Spark 在京东物流财务计费应用中的一些常见参数优化
财务需要进行物流总公司同各子公司间的计费及结算,每月初完成核算入账,既要完成对海量数据计费,又要完成对下游系统的下发。经过调研,Spark 提供了比 MapReduce 编程模型更为灵活的 DAG 编程模型,且支持多源异构数据处理,在提升了开发效率的同时,更能够在短时间内完成错综复杂的计费任务。
在实践的过程中,研发团队整理了一些问题解决的经验,供大家参考。
业务系统将计费所需生产单据中相关字段、报价数据、主数据等进行数据清洗、分配并存储,财务计费系统根据各业务类型特征,按照计费引擎中流程、公式,进行计费处理,并将结果存入明细库中以供结算使用。
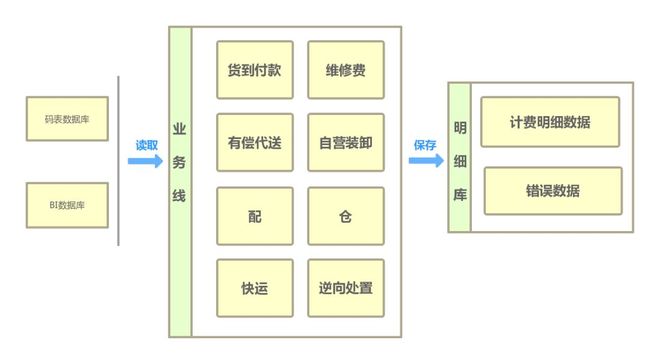
计费原始数据按父单汇总后首先进行关键字段的校验,对缺失计费必需的字段进行过滤,并将这些数据存入错误表中。校验成功后通过broadcast获取的报价折扣信息以及计费源数据按各自的计费公式进行不同类型的计费,并将结果落库。
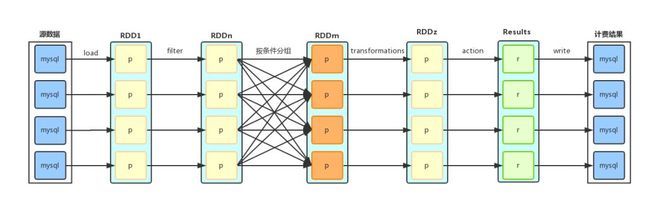
通过 Spark 在分布式的环境下处理计费数据,过滤计费条件,计算计费金额,生成结算明细,充分利用分布式系统高效、容错等特点,提供可扩展、高可用的计费服务。由于其优先使用内存,故内存的管理对性能有重大影响。所以,理解并设置好 Spark 在内存分配方面的参数,是首先要解决的问题。
Spark1.6.0 前使用的内存管理模式由StaticMemoryManager实现。而Spark1.6.0 后使用的内存管理模式由UnifiedMemoryManager实现。当然,也可以通过参数spark.memory.useLegacyMode来配置使用哪种内存管理模式。默认为false表示使用新方案。
StaticMemoryManager模式下(如下图所示),堆空间分为Storage区和Shuffle区。
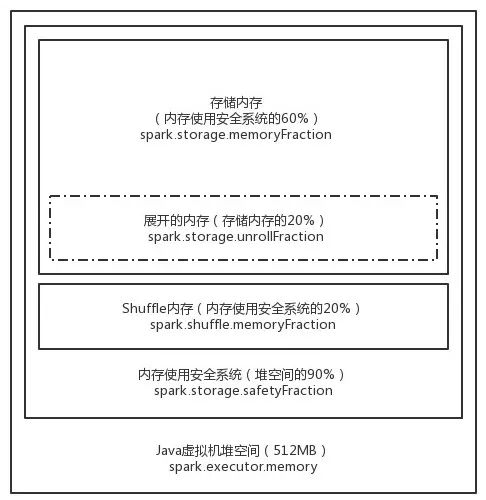
Storage区能使用的堆空间比例由spark.storage.memoryFraction指定,默认值是0.6,为了避免内存溢出的风险,还有一个参数spark.storage.safetyFraction来指定安全区比例,该参数的默认值是0.9,故实际可用的Storage区为堆空间的0.9 * 0.6 = 0.54。
如果Spark作业中有较多的RDD持久化操作,则可以将spark.storage.memoryFraction的值适当提高一些,保证持久化的数据能够容纳在内存中,避免内存不够缓存所有数据,导致数据只能写入到磁盘中,降低了性能。
如果Spark作业中的Shuffle类操作比较多,而持久化的操作比较少,那么可以将spark.storage.memoryFraction的值适当降低一些,而将spark.shuffle.memoryFraction的值适当提高一些,以避免Shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,而降低性能。
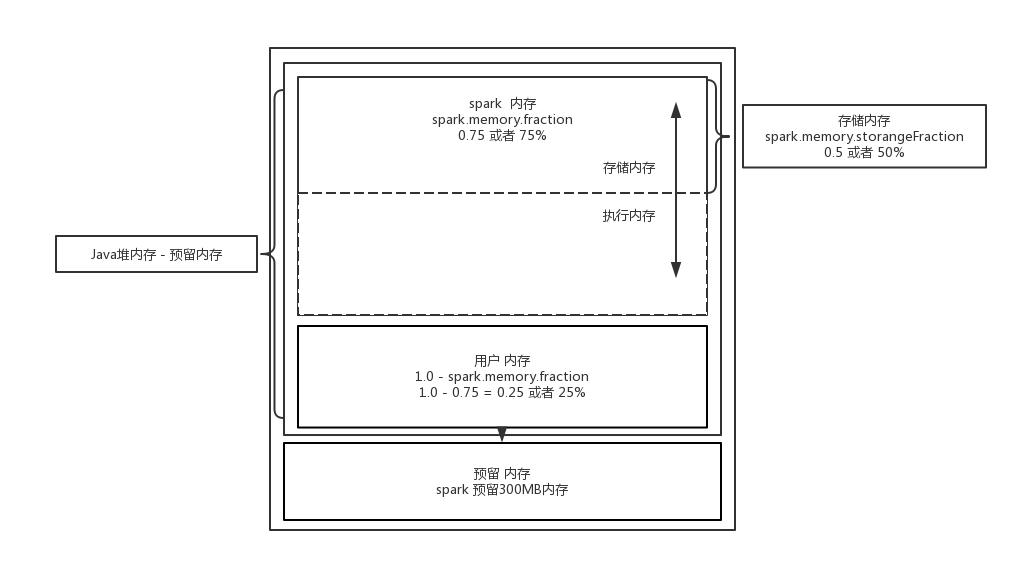
UnifiedMemoryManager模式下(如上图所示), 整个堆空间分为Spark Memory和User Memory,在Spark Memory内部又分为Storage Memory和Execution Memory,Storage Memory和Execution Memory并没有硬界限,可以相互借用空间。
Storage Memory:相当于旧版本的storage空间。假设executor有 2GB 内存,那么Storage Memory的大小是:(2GB-300MB)* 75% * 50% = 655.5MB。
