神经网络和深度学习简史(三)
一、可以做决定的神经网络
在了解了神经网络在无监督学习方面的应用以后,我们接下来将见到机器学习的第三部分:增强学习。尽管这个概念需要一个明确的数学表示进行描述,但我们可以先从简单理解一下:增强学习可以帮助我们作出决定。有一些理想的代理(例如一个小程序),这些代理可以基于其当前的状态来决定当下的动作,并且可以在每个动作之后得到相应的回馈,而决策的依据就是使长期优势最大化。因此监督学习告诉算法他应该学习如何输出,强化学习并不会直接告诉算法如何选择正确的决定,相反它会给作出良好选择的算法提供一个“奖励”。最初它是一个非常抽象的决策模型,该模型有一定数量的状态,以及每个状态对应的奖励行为集。这有助于写出寻找每个动作的最优选择,但却很难应用于实际问题,因为实际问题的状态都是连续的或者实际问题的“奖励”很难定义。
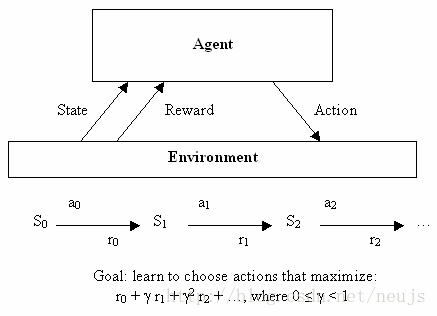
图3.1 强化学习
这时候,我们需要引入神经网络的概念了。机器学习,特别是神经网络,擅长通过学习实例的方式处理混乱的连续数据,或一些难以定义的函数。虽然分类只是神经网络的基本功能,但它们也可以用来解决很多其他类型的问题,例如Bernard Widrow 和Ted Hoff 的Adaline的后代改进品可以被用来作为电路中的自适应滤波器。因此在反馈神经网络的研究重新兴起之后,人们很快开始设计利用神经网络来实现强化学习的算法。其中早期的例子是解决一个简单但又经典的问题:在移动的平台上保持一根棍子的平衡,这也是控制类专业的经典问题,倒立摆问题。
图3.2 二阶倒立摆,二阶倒立摆
与自适应滤波一样,这项研究与电气工程领域(EE)密切相关,其中控制领域是神经网络几年前的主要应用领域。虽然该领域已经设计出很多通过直接分析处理的方式解决问题的方案,但设计出通过学习手段来处理更复杂的问题也是一种很好的解决方案,例如1990年的一篇被引用超过7000次的论文“Identification and control of dynamical systems using neural networks”就是一个很好的例子。另外一个应用到神经网络的非机器学习领域是机器人学领域,其中一个比较著名的例子当属1989年卡耐基梅隆大学导航实验室的 “Alvinn: An autonomous land vehicle in a neural network”:
https://youtu.be/5-acCtyKf7E(视频来自youtube)
如同在论文中描述的一样,该系统中的神经网络把人类驾驶记录的传感器和专项数据作为训练集,通过监督学习来控制车辆。还有使用增强学习来专门教学的机器人,例如1993年的一篇论文“Reinforcement learning for robots using neural networks”。该论文表明在适当的时间内可以训练机器人沿着墙体移动或通过大门,这就显得很有意义,因为之前的倒立摆并不能解决什么实际问题。
尽管这些应用在其他领域的神经网络看起来很酷炫,但是大多数对神经网络的研究还是发生在人工智能(AI)和机器学习(Machine Learning)领域。在这里,强化学习历史上最重要的一个成果诞生了:一个神经网络被训练成了世界级的西洋双陆棋选手。这个被称为TD-Gammon的神经网络,使用强化学习的算法进行训练,这是第一次在相对比较复杂的任务上强化学习战胜人类的案例。而且该案例表明,脱离了增强学习的神经网络并不能得到同样好的效果。

图3.3 学会了玩西洋双陆棋的神经网络
