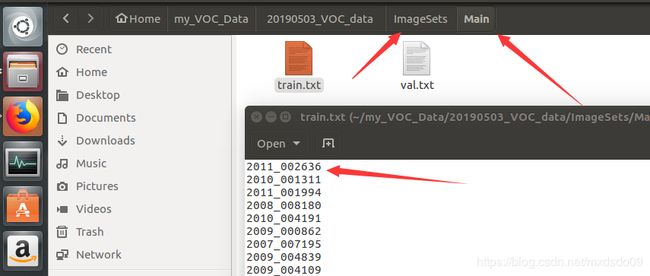
第三个文件夹放训练使用的图片
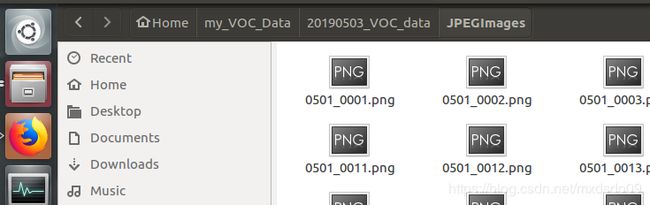
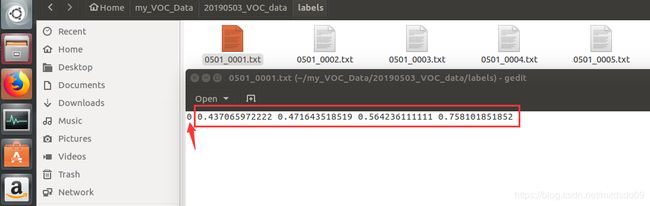
第四个文件夹下放图片对应的txt文件,里面包含了根据图片标注结果xml生产的目标类别
介绍完训练要制作的数据集的结构后,现在来讲一下每个文件夹下的东西怎么获得
首先是将第一步采集的图片放在JPEGImages文件夹下;
然后通过标注精灵这款软件,标注目标得到对应的xml文件,放在Annotations下
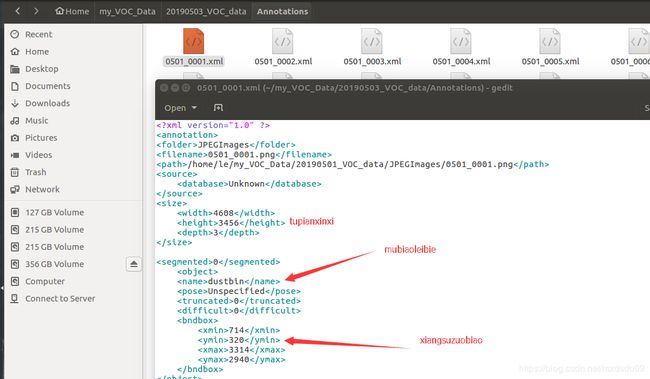
通过下面这段代码获得ImageSets/Main下面的train.txt和val.txt(原理相当于从图片中随机选一定比例的作为训练集合验证集)
import os
import random
from os import listdir, getcwd
from os.path import join
if __name__ == '__main__':
source_folder='/home/le/my_VOC_Data/20190501_VOC_data/JPEGImages/'
dest='/home/le/my_VOC_Data/20190503_VOC_data/ImageSets/Main/train.txt'
dest2='/home/le/my_VOC_Data/20190503_VOC_data/ImageSets/Main/val.txt'
file_list=os.listdir(source_folder)
train_file=open(dest,'a')
val_file=open(dest2,'a')
for file_obj in file_list:
file_path=os.path.join(source_folder,file_obj)
file_name,file_extend=os.path.splitext(file_obj)
random_num = random.randint(0,99)
if (random_num < 92):
train_file.write(file_name+'\n')
else :
val_file.write(file_name+'\n')
train_file.close()
val_file.close()根据刚刚生成的训练集和验证集,使用voc_label.py自动生成labels下每个图片的txt文件,注意要修改classes中的类别与想检查的类别相一致.
