Java写爬虫
-
- 抓包软件Fiddler
- 进行内容抓取
- 1 HttpClient
- 2 jsoup
- 3 WebCollector
- 4 运用HttpClient进行网页内容爬取
- 41 安装
- 42 使用
- 相关问题与注意事项
- 1 https问题
- 2 翻页问题
- 3 关于ajax的问题
web网站,作为最大的数据源,每时每刻都在产生大量的非结构化数据。对海量web数据的成功采集和分析,可以助力解决具体的业务问题,同时也是进行大数据分析与挖掘所应具有的关键能力之一。
最近,因为项目需要,接触了爬虫技术,下面将对爬虫技术的相关知识进行提炼。
1 抓包软件Fiddler
编写爬虫程序的核心是对数据包的抓取和分析,不管使用java还是python进行爬虫程序的实现,首先需要掌握如何对数据包进行抓取和分析。用于进行数据包分析的软件有很多,浏览器自身集成的调试器就支持数据包的查看和分析功能。我在项目运用fiddler进行数据包的分析与解析工作,下面进行重点介绍。
fiddler是一款http协议调试代理工具,可以对浏览器和服务器之间产生的交互详情进行记录,软件小、使用方便,上手容易,非常适合协助爬虫程序设计。
官网可以直接下载安装,需要破解(网上 教程很多),也可直接使用破解版本。
我使用的是fiddler 4,打开软件如下图所示:
软件分为两栏,左边为请求的资源url地址列表,右边主要显示详细的请求和响应相关信息。
软件两个主要功能的快捷键:
F12控制(开始/停止)对浏览器监听的监听开关Crtl+x选中左侧url列表,进行列表删除,方便对目标url页面请求与响应信息的查看。
也可通过软件功能栏和单击鼠标右键使用该功能。打开对浏览器的监听开关后,软件左下角会出现capturing状态,浏览器请求的资源url列表都会显示在左侧栏中,点击具体url,可以查看发送的请求和响应信息。
以登录csdn网站为例,如下图,选中进行传参的登录url,右边栏可以看到request和response的信息。
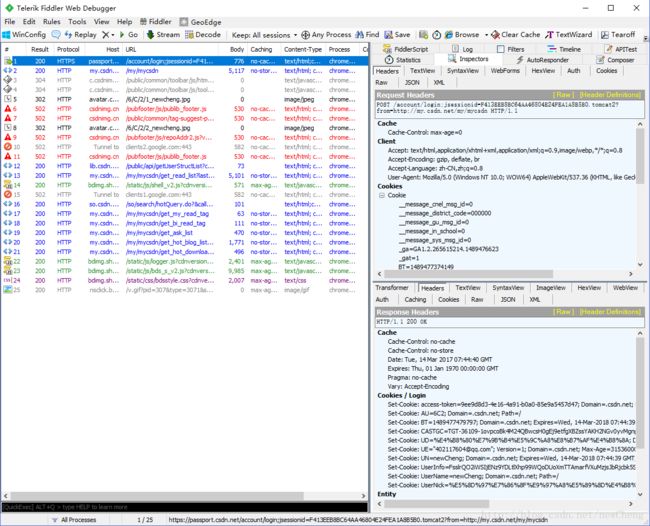
可以看出,登录请求是以post形式发出,可在右边栏相应的WebForms,Headers和TextView标签页中查看详细信息。
通过fiddler对数据包进行分析,可以查看到请求和响应的详细信息,不管以后抓取的是什么网页内容(图片、表格或者处理分页),会抓包,所有问题都会迎刃而解,剩下的无非是改改参数的问题了。
2 进行内容抓取
运用java进行爬虫程序实现。
本文关注过三个java爬虫相关组件:HttpClient、jsoup和WebCollector,首先依依介绍。
2.1 HttpClient
HttpClient简单的说定义了面向Http协议的抽象数据对象。可以通过HttpClient相关对象,模拟浏览器的请求和响应行为。HttpClient支持对request和response的对象抽象,定义了get,post,代理,重定向等一系列行为。当前HttpClient已经发展到4.x版本,api发生巨大变化需要注意。
2.2 jsoup
jsoup是一款开源的HTML页面解析jar包,通过Jsoup可以非常容易的,以类似DOM的方式对HTML页面进行解析,具体操作见链接。另外其也对请求/响应模型进行了封装,可以用来代替httpclient进行与服务器的交互。
2.3 WebCollector
WebCollector是国人研发的一款开源java爬虫项目,其本身是基于HttpClient和jsoup实现的,但是经过拓展,该项目以多线程的方式提升效率;通过正则表达式自动对页面url进行检索;通过Berkely DB对任务信息进行记录。只需几行代码就可以实现整个抓取的过程。非常适合初学者。链接中有详细的教程,在此不敖述。
2.4 运用HttpClient进行网页内容爬取
本文主要介绍基于HttpClient的实现形式。具体分为三个过程:实例化HttpClient对象,发出请求和接收响应。只要学会了抓包和分析包,在复杂的问题都可以按照这个过程解决。
2.4.1 安装
导入httpclient-4.x.x.jar,4.x版本与之前版本在api上有一些变动
2.4.2 使用
httpclient相当于定义了一个发出请求的对象(浏览器),通过该对象进行请求的发送和响应的接收。
新建httpclient对象 CloseableHttpClient。
CloseableHttpClient对象可以理解为是浏览器的一个对象实例,所以对于某个爬虫任务,需要进行多次请求和响应,应只需实例化一个CloseableHttpClient对象,进行相关操作。通过设置UserAgent模拟具体的浏览器型号。HttpClientBuilder httpClientBuilder=HttpClientBuilder.create(); CloseableHttpClient closeableHttpClient=httpClientBuilder //.setProxy(new HttpHost("localhost", 8888)) //设置该参数可以使得在fiddler中查看到该访问 .setUserAgent("Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1") .build();通过HttpGet、HttpPost方式发送请求。
在fiddler中通过对包的分析,确定浏览器是以get或post的方式发出请求,依此使用不同API。通过对请求Header信息的分析,可以发现上文截图中csdn的登录是通过post方式发出的,则应使用相关HttpPost方式。两种方式的主要实现如下:
(1) HttpGet方式。
a. 实例化HttpGet httpGet=new HttpGet(“目标url”);b.HttpGet方式进行请求传参——直接构造参数字符串
Listparams = Lists.newArrayList(); params.add(new BasicNameValuePair("paramName1", "value1")); params.add(new BasicNameValuePair("paramName2", "value2")); String str = EntityUtils.toString(new UrlEncodedFormEntity(params, Consts.UTF_8)); HttpGet httpGet = new HttpGet(url+"?"+str); (2) HttpPost方式。