历史再一次重现,AI研究领域,科研又一次实现了突破。在调查了使用TD-Gammon算法来研究下一步可预测的策略之后,Sebastian Thrun 在1995发表的论文“Learning To Play the Game of Chess”,表明了该算法的结果并不理想。虽然该算法在游戏中的表现胜过一般的新手,但却远逊于很久之前的一个标准计算机程序(GNU-Chess)。当然对与AI的另外一个挑战Go而言,效果也是不理想。TD-Gammon算法只是在某种程度上学会了欺骗,它学会了如何很好估测现在的状态以选择下一步的动作,却没有“搜索”未来的所有的可能性。这无论是在国际象棋或者是Go游戏中都是不可能的。游戏被认为是一个AI挑战,因为在每一步棋之前都有那么多种组合移动。此外即使算法更加智能,对于硬件计算时间来讲,也是一个不可完成的任务。计算一个大型神经网络函数的时间要比评价一个优化线性评估函数(optimized linear evaluation function)高两个数量级。"计算机硬件的局限性限制了神经网络的发展"
二、可以循环的神经网络
尽管无监督学习和强化学习简洁方便,但我还是最喜欢监督学习。当然,学习数据的概率模型是一件很酷的事情,但是通过反向传递的方式来解决各种具体问题更加令我觉得兴奋。我们已经知道了Yann Lecun如何实现对手写文本的识别(这种技术已经被国家采用在检查阅读的领域,但是未来...),当然还有另外一个非常重要的任务:理解人类的语言。
同写作一样,理解人类语言是相当困难的,因为一个简单的单词可能会有无穷多的含义的变化。但是这里还有一个更大的挑战:长序列输入。在图像识别领域,我们可以简单的从图像中剪裁出一个个的单一字母,并且有神经网络会告诉你每一个字母是什么,这是一种简单的由输入到输出的风格。但是对于音频来讲就没有这么简单了,将语言全部分解成为字符是不切实际的,甚至在一段话中找到单个词也不是那么简单。而且在人类语言交流过程中,结合上下文也是一个重要的考虑因素。因此这种在处理图像领域中的由输入到输出的方式非常有效,但这种方式并不适合诸如音频或文本之类的长信息流。神经网络并没有可以实现输入间相互影响的“记忆”能力,而这正是人类如何处理音频或文本的方式:输入一串的数字或声音,而不是一次性全部输入进来。所以语义识别领域的研究人员试图修改神经网络,以神经网络可以按照流的形式处理输入,而不是类似图像中的按批处理的方式。
Alexander Waibel等人(包括Hinton)在1989年的论文“Phoneme recognition using time-delay neural networks”提出了一种方法,时间延迟神经网络(TDNN)。这种时间延迟神经网络结构上类似正常的神经网络,但每个神经元近能处理输入的一个子集,并且对于不同延迟的输入数据有不同的权重。也就是说,对于音频输入序列而言,一个可以移动的“音频窗口”作为神经网络的输入。当窗口移动时,这些具有不同权重的神经元就会处理相应的音频。以下是一个简单的说明:
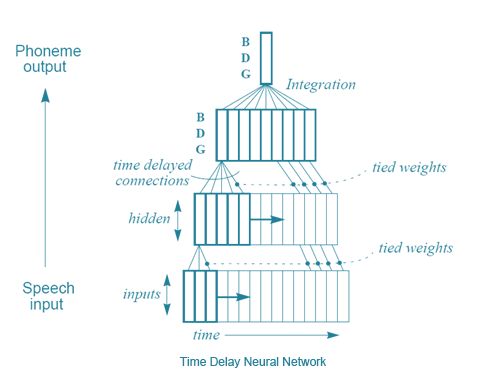
图3.4 时间延迟神经网络
从某种意义上来讲,这与CNNs的算法十分相似,每个单元每一次仅对输入的一个子集进行相同的操作,而不是一次查看整个输入。而这个算法与CNN的一个主要区别就是在CNN中并没有时间的概念,而TDNN实际上是顺序的输入输出数据的,这是因为每个神经元的“窗口”在计算结果的时候都会在整个输入图像上移动。有趣的是,根据Hinton所说,正是TDNN激发了LeCun开发卷积神经网络。然而正当CNNs成为图像领域必不可少的工具之时,TDNNs在语音识别领域依然被另外一种算法超越了,那就是——递归神经网络(RNNs)。迄今为止,我们所有讨论过的神经网络都是前馈网络,这意味着当前层神经元的输出仅仅可以作为下一层神经元的输入。但是没有什么可以阻止科学家们勇敢的把最后一层神经元的输出作为第一层的输入连接起来,甚至是把神经元的输出作为自身的输入。通过使网络的输出回归到网络中,关于网络无法存储过去的输入的问题就被轻松的解决了。
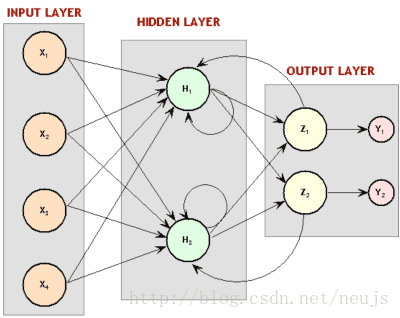
图3.5 RNN图示,是否让你想起了玻尔兹曼机?