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('train'), ('val')]
classes = ["dustbin", "exit"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('/home/le/my_VOC_Data/20190509_VOC_data/Annotations/%s.xml'%(image_id))
out_file = open('/home/le/my_VOC_Data/20190509_VOC_data/labels/%s.txt'%(image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('/home/le/my_VOC_Data/20190509_VOC_data/labels/'):
os.makedirs('/home/le/my_VOC_Data/20190509_VOC_data/labels/')
image_ids = open('/home/le/my_VOC_Data/20190509_VOC_data/ImageSets/Main/%s.txt'%(image_set)).read().strip().split()
list_file = open('%s.txt'%( image_set), 'w')
for image_id in image_ids:
##list_file.write('%s/home/le/my_VOC_Data/JPEGImages/%s.png\n'%(wd, image_id))
list_file.write('/home/le/my_VOC_Data/20190509_VOC_data/JPEGImages/%s.jpg\n'%(image_id))
convert_annotation(image_id)
list_file.close()
除了会在labels下生成每个图片的txt文件,还会根据之前Main文件夹下的train.txt和val.txt生成对应txt,里面分别包含了图片的训练集路径和验证集路径,这样训练的数据集就制作完成了.
三 修改训练神经网络的配置文件
在darknet/cfg文件夹下找到yolov3_voc.cfg,修改其参数
[net]
# Testing 测试时使用
#batch=1
#subdivisions=1
# Training 训练时使用
batch=64
subdivisions=16
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 50200
policy=steps
steps=35000,45000
scales=.1,.1
...
...
...
[convolutional]
size=1
stride=1
pad=1
filters=21 #只要修改classes上的那一个filters,修改为(classes个数+5)*3,我只有两个类别,所以是(2+5)*3=21,
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=2 #修改为你自己的类别数,整个cfg文件里应该要修改三处classes和上面的filters
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
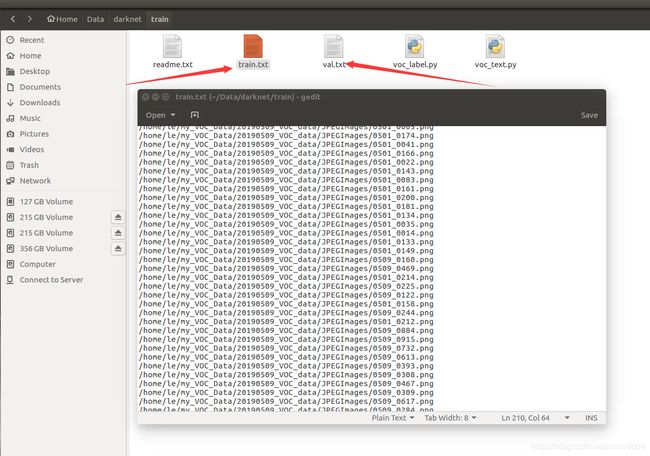
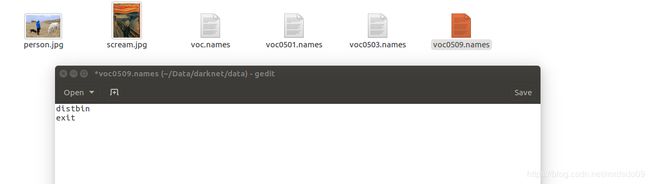
random=1接着修改darknet/data文件夹下的voc.names,把内容用自己类别代替(注意顺序和之前写的顺序要相同,否则可能会出现检查出来问题类别出错的问题.如果修改了voc.names的名称要在darknet.c中搜voc.names修改源码调用自己的文件或者在命令行直接指定使用自己的.names文件,否则也会出现能检测物体但类别会出错的问题)
最后一步,写好训练时需要调用的文件在哪,修改darknet/cfg找到voc.data
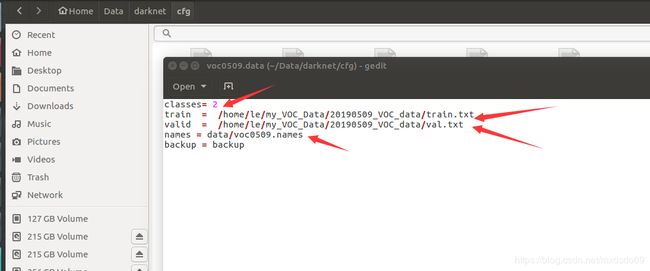
修改为自己的类别数,以及前面voc_labels.py代码生产的train.txt和val.txt所在位置,这两个文件里包含了训练集和验证集图片的具体位置.