Execution Memory:相当于旧版本的shuffl空间。executor如果在空间不足的情况下,除了选择向Storage Memory借空间外,也可以把数据spill到磁盘上。
属性名称 |
默认值 |
含义 |
spark.yarn.executor.memoryOverhead |
executorMemory * 0.10, with minimum of 384 |
在集群模式下,每个driver分配的堆外内存。 |
spark.shuffle.memoryFraction |
0.2 |
reduce端聚合内存占比 |
spark.shuffle.io.maxRetries |
3 |
由于IO异常而失败时的自动重试次数 |
spark.shuffle.io.retryWait |
5s |
每次重试拉取数据的等待间隔 |
当处理的数据量特别大时,由于 Executor 的堆外内存不够用从而导致内存溢出,最终导致后续 Stage 的task从executor中拉取文件失败,出现file not found报错,最终造成spark作业崩溃。
此时可以将spark.yarn.executor.memoryOverhead的值调大到至少1GB以上,这样不仅可以避免某些oom的问题,同时也可以让spark作业的性能得到一定提升。
另外当task如需要从其他节点获取数据,若刚好此节点再进 GC,就会导致暂时无法获取数据。默认情况下,如果15s内还是无法获取数据,就会出现file not found的情况,进而导致task重试,stage重试甚至app失败的情况。
参数spark.shuffle.io.maxRetries=3表示在shuffle文件拉取的时候,如果没有拉取到(拉取失败),最多或重试几次(会重新拉取几次文件),默认是3次。spark.shuffle.io.retryWait=5s表示每一次重试拉取文件的时间间隔,默认是5s。解决办法是调大上述参数。
在 GC 统计日志中观察到在处理一些逻辑时过于频繁的发生 GC,而这些对象并未被回收掉,进而导致老年代内存空间不足。
Spark 默认情况下使用60%的空间进行缓存 RDD 的内容。也就是说,Task 在执行的时候,只有40%的空间。如果不够用,就会触发频繁的 GC。可以设置spark.memory.fraction参数来调整空间的使用,例如,降低 Cache 的空间,让task使用更多的空间创建对象和完成计算。
如果在过去经常发生Full GC,还可以考虑设置-Xmn调整Eden区域:需要首先对 RDD 中操作的对象和数据进行大小评估,如果在 HDFS 上解压后,一般体积可能会变成原有块大小的2 - 3倍左右,根据数据的大小设置 Eden。
例如有200个task,每个task处理的 HDFS 上的数据是512M,则可以预估 Eden 的大小为200 * 512MB * 2(可再适当调大),同时继续监控 GC 的频率和耗费的时间。
通过Spark Web UI发现有spill相关的信息,业务逻辑运行的时候被迫把数据溢出写到磁盘上。
这种情况需要调整参数spark.shuffle.memoryFraction。默认大小是0.2,表示业务逻辑运行占用Executor的内存大小的20%。调整的时候可以逐渐调大。调整的越大,Spill到磁盘的次数就越少,次数越少,从磁盘中读取文件的时候数量也会越少。
由于系统中处理的数据都跟钱有关,系统出现故障将直接导致计费的损失。物财计费系统在保证计费准确性的同时又要保证时效性,相关参数的调优就成了顺利高效计费的保障。
经过一段时间的测试和实际的线上运行,物财计费系统可以稳定快速的对数十亿的数据处理并计算,而且系统的设计性能高于线上的平均负载流量,可轻松应对大促时的数据量激增。
整个处理过程中,重要的数据指标有监控,关键操作有日志记录,万一出现异常方便排查问题。很好地支持了物财计费的需求。