Hadoop在standalone模式下只有FIFO Scheduler 和 Fair Scheduler;
Hadoop-yarn模式下有FIFO Scheduler,Capacity Scheduler 和 Fair Scheduler策略
FIFO Scheduler:
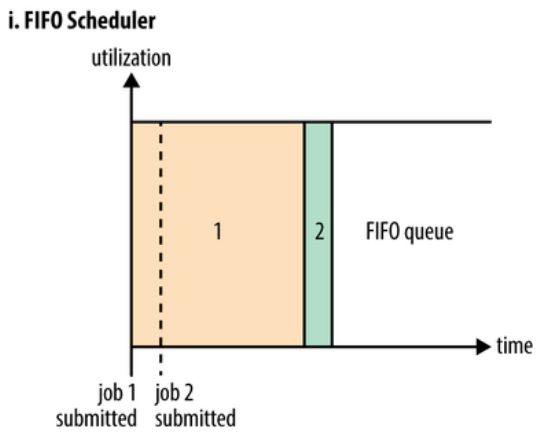
先进先出策略,就是按照application提交的顺序来执行的 ,这些application都会放在一个队列里, 前一个执行完了才会执行下一个。
缺点:提交耗时长的任务后,会导致后面的任务长期处于饥饿状态。
Capacity Scheduler
hadoop默认的调度器
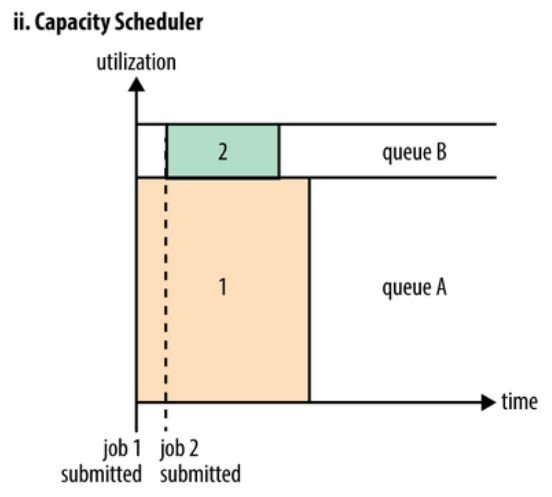
Capacity Scheduler为每个人分配一个队列,每个队列占用的集群资源可以是相同的也可以是不同的,队列内部还是采用FIFO调度的策略。
如上图所示,队列A和B都各自占有不同的资源,但是A占用的比B更多,在任务执行的时候,如果集群中恰好有空闲的资源,比如B队列中的资源,那么调度器就可以将B队列中空闲的资源分配给队列A,这种方式被称为弹性队列(queue elasticity)。
但是弹性队列也有副作用,B队列的资源被分配给A后,此时队列B又有了新的任务,但是B队列资源不够,此时只能等A队列中的任务执行完。为了方式一个对列占用过多的资源,yarn提供了一个可以设置的参数,用来设置,某个队列能够占用的最大资源。(这个参数的设置需要权衡以达到最优 )
队列支持层级关系,如下:
root
├── prod
└── dev
├── eng
└── science
配置如下
#设置root队列
yarn.scheduler.capacity.root.queues
prod,dev
#设置子队列
yarn.scheduler.capacity.root.dev.queues
eng,science
#设置pro队列理论上占的资源比重 yarn.scheduler.capacity.root.prod.capacity
40
yarn.scheduler.capacity.root.dev.capacity
60
#设置dev队列最大能占的资源比重(开始为60% 最大为75%)
yarn.scheduler.capacity.root.dev.maximum-capacity
75
#eng的两个子队列各占父队列一半。由于没有设最大占用值,所以可能出现占用整个父队列的情况 yarn.scheduler.capacity.root.dev.eng.capacity
50
yarn.scheduler.capacity.root.dev.science.capacity
50
通过配置参数来设置job运行时所在的队列:
mapreduce.job.queuename
指明队列的时候不需要(也不能包含父队列),比如eng不能写成root.dev.eng
Fair Scheduler
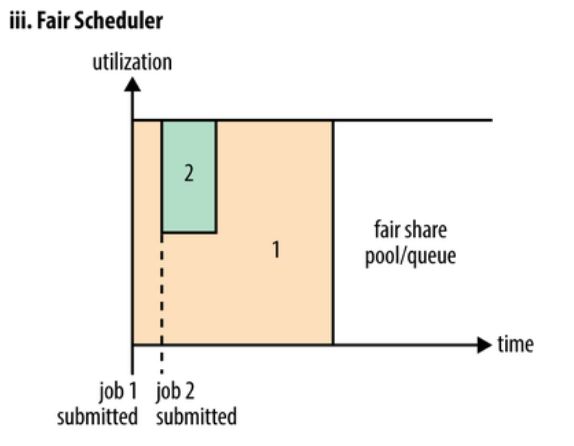
公平调度是一种赋予作业(job)资源的方法,它的目的是让所有的作业随着时间的推移,都能平均的获取等同的共享资源。所有的 job 具有相同的资源。
当单独一个作业在运行时,它将使用整个集群。当有其它作业被提交上来时,系统会将任务(task)空闲资源(container)赋给这些新的作业,以使得每一个作业都大概获取到等量的CPU时间。
与Hadoop默认调度器维护一个作业队列不同,这个特性让小作业在合理的时间内完成的同时又不"饿"到消耗较长时间的大作业。它也是一个在多用户间共享集群的简单方法。公平调度可以和作业优先权搭配使用——优先权像权重一样用作为决定每个作业所能获取的整体计算时间的比例。同计算能力调度器类似,支持多队列多用户,每个队列中的资源量可以配置, 同一队列中的作业公平共享队列中所有资源。
title: Hadoop任务调度策略
categories: Spark
tags:
- Spark
date: 2018-04-15
typora-root-url: Hadoop任务调度策略
Hadoop在standalone模式下只有FIFO Scheduler 和 Fair Scheduler;
Hadoop-yarn模式下有FIFO Scheduler,Capacity Scheduler 和 Fair Scheduler策略
FIFO Scheduler:

