Xgboost实践+天池比赛O2O优惠券auc接近天池第一名0.81(auc0.80,支持CPU、GPU源代码下载链接)
0. 前言
-
本次实践的是[天池比赛O2O优惠券赛题]https://tianchi.aliyun.com/competition/entrance/231593/information ,由于是初接触机器学习,所以参考了天池技术圈等很多博客,关于该赛题的思路,网上已经有很多篇写的很好的文章了(见下面参考博客),我在这里主要是记录下我自己将该赛题的分数从0.53一直提升到0.80的过程,留作学习记录。
-
关于该赛题的思路可以参考如下博客:
[1]. [Xgboost实践+第一名天池o2o优惠券的使用预测思路完整版]
https://blog.csdn.net/weixin_42001089/article/details/85013073[2]. [[天池竞赛系列]O2O优惠券使用预测复赛第三名思路]
https://tianchi.aliyun.com/notebook-ai/detail?postId=8462 -
本篇文章接下来的所有源码及数据如下:
https://github.com/myourdream/tianchi_O2O_predict -
使用GPU的环境及遇到的问题解决办法请参考我的另外两篇博客:
[1]. https://blog.csdn.net/myourdream2/article/details/86586281
[2]. https://blog.csdn.net/myourdream2/article/details/86603300
1. auc0.53
在天池新人赛报名之后,就先到技术圈去学习了下,看到一个100行代码入门天池O2O优惠券使用新人赛【精简教程版】,就拿来练了下手,运行很顺利,代码也相对比较简单,部分代码如下所示:
-
【使用的库】
import os, sys, pickle import numpy as np import pandas as pd import matplotlib.pyplot as plt from datetime import date from sklearn.linear_model import SGDClassifier, LogisticRegression dfoff = pd.read_csv('datalab/1990/data/ccf_offline_stage1_train.csv') dftest = pd.read_csv('datalab/1990/data/ccf_offline_stage1_test_revised.csv') dfon = pd.read_csv('datalab/1990/data/ccf_online_stage1_train.csv') print('data read end.') -
【使用的模型】
# feature original_feature = ['discount_rate','discount_type','discount_man', 'discount_jian','distance', 'weekday', 'weekday_type'] + weekdaycols print("----train-----") model = SGDClassifier(#lambda: loss='log', penalty='elasticnet', fit_intercept=True, max_iter=100, shuffle=True, alpha = 0.01, l1_ratio = 0.01, n_jobs=1, class_weight=None ) model.fit(train[original_feature], train['label']) -
【使用的feature】
# feature original_feature = ['discount_rate','discount_type','discount_man', 'discount_jian','distance', 'weekday', 'weekday_type'] + weekdaycols -
【提交后结果为0.53,如下图所示:】
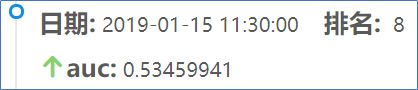
-
【结果分析:】
分数不高的原因是使用的feature很简单,几乎未进行特征工程的处理。
2. auc0.78
通过100行代码入门天池O2O优惠券之后,想着进一步优化结果,看到了 [[Xgboost实践+第一名天池o2o优惠券的使用预测思路完整版]]https://blog.csdn.net/weixin_42001089/article/details/85013073, 并下载了源代码,调试代码,部分代码如下:
-
【使用的库】
import pandas as pd import numpy as np import pickle import xgboost as xgb from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import log_loss, roc_auc_score, auc, roc_curve from sklearn.model_selection import train_test_split -
【使用的模型】
params = {'booster': 'gbtree', 'objective': 'rank:pairwise', 'eval_metric': 'auc', 'gamma': 0.1, 'min_child_weight': 1.1, 'max_depth': 5, 'lambda': 10, 'subsample': 0.7, 'colsample_bytree': 0.7, 'colsample_bylevel': 0.7, 'eta': 0.01, 'tree_method': 'exact', 'seed': 0, 'nthread': 12 } watchlist = [(dataTrain, 'train')] model = xgb.train(params, dataTrain, num_boost_round=3500, evals=watchlist) model.save_model('train_dir_3/xgbmodel') model = xgb.Booster(params) model.load_model('train_dir_3/xgbmodel') # predict test set dataset3_preds1 = dataset3_preds.copy() dataset3_preds1['label'] = model.predict(dataTest) -
