转自:阿里技术,有删节。
【嵌牛导读】:本文介绍支付宝App中的深度学习引擎——xNN。xNN通过模型和计算框架两个方面的优化,解决了深度学习在移动端落地的一系列问题。xNN的模型压缩工具 (xqueeze) 在业务模型上实现了近50倍的压缩比, 使得在包预算极为有限的移动App中大规模部署深度学习算法成为可能。xNN的计算性能经过算法和指令两个层面的深度优化,极大地降低了移动端DL的机型门槛。
【嵌牛鼻子】:深度学习 xNN xqueeze工具链
【嵌牛提问】:xNN的应用?
【嵌牛正文】:

深度学习——云端还是移动端?
近来,深度学习(DL)在图像识别、语音识别、自然语言处理等诸多领域都取得了突破性进展。DL通常给人以计算复杂、模型庞大的印象——从Siri语音助手到各种聊天机器人、再到支付宝“扫五福”,移动端收集数据+云端加工处理似乎成为一种常识。然而对很多应用来说,这种模式其实只是无奈之选。

去年春节的“扫五福”活动中,为了识别手写“福”字,支付宝多媒体团队调动了近千台服务器用于部署图像识别模型。可是如此规模的集群也没能抵挡住全国人民集五福的万丈热情。为了防止云端计算能力超载,活动中后期不得不启动了降级预案——用计算量小但精度也较低的传统视觉算法替代了DL模型。降级虽然不妨碍大伙继续热火朝天地收集福卡,但对用户体验无疑是有一定影响的,比如一些不可言说的汉字也被误判成了“福”字。