事情没有想象的这么简单,如果反向传递函数从输出层反响“传递”误差,那么当输出层与第一层连接起来的时候,怎么办?误差再一次从第一层传递到输出层,循环反复,误差将永远存在于网络之中。解决方法是按时间顺序分组进行反向传递训练,其基本思路是展开整个神经网络,把每一次循环的结果作为另一个神经网络的输入,这样的循环都会有一个次数上的限制。
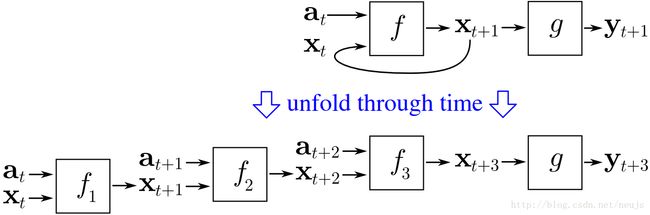
图3.6 按时间顺序的反响传递神经网络的设想
这样的一个简单的想法使得训练循环神经网络变为可能。确实有很多人讨论RNN在语音识别当中的应用,但是预言,这种方法的效果并不好。想要理解具体的原因,我们来看看现代深度学习领域的又一位大牛:Yoshua Bengio。Yoshua Bengio在1986年开始利用神经网络进行语音识别方面的工作,他著有很多利用ANN和RNN进行语音识别的论文,最终他选择了在AT&T公司的贝尔实验室从事自己的研究,这一选择与研究CNN的Yann LeCun如出一辙。他们两个人在1995年一起发表了一篇题为“Convolutional Networks for Images, Speech, and Time-Series”的论文,这是它们重多合作当中的第一次。在此之前Yoshua Bengio在1993年曾发表论文“A Connectionist Approach to Speech Recognition”,在此文当中,他总结了训练RNN的失败原因:
“大多数情况下,循环神经网络的性能是要优于静态神经网络的,但是它们也更难以训练。而我们的实验却往往想一蹴而就的找到一个最优解决方案,例如在上面引用的实验里面我们发现简单的音位的持续时间根本不能被循环神经网络所捕获......尽管这个实验的结果并不理想,但是仔细思考这个问题可以帮助我们摆脱当前思维的局限性,摆脱寻找一个可以长期使用的方法,转而对有限状态机(finite state machines)、语法或一些其他语言相关的地方进行研究。在这种问题下,基于梯度的方法明显无法胜任,因此我们需要寻找一种其他的最优化方法,使得在目标函数不平滑的时候,仍然可以输出一个可以接受的结果。”
三、又一个冬天
现在,在我们面前的是一个巨大的问题,而这个问题却被看作是一个巨大的进步,那就是:反向传递。由于在反向传递在常规的神经网络上并不能很好的工作,因此卷机神经网络就显得尤为重要。然而深度学习的关键之处在于:层数太多。近期的神经网络通常都有20或更多的层数,然而在80年代的后期,人们就已然知道了利用反向传递训练深度神经网络效果并不理想,其表现甚至不如层数更少的神经网络。原因在于,反向传递依赖于在输出层找到误差并在前面的层中分裂它。在多层的神经网络里面,这种基于微积分分裂的方式无论在数值过大还是过小的情况下,效果都不理想。Jurgen Schmidhuber,深度学习的又一位大牛称之为“要么消失,要么爆炸的梯度问题。”对此,他做出了更正式的解释:
