深度之眼Paper带读笔记NLP.15:多层LSTM
文章目录
- 前言
- 第一课 论文导读
- 机器翻译简介
- 机器翻译相关方法
- 前期知识储备
- 第二课 论文精读
- 论文整体框架
- 传统/经典算法模型
- 1.Encoder-Decoder(见导读)
- 2.基于attention的机器翻译
- 模型
- 实验和结果
- 数据集
- 实验结果
- 讨论和总结
- 讨论
- 总结(主要创新点)
- 参考论文
- 复现(略)
前言
本课程来自深度之眼deepshare.net,部分截图来自课程视频。
文章标题:Sequence to Sequence Learning with Neural Networks
使用多层LSTM的Seq2Seq模型
作者:llya Sutskever,Oriol Vinyals,Quoc V. Le
单位:Google
发表会议及时间:NIPS2014
在线LaTeX公式编辑器
第一课 论文导读
a. 神经机器翻译概率
神经机器翻译就是使用神经网络使得机器能够自动将一种语言的句子翻译成另外一种语言的句子,它可以解决不同母语的人之间的交流障碍。
b. 两种神经机器翻译模型
最开始的神经机器翻译模型只是使用一个多层的LSTM,多层LSTM的最底层为源语言的输入,多层LSTM的最高层为目标语言的输出。之后产生了Encoder-Decoder的模型,即Encoder将源语言的句子压缩成一个向量,Decoder利用压缩得到的向量生成目标语言的句子。
c. LSTM以及多层LSTM
LSTM是一种特殊的RNN,通过增加一个记忆细胞和几个门来加强序列处理的长距离依赖。而多层LSTM就是单层LSTM网上叠加,上一层LSTM每一个时间步的输出作为当前层LSTM的输入。
机器翻译简介
机器翻译:使用机器自动将某种语言的一句话翻译成另外一种语言。
意义:可以解决人类之间因为不同语言交流不畅的问题。
16年的图:

机器翻译领域还有很多问题函待解决,19年ACL的BEST paper就是关于机器翻译中曝光度的研究。
机器翻译相关方法
Generating Sequences With Recurrent Neural Networks
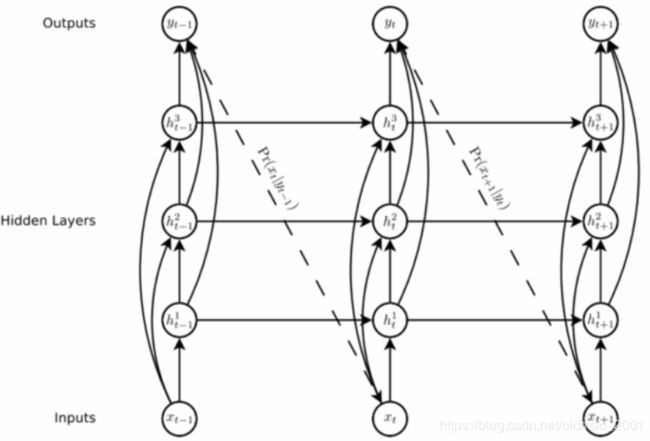
加解码器来自下面的文章:
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation(好熟悉的文章名。。。)
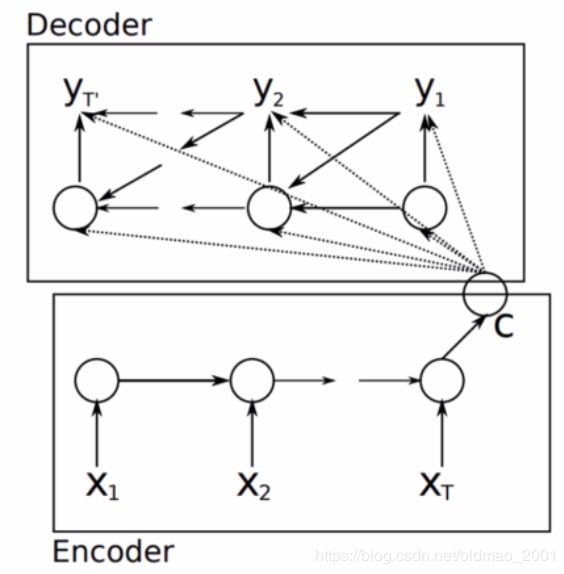
Encoder:普通的LSTM,将一句话映射成一个向量C。
Decoder:对于隐藏层:
h t = f ( h t − 1 , y t − 1 , c ) h_t=f(h_{t-1},y_{t-1},c) ht=f(ht−1,yt−1,c)
对于输出层:
P y t = g ( h t , y t − 1 , c ) P_{y_t}=g(h_{t},y_{t-1},c) Pyt=g(ht,yt−1,c)
前期知识储备
·了解LSTM以及多层LSTM
·LSTM是最常用的RNN模型之一,RNN介绍可以参考
点我去看
·多层LSTM:实质上是单层LSTM的叠加
·了解Seq2Seq模型
·了解Seq2Seq模型的相关概念以及其中Encoder和Decoder的含义。可以参考点我去看
第二课 论文精读
论文整体框架
摘要
1.介绍
2.模型
3.实验
4相关工作
5&6.总结&致谢
传统/经典算法模型
1.Encoder-Decoder(见导读)
2.基于attention的机器翻译