另一方面,DL在云端则意味着数据必须上传。即使不考虑计算压力,从网络延时、流量、隐私保护等角度也给用户体验带来种种限制。因此,对相当多的应用来说,DL模型前移到移动端部署可以看作是一种刚需。
两大挑战
最近,随着手机处理器性能的提升和模型轻量化技术的发展,移动端DL正在变得越来越可行,并得到了广泛的关注。苹果和谷歌已经分别宣布了各自操作系统上的DL框架Core ML和Tensorflow Lite,这无疑将极大地促进移动端DL的发展。但是,尤其对于支付宝这样的国民App来说,仍然存在一些严峻的挑战是无法通过直接套用厂商方案来解决的。
1.机型跨度大:支付宝App拥有数亿受众群体,在其中落地的业务必须对尽可能多的用户、尽可能多的机型提供优质的体验。对支付宝来说,参考Core ML只将功能开放给少数高端机型的做法是不合适的。因而无论在运行速度和内存占用等性能指标、还是在兼容性上,支付宝的移动端DL都必须做到极致,才能最大幅度地降低使用门槛。
2.包尺寸要求严:支付宝App集成了众多的业务功能,安装包资源非常紧张,一个新模型要集成进安装包往往意味着需要下线其他的功能。而即便通过动态下发的形式进行部署,DL模型的大小也会强烈影响用户的体验。随着移动端智能化程度的不断提升,直接在端上运行的DL应用必然会越来越多,这以当前单个模型大小就动辄数十、数百M的尺寸来看几乎是不可想象的。同时,移动端DL引擎本身的SDK也需要尽可能地瘦身。
五大目标
支付宝xNN是针对国民App环境定制开发的移动端DL解决方案,项目制定了如下技术目标。
1.轻模型:通过高效的模型压缩算法,在保证算法精度的前提下大幅减小模型尺寸。
2.小引擎:移动端SDK的深度裁减。
3.快速:结合指令层和算法层的优化,综合提升DL计算的效率。
4.通用:为保证最大的机型覆盖率,以最为通用的CPU而非性能更强劲的GPU作为重点优化平台。不仅支持经典的CNN、DNN网络,也支持RNN、LSTM等网络形态。
5.易用:工具链对业务保持高度友好——使得算法工程师们能更好地专注于算法本身,在不需要成为模型压缩专家和移动端开发专家的情况下都能快速完成云端模型到移动端模型的转换和部署。
主要特性一览
xNN为DL模型提供了从压缩到部署、再到运行时的统计监控这一全生命周期的解决方案。xNN环境由开发后台和部署前台两部分组成。
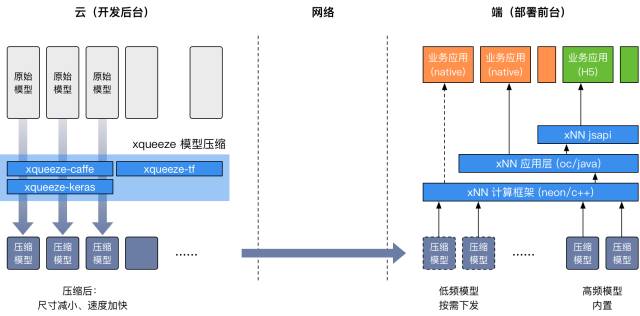
开发后台以xqueeze工具链为核心,支持多种训练框架。业务可以使用xqueeze压缩、优化自己的DL模型,得到尺寸大幅减小、运行速度显著加快的模型版本。压缩后的模型根据使用场景,可以通过App安装包内置或按需下发的形式部署到移动端。
在部署前台,xNN的计算框架提供高效的前向预测能力。xNN的应用层在计算的基础上还提供了模型下发、数据统计、错误上报等一站式能力。xNN还通过一个jsapi提供了直接对接H5应用的能力——通过DL模型的动态下发和H5,能够实现完全的动态化,从而在客户端不发版的情况下完成算法+逻辑的同时更新。
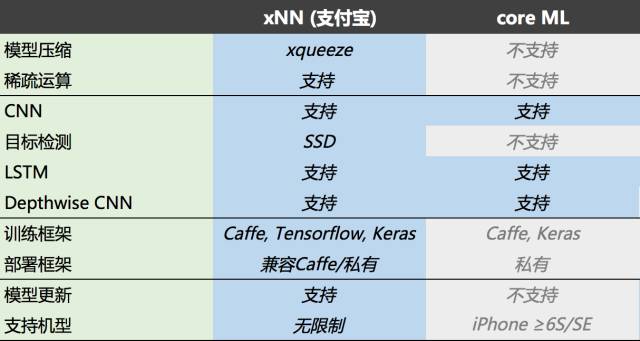
上图给出了xNN的主要特性。在xqueeze模型压缩的基础上,xNN还支持通过快速处理稀疏网络来提高性能。xNN支持了丰富的网络结构类型,包括经典CNN/DNN、SSD目标检测和LSTM。xNN的部署框架原生兼容Caffe,业务可以在不做转换的情况下直接在移动端运行已有的Caffe模型,以快速评估效果。而经过压缩的私有格式模型更小、更快。在Tensorflow和Keras平台上训练的模型也能够在原有的环境上进行压缩,然后转换为xNN支持的格式部署到移动端。不同于core ML,xNN理论上支持安卓和iOS上的所有机型。
xqueeze模型压缩
xNN-xqueeze的模型压缩流程如下图之(a)所示,包括神经元剪枝 (neuron pruning)、突触剪枝 (synapse pruning)、量化 (quantization)、网络结构变换 (network transform)、自适应Huffman编码 (adaptive Huffman)、共5个步骤。其中前三步理论上是有损的,而使用xqueeze对网络权重和压缩超参进行finetune,能够将精度的下降保持在可控甚至可忽略的程度。后两步则完全不影响网络的输出精度。整个流程不仅会减小模型的尺寸,还通过网络的稀疏化和结构优化,显著提高前向预测的速度。
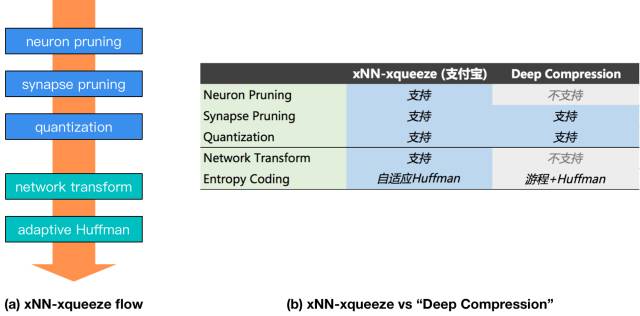
在领域的经典方案DeepCompression的基础上,xqueeze 进一步扩充了neuronpruning和network transform的能力。其中,neuron pruning能够逐次裁剪掉“不重要”的神经元和与之对应的权重参数。通过neuron pruning和synapse pruning的结合,在模型精度和压缩比之间达成更好的平衡。xqueeze还具有network transform——在网络的宏观层面进行优化的能力,networktransform脚本扫描整个网络,诊断出可优化的点,包括在有条件的情况下自动地进行层 (layer) 的组合与等效替换。此外,xqueeze通过自适应地使用Huffman编码,有效提升不同稀疏程度的模型之压缩比。
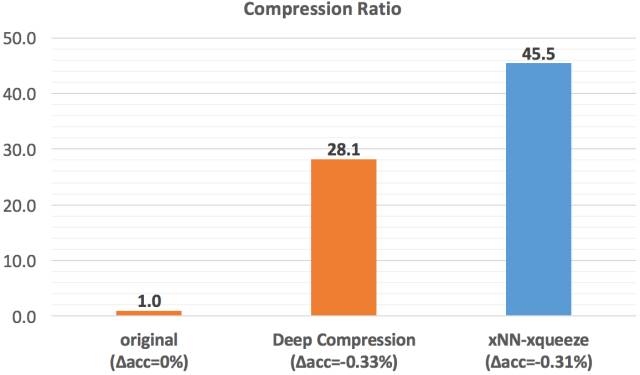
如下图所示,对于业务分类模型,使用xqueeze工具链能够实现45.5倍的压缩,在同等程度的精度损失下,压缩率超越经典方案达60%。
xNN计算性能优化
xNN的性能优化不局限于底层,而是通过与xqueeze工具链的配合,在算法和指令两个层面同步发力,为更为深入的优化创造空间。
如下图所示,在算法层,xqueeze的剪枝在压缩模型尺寸的同时,也促进了网络的稀疏化——即催生出大量的零值权重。相应地,xNN在指令层实现了稀疏运算模块,在卷积和全连接计算中,自动忽略这些零值权重,减小计算开销,提升速度。又如之前已经提到的,在xqueeze的network transform阶段,会对网络进行宏观层面的优化,包括将相邻的层进行结果上等效的组合与替换,来减少计算的冗余度和提高访问存储器的效率。要充分发挥network transform的效能,也离不开指令层实现的支持。