一篇毕业论文(Hochreiter, 1991)揭示了DL研究史的里程碑。在第二部分5.6节中提到,实验表明传统的前馈深度网络或循环网络都很难通过反向传递进行训练(5.5节)。Hochreiter,的工作总结了其中的一个重要的原因:典型的深度神经网络明显受到梯度消失或爆炸问题的影响。使用标准的激励函数(第一部分),累积反向传递的误差信号都会快速收缩超出边界。事实上在分布式的深度(第三部分),或者是多层数的网络中,他们都会成指数衰减,或者数据爆炸。
随着时间进行的反向传播本质上等同于又大量层数的神经网络,因此RNN很难利用反向传递的方式进行训练。由Schmidhuber、Sepp Hochreiter和Yoshua Bengio联合发表的论文表明了由于反向传播的的限制而不能进行长时间的训练的学习。并且提供了一个可能的解决方案:Schmidhuber和Hochreiter在1997年提出的理论,长期短记忆(Long Short Term Memory),基本上解决了如何训练循环神经网络的问题,这个方案(LSTM)就如同在前馈神经网络之中引入卷机神经网络(CNN)。简单来说,LSTM对常规神经网络做了一点小改变,就像CNN一样。
“LSTM的基本理念十分简单。一些节点被称为恒定误差转轮(CECs),这些CECs每一个都具有一个激励函数f,并且与具有固定权重的自身相连接。由于f的连续导数为1,因此通过CEC反向传递的误差并不会消失或爆炸(5.9部分),而只会保持原样(除非这些误差逃离CEC,进入神经网络的其他单元之中)。CEC连接到一些非线性自适应单元(其中有的有乘法的激励函数),而这些单元需要学习一些非线性的动作。这些单元的权重的改变通常受到CEC中流过的误差信号中获益。正是由于CEC的存在,才使得LSTM神经网络可以发现几千个离散周期之前发生的动作的重要性(某种意义上讲,神经网络有了记忆能力),而之前的RNN由于最小的延迟时间仅有10个离散周期,因此注定是不会成功的。”
但是这对于解决神经网络目前面对的感知困难只是杯水车薪。神经网络仍然被认为是一种麻烦的工具——计算机不够快,算法不够聪明,人们不开心。因此,90年代中期,又一个神经网络的冬天降临了——社会再次对神经网络失去了信心。一种被称为支持向量机(SVM)的算法出现之后,人们普遍认为SVM可以解决神经网络解决不了的问题,SVM可以被认为是一种等效两层神经网络的数学优化方法。LeCun等人1995年提出的“Comparison of Learning Algorithms For Handwritten Digit Recognition” 算法,除非更加精确的设计神经网络,不然效果完全不敌支持向量机(SVM):
“支持向量机(SVM)优势之处在于其分类精度很高。它并不需要关于任何一个问题的先验知识,这是与其他高性能分类起的最大不同之处。如果图像的像素用固定的映射进行序列改变,则该分类器的效果会很好。事实上它比神经网络更慢,需要消耗更多的内存,但是由于是新技术的原因,人们才会对算法的改进有所期待。”
诸如随机森林的一些其他算法,也被证明是十分有效的,其背后仍有十分深刻的数学理论。因此尽管CNN一直具有最好的表现,但随着机器学习社区对神经网络的热情的消退,神经网络再一次抛弃了神经网络。寒冬再一次降临了,在最后一部分中,我们将看到一小群人如何坚持这种研究,并最终使得神经网络达到今天的高度。