来自之前读过的:Neural Machine Translation by Jointly Learning to Align and Translate
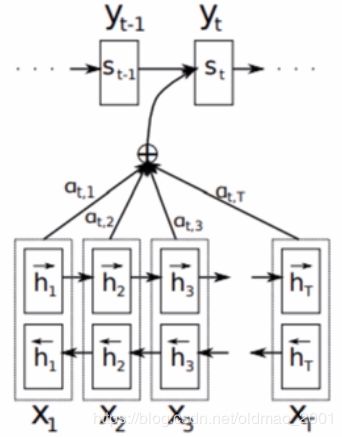
Encoder:单层双向LSTM。(就是下图中下面两层方框)
Decoder:
对于输出:
p ( y i ) = g ( y i − 1 , s i , c i ) p(y_i)=g(y_{i-1},s_i,c_i) p(yi)=g(yi−1,si,ci)
对于 c i c_i ci:
c i = ∑ j = 1 T x a i j h j , a i j = e x p ( e i j ) ∑ k = 1 T x e x p ( e i k ) c_i=\sum_{j=1}^{T_x}a_{ij}h_j,a_{ij}=\frac{exp(e_{ij})}{\sum_{k=1}^{T_x}exp(e_{ik})} ci=j=1∑Txaijhj,aij=∑k=1Txexp(eik)exp(eij)
w h e r e e i j = a ( s j − 1 , h j ) where \space e_{ij}=a(s_{j-1},h_j) where eij=a(sj−1,hj)
模型
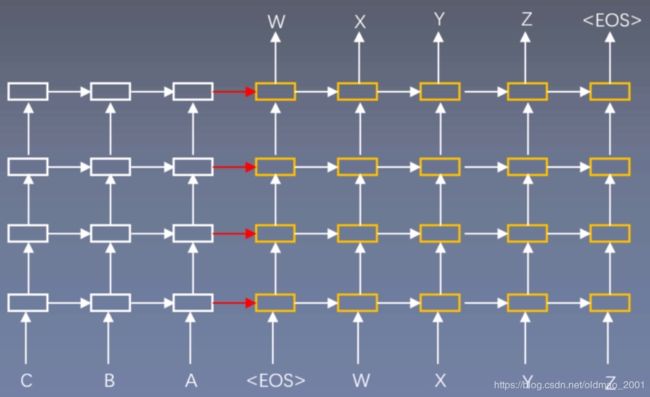
神经机器翻译模型Neural Machine Translation Model
1.Encoder和Decoder是不同的LSTM。(下图中有白色和黄色)
2.使用4层的深度LSTM。(从下往上数)
3.将输入逆序输入。(原输入是ABC)这样输入的开始部分和输出离得比较近,因此开始部分翻译效果比较好,但是会导致后面部分翻译效果一般。
实验和结果
数据集
WMT’14English to French:包含36M英语到法语的双语语料,是机器翻译领域最常用的语料之一。
lwslt14English to German:包含170K英语到德语的双语语料,机器翻译领域最常用的语料之一,是一个相对较小的语料。
实验结果
Results本文提出的模型在单模型上比Bahdanau的基于attention的模型(第一个)要好得多,并且继承多个模型之后得到了非常好的结果。
single代表单个模型,不是单层LSTM。
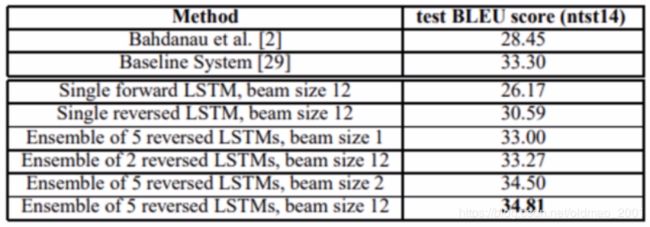
使用本文提出的模型结合统计机器翻译馍型最终得到了比state-of-the-art只差0.5的相当好的结果。

该模型对词序是敏感的:
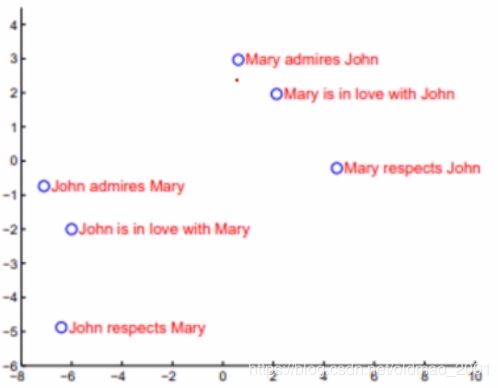
讨论和总结
讨论
为什么要讲这篇论文?
这篇论文提出的多层LSTM的结构是transformer出来之前机器翻译领域的标准做法。
本文提出的模型有何缺点?
LSTM的缺点就是并行差,所以后来有很多使用CNN和transformer做机器翻译的文章
后来的改进模型?
后来的改进主要集中在attention上。
总结(主要创新点)
A.对于Encoder和Decoder使用不同的LSTM。
B.在Encoder和Decoder中都是用了多层LSTM。
C.对输入进行逆序输入可以大大提高翻译效果。
对比模型:本文对比了基于attention的神经机器翻译模型和传统的统计机器翻译模型。
模型:本文提出了一种基于多层LSTM的神经机器翻译模型。
实验:本文提出的模型在单模型和结合统计机器翻译的模型上都取得了非常好的结果。
参考论文
D. Bahdanau,K. Cho, and Y. Bengio. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473,2014.