配置修改完成
四 训练及保存输出
使用如下命令进行训练,并将输出至命令行的信息保存成log文件,该版本为指定gpu 0进行训练,可以同时指定多个GPU进行训练
./darknet detector train cfg/voc0509.data cfg/my-yolov3-voc0509.cfg darknet53.conv.74 -gpu 0 | tee log/0509.log
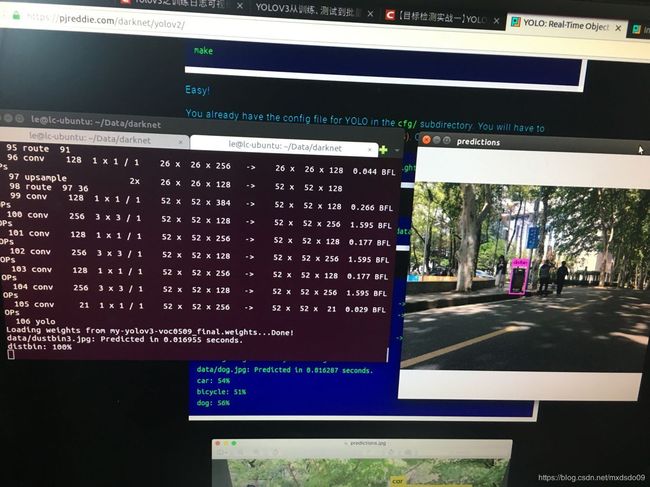
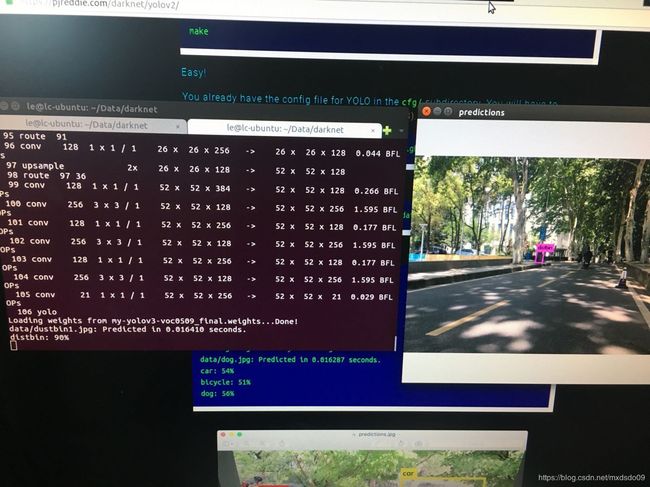
五 分析训练结果并绘制loss曲线图
打开我们保存的0509.log文件,可以看到其保存了命令行输出的所有信息,我们只需要每个batch的loss值画图来分析训练的最终结果
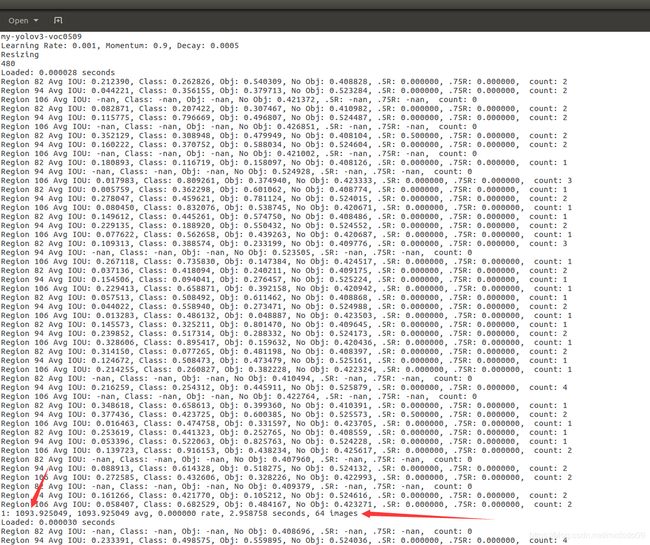
用以下代码提取出loss行
# coding=utf-8
# 该文件用来提取训练log,去除不可解析的log后使log文件格式化,生成新的log文件供可视化工具绘图
import inspect
import os
import random
import sys
def extract_log(log_file,new_log_file,key_word):
with open(log_file, 'r') as f:
with open(new_log_file, 'w') as train_log:
#f = open(log_file)
#train_log = open(new_log_file, 'w')
for line in f:
# 去除多gpu的同步log
if 'Syncing' in line:
continue
# 去除除零错误的log
if 'nan' in line:
continue
if key_word in line:
train_log.write(line)
f.close()
train_log.close()
extract_log('0509.log','train_log_loss.txt','images')
