TensorFlow学习笔记(四):Tensorflow网络构建和TensorBoard进行训练过程可视化
0. 相关信息
- Tensorflow版本:r0.10.0
- Github地址(fork from yhlleo/mnist):https://github.com/nxcxl88/mnist/tree/r0.10.0-patch-1
- MNIST数据相关问题:MNIST数据应该从http://yann.lecun.com/exdb/mnist/下载,即文章给出的四个压缩文件,然后在mnist_with_summaries.py内建立一个文件夹(名称:Mnist_data),把这些压缩文件放进去,mnist_with_summaries.py会调用input_data.py(注意本文章给出的Github文件是yhllleo改动的版本),可以直接处理这些压缩包。
1. mnist_with_summaries.py
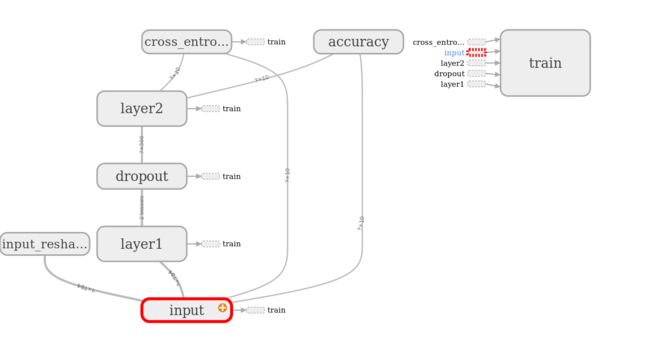
1.1 网络结构定义
1.2 训练过程
训练过程的重点步骤是:
1. 118-120行:计算交叉熵:diff = y_ * tf.log(y) cross_entropy = -tf.reduce_mean(diff)
2. 124行:调用优化器进行训练:train_step = tf.train.AdamOptimizer(FLAGS.learning_rate).minimize(cross_entropy)
3.164\172:通过session.run调用train_step进行运算和参数调整,在该过程中就会自动调用前向运算过程。
1.3 测试过程
测试集和训练集的切换通过feed_dict函数进行切换,当train为true时,调用训练集中数据,反之调用测试集数据。
测试在157行,计算准确度accuracy,通过session.run()进行调用:summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False))
2. TensorBoard训练过程可视化
Tensorboard.py的路径是(对于安装anaconda):anaconda2/envs/tensorflow/lib/python2.7/site-packages/tensorflow/tensorboard/tensorboard.py
运行的命令是python tensorboard.py --logdir=/tmp/mnist_logs/
Tensorboard不是无缘无故显示出各种统计数据,而需要在mnist_with_summaries.py中定义两种类型的数据记录:计算图可视化,以及训练过程可视化。
计算图可视化就是前面提到的with语句,以及在数据定义过程中赋予的name变量,如tf.placeholder(tf.float32, [None, 784], name='x-input')中,x-input就是为了计算图可视化所设置的名称变量。另外,还需要调用SummaryWriter将图写入文件夹。可以参见极客学院的wiki:计算图可视化。
训练过程可视化,则需要在mnist_with_summaries.py中加入summary语句,summary有以下几种: tf.scalar_summary用于记录数据, tf.image_summary用于记录图片, tf.histogram_summary则会计算某个数据的分布, tf.nn.zero_fraction和tf.scalar_summary配合使用,记录矩阵0元素,tf.merge_summary和tf.merge_all_summaries用于归集summary。在运行session时,还需要将summary的变量带入计算,可以参见极客学院的wiki:训练过程可视化。
(2017.4.20 Tensorflow 0.12对summary进行了进一步规范,需要调用tf.summary.scalar函数进行数据记录的定义)
为了将训练过程和测试过程的数据分隔开,可以使用两个文件夹记录数据:
train_writer = tf.train.SummaryWriter(FLAGS.summaries_dir + '/train', sess.graph)
test_writer = tf.train.SummaryWriter(FLAGS.summaries_dir + '/test')
注意第一次调用SummaryWriter的时候写入了计算图信息,如果不写,tensorboard也是无法显示计算图的,会出现No graph definition files were found.的错误。2.1 记录不在session graph中的数据
利用tf.summary.scalar等函数定义的量一般都是在定义session的过程中进行定义,需要通过session.run来进行数据记录,当出现在graph以外的数据时,就无法通过session.run来获得summary proto,就需要自己进行数据定义,否则调用add_summary函数添加记录时就会出现如下的错误:“expected tensorflow.Summary got Tensor”
这时候就需要另外定义summary数据类型来进行数据记录:
from tensorflow.core.framework import summary_pb2
value = summary_pb2.Summary.Value(tag="Accuracy", simple_value=0.95)
summary = summary_pb2.Summary(value=[value])