【使用的feature】
def DataProcess(dataset, feature, TrainFlag): other_feature = GetOtherFeature(dataset) merchant = GetMerchantRelatedFeature(feature) user = GetUserRelatedFeature(feature) user_merchant = GetUserAndMerchantRelatedFeature(feature) coupon = GetCouponRelatedFeature(dataset, feature) dataset = pd.merge(coupon, merchant, on='merchant_id', how='left') dataset = pd.merge(dataset, user, on='user_id', how='left') dataset = pd.merge(dataset, user_merchant, on=['user_id', 'merchant_id'], how='left') dataset = pd.merge(dataset, other_feature, on=['user_id', 'coupon_id', 'date_received'], how='left') dataset.drop_duplicates(inplace=True) dataset.user_merchant_buy_total = dataset.user_merchant_buy_total.replace(np.nan, 0) dataset.user_merchant_any = dataset.user_merchant_any.replace(np.nan, 0) dataset.user_merchant_received = dataset.user_merchant_received.replace(np.nan, 0) dataset['is_weekend'] = dataset.day_of_week.apply(lambda x: 1 if x in (6, 7) else 0) weekday_dummies = pd.get_dummies(dataset.day_of_week) weekday_dummies.columns = ['weekday' + str(i + 1) for i in range(weekday_dummies.shape[1])] dataset = pd.concat([dataset, weekday_dummies], axis=1) if TrainFlag: dataset['date'] = dataset['date'].fillna('null'); dataset['label'] = dataset.date.astype('str') + ':' + dataset.date_received.astype('str') dataset.label = dataset.label.apply(get_label) dataset.drop(['merchant_id', 'day_of_week', 'date', 'date_received', 'coupon_count'], axis=1, inplace=True) else: dataset.drop(['merchant_id', 'day_of_week', 'coupon_count'], axis=1, inplace=True) dataset = dataset.replace('null', np.nan) return dataset -
【提交后结果为0.78,如下图所示:】
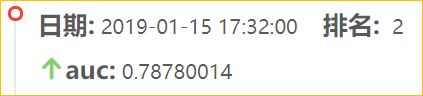
-
【结果分析:】
分数比第一次高的原因是进行了较充分的特征工程处理,但是因为只使用了offline的数据,而未使用online的数据,所以导致最后的分数仅0.78.
3. auc0.80
-
【使用的库】
import datetime import os import time from concurrent.futures import ProcessPoolExecutor from math import ceil from catboost import CatBoostClassifier from lightgbm import LGBMClassifier from sklearn.ensemble import GradientBoostingClassifier, RandomForestClassifier, ExtraTreesClassifier from sklearn.externals import joblib from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split, GridSearchCV, StratifiedKFold from sklearn.metrics import accuracy_score, classification_report, roc_auc_score import matplotlib.pyplot as plt import pandas as pd import numpy as np from xgboost.sklearn import XGBClassifier import xgboost as xgb from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import log_loss, roc_auc_score, auc, roc_curve -
【使用的模型】