a.实例化HttpPost httpPost=new HttpPost(“目标url”);b.HttpPost方式进行请求传参——httpclient以entity对象的方式对参数进行封装。
List<NameValuePair> params = new ArrayList<NameValuePair>(); params.add(new BasicNameValuePair("paramName1", "value1")); params.add(new BasicNameValuePair("paramName2", "value2")); UrlEncodedFormEntity pentity = new UrlEncodedFormEntity(params, "utf-8"); httpPost.setEntity(pentity); //HttpPost方式执行——通过httpclient对象。
HttpResponse httpResponse=closeableHttpClient.execute(httpPost); //执行httpPost请求 HttpResponse httpResponse=closeableHttpClient.execute(httpGet); //执行httpGet请求获得响应,通过HttpEntity对象的形式进行封装。
HttpEntity entity=httpResponse.getEntity(); String responseContent=EntityUtils.toString(entity, "gb2312"); //获得响应内容(返回的如果是html页面,则对该字符串运用jsoup解析,如果是json或者xml则采用对应的方式解析即可) System.out.println("ContentLength:"+entity.getContentLength()); //获得内容长度 System.out.println("ContentEncoding:"+entity.getContentEncoding()); //获得内容编码方式 httpResponse.getStatusLine(); //获取响应状态码 Header[] headerArr=httpResponse.getAllHeaders(); //获取响应头文件,以数组方式返回
3 相关问题与注意事项
3.1 https问题
关于使用HttpClient抓取HTTPS页面报异常:
javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
需要通过设置SSLContext的上下文进行CloseableHttpClient对象的实例化,具体代码如下:
需要导入的包。
import java.security.KeyManagementException; import java.security.KeyStoreException; import java.security.NoSuchAlgorithmException; import java.security.cert.CertificateException; import java.security.cert.X509Certificate; import javax.net.ssl.SSLContext; import org.apache.http.conn.ssl.SSLConnectionSocketFactory; import org.apache.http.conn.ssl.SSLContextBuilder; import org.apache.http.conn.ssl.TrustStrategy;定义一个静态方法用于实例化CloseableHttpClient对象
public static CloseableHttpClient createSSLClientDefault() { try { SSLContext sslContext = new SSLContextBuilder().loadTrustMaterial(null, new TrustStrategy() { // 信任所有 public boolean isTrusted(X509Certificate[] chain, String authType) throws CertificateException { return true; } }).build(); SSLConnectionSocketFactory sslsf = new SSLConnectionSocketFactory(sslContext); return HttpClients.custom().setSSLSocketFactory(sslsf).setProxy(new HttpHost("localhost",8888)).build(); } catch (KeyManagementException e) { e.printStackTrace(); } catch (NoSuchAlgorithmException e) { e.printStackTrace(); } catch (KeyStoreException e) { e.printStackTrace(); } return HttpClients.createDefault(); }调用方法进行实例化。
CloseableHttpClient httpClient=类名.createSSLClientDefault()
另外需要注意,fiddler在监控https页面的请求响应时需要先在Tools -> Telerik Fiddler Options -> 选中”Decrypt HTTPS traffic”——对解读HTTPS通信进行许可,否则左边栏将无法显示具体HTTPS url和相关信息。
3.2 翻页问题
在处理翻页时需要注意两点问题:
1. 确定是get还是post进行翻页请求,使用对应对象。
2. 请求参数要传完整,有些页面使用了开源翻页控件,例如:ASP.NET Pager控件,会在hidden中隐藏分页的token验证信息,注意请求参数不要漏传。
3.3 关于ajax的问题
request Header中会出现:X-Requested-With:XMLHttpRequest。说明请求是通过ajax方式发出的,同时是一种非标准化请求报头。对于这种情况,需要在在HttpPost或者HttpGet中设置setHeader(“X-Requested-With”, “XMLHttpRequest”);进行特别指定,否则可能会包403或者500错误。