extract_log('0509.log','train_log_iou.txt','IOU')接着将loss值画出曲线图,注意修改参数使图像更加美观
#!/usr/bin/python
#coding=utf-8
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#根据自己的log_loss.txt中的行数修改lines, 修改训练时的迭代起始次数(start_ite)和结束次数(end_ite)。
lines = 25100
start_ite = 1 #log_loss.txt里面的最小迭代次数
end_ite = 25100 #log_loss.txt里面的最大迭代次数
step = 20 #跳行数,决定画图的稠密程度
igore = 3000 #当开始的loss较大时,你需要忽略前igore次迭代,注意这里是迭代次数
y_ticks = [0.05, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9,1]#纵坐标的值,可以自己设置。
data_path = 'train_log_loss.txt' #log_loss的路径。
result_path = 'avg_loss' #保存结果的路径。
####-----------------只需要改上面的,下面的可以不改动
names = ['loss', 'avg', 'rate', 'seconds', 'images']
result = pd.read_csv(data_path, skiprows=[x for x in range(lines) if (x最终画出的loss曲线图,可以看出loss不断收敛,并且在20000~35000时已经基本收敛,变化不明显,由于训练时cfg设置了在35000学习率降低10倍,35000~40000时又稍微减小了一点,最后稳定在0.013左右
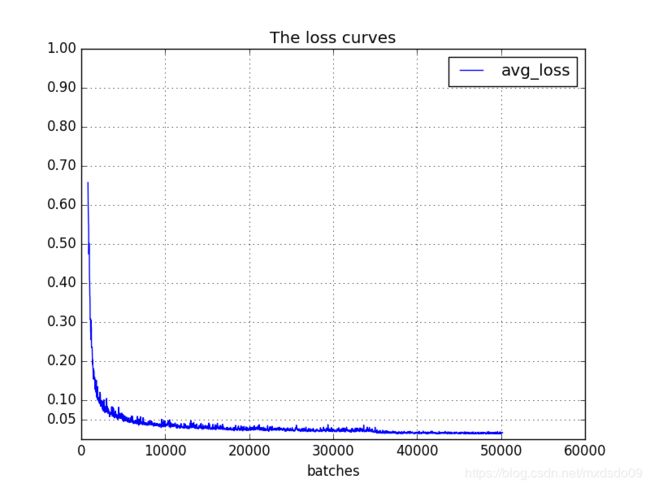
最后结果