# 使用优化后的num_boost_round参数训练模型 watchlist = [(train_dmatrix, 'train')] model = xgb.train(params, train_dmatrix, num_boost_round=3500, evals=watchlist) model.save_model('train_dir_2/xgbmodel') params['predictor'] = 'cpu_predictor' model = xgb.Booster(params) model.load_model('train_dir_2/xgbmodel') # predict test set dataset3_predict = predict_dataset.copy() dataset3_predict['label'] = model.predict(predict_dmatrix) -
【使用的feature】
def get_features(dataset, feature_off, feature_on): dataset = get_offline_features(dataset, feature_off) return get_online_features(feature_on, dataset) -
【num_boost_round=3500,CPU,提交后结果为0.78533,如下图所示:】

使用的模型参数为:params = {'booster': 'gbtree', 'objective': 'rank:pairwise', 'eval_metric': 'auc', 'gamma': 0.1, 'min_child_weight': 1.1, 'max_depth': 5, 'lambda': 10, 'subsample': 0.7, 'colsample_bytree': 0.7, 'colsample_bylevel': 0.7, 'eta': 0.01, 'tree_method': 'exact', 'seed': 0, 'nthread': 12 } -
【num_boost_round=3800,CPU,提交后结果为0.79182,如下图所示:】
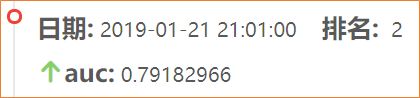
使用的模型参数为:params = {'booster': 'gbtree', 'objective': 'rank:pairwise', 'eval_metric': 'auc', 'gamma': 0.1, 'min_child_weight': 1.1, 'max_depth': 5, 'lambda': 10, 'subsample': 0.7, 'colsample_bytree': 0.7, 'colsample_bylevel': 0.7, 'eta': 0.01, 'tree_method': 'exact', 'seed': 0, 'nthread': 12 } -
【num_boost_round=4500,CPU,提交后结果为0.79509,如下图所示:】

使用的模型参数为:params = {'booster': 'gbtree', 'objective': 'rank:pairwise', 'eval_metric': 'auc', 'gamma': 0.1, 'min_child_weight': 1.1, 'max_depth': 5, 'lambda': 10, 'subsample': 0.7, 'colsample_bytree': 0.7, 'colsample_bylevel': 0.7, 'eta': 0.01, 'tree_method': 'exact', 'seed': 0, 'nthread': 12 } -
【num_boost_round=6200,GPU,提交后结果为0.80039,如下图所示:】

使用的模型参数为:params = {'booster': 'gbtree', 'objective': 'binary:logistic', 'eval_metric': 'auc', 'gamma': 0.1, 'min_child_weight': 1.1, 'max_depth': 5, 'lambda': 10, 'subsample': 0.7, 'colsample_bytree': 0.7, 'colsample_bylevel': 0.7, 'eta': 0.01, 'tree_method': 'gpu_hist', 'n_gpus': '-1', 'seed': 0, 'nthread': cpu_jobs, 'predictor': 'gpu_predictor' } -
【num_boost_round=6558(xgbcv优化的参数),GPU,提交后结果为0.80042,如下图所示:】

使用的模型参数为:params = {'booster': 'gbtree', 'objective': 'binary:logistic', 'eval_metric': 'auc', 'gamma': 0.1, 'min_child_weight': 1.1, 'max_depth': 5, 'lambda': 10, 'subsample': 0.7, 'colsample_bytree': 0.7, 'colsample_bylevel': 0.7, 'eta': 0.01, 'tree_method': 'gpu_hist', 'n_gpus': '-1', 'seed': 0, 'nthread': cpu_jobs, 'predictor': 'gpu_predictor' } -
【结果分析:】
在同时使用了offline的feature和online的feature后,auc从0.7878变为0.7853,在提高了迭代次数后,变为0.79;后续更改为GPU模式,同时将更改其它参数为` ‘objective’: ‘binary:logistic’, ‘tree_method’: ‘gpu_hist’,后,通过优化迭代次数,逐步提升到了0.80042.
(GPU运行遇到问题,请参考博客:https://blog.csdn.net/myourdream2/article/details/86603300 )
收获与感悟
在不断的实践中,发现特征工程真的很重要,也正印证了“特征工程决定了上限,模型算法及优化只是逼近这个上限”。同时,也熟悉了xgboost的相关参数意义,及迭代次数参数优化方法;此外,通过搭建GPU xgboost运行环境,真切的感受到了GPU运行的飞起的感觉。后续继续研究看是否可以通过优化其它参数、或者模型融合,来进一步提升分数。