先进先出策略,就是按照application提交的顺序来执行的 ,这些application都会放在一个队列里, 前一个执行完了才会执行下一个。
缺点:提交耗时长的任务后,会导致后面的任务长期处于饥饿状态。
Capacity Scheduler
hadoop默认的调度器

Capacity Scheduler为每个人分配一个队列,每个队列占用的集群资源可以是相同的也可以是不同的,队列内部还是采用FIFO调度的策略。
如上图所示,队列A和B都各自占有不同的资源,但是A占用的比B更多,在任务执行的时候,如果集群中恰好有空闲的资源,比如B队列中的资源,那么调度器就可以将B队列中空闲的资源分配给队列A,这种方式被称为弹性队列(queue elasticity)。
但是弹性队列也有副作用,B队列的资源被分配给A后,此时队列B又有了新的任务,但是B队列资源不够,此时只能等A队列中的任务执行完。为了方式一个对列占用过多的资源,yarn提供了一个可以设置的参数,用来设置,某个队列能够占用的最大资源。(这个参数的设置需要权衡以达到最优 )
队列支持层级关系,如下:
root
├── prod
└── dev
├── eng
└── science
配置如下
#设置root队列
yarn.scheduler.capacity.root.queues
prod,dev
#设置子队列
yarn.scheduler.capacity.root.dev.queues
eng,science
#设置pro队列理论上占的资源比重 yarn.scheduler.capacity.root.prod.capacity
40
yarn.scheduler.capacity.root.dev.capacity
60
#设置dev队列最大能占的资源比重(开始为60% 最大为75%)
yarn.scheduler.capacity.root.dev.maximum-capacity
75
#eng的两个子队列各占父队列一半。由于没有设最大占用值,所以可能出现占用整个父队列的情况 yarn.scheduler.capacity.root.dev.eng.capacity
50
yarn.scheduler.capacity.root.dev.science.capacity
50
通过配置参数来设置job运行时所在的队列:
mapreduce.job.queuename
指明队列的时候不需要(也不能包含父队列),比如eng不能写成root.dev.eng
Fair Scheduler

公平调度是一种赋予作业(job)资源的方法,它的目的是让所有的作业随着时间的推移,都能平均的获取等同的共享资源。所有的 job 具有相同的资源。
当单独一个作业在运行时,它将使用整个集群。当有其它作业被提交上来时,系统会将任务(task)空闲资源(container)赋给这些新的作业,以使得每一个作业都大概获取到等量的CPU时间。
与Hadoop默认调度器维护一个作业队列不同,这个特性让小作业在合理的时间内完成的同时又不"饿"到消耗较长时间的大作业。它也是一个在多用户间共享集群的简单方法。公平调度可以和作业优先权搭配使用——优先权像权重一样用作为决定每个作业所能获取的整体计算时间的比例。同计算能力调度器类似,支持多队列多用户,每个队列中的资源量可以配置, 同一队列中的作业公平共享队列中所有资源。