前言
上一篇文章(创建你的第一个应用模块(module))已经大致描述了odoo的模型层(model)和视图层(view),这一篇文章,我们将系统地介绍有关于model的知识,其中包括:
1、模型的类型:Model、TransientModel、AbstractModel 2、模型的属性:_name,_description,_table,_order等 3、模型的字段类型:Char、Boolean、Selection、Binary、Integer、Float、Date、Datetime、Html、Text、Many2one、One2many等 4、模型的字段属性:string,default,help,index,copy,readonly,required,groups,states,translate,compute,store,domain,related等
5、模型的自带字段:create_uid,create_date,write_uid,write_date
6、模型的修饰器:@api.multi,@api.model,@api.constrains,@api.onchange,@api.depends等
7、模型的生命周期方法:create、write、unlink、default_get、name_get等
模型的类型
odoo的模型是系统的数据中心,所有的数据都通过odoo类的ORM(对象关系映射)映射到数据库的表,所有的数据操作除了直接通过sql查询外,都通过odoo类进行操作。odoo类通过python继承models.Model、models.TransientModel、models.AbstractModel实现,其中:系统会为Model, TransientModel的所有字段建立数据库字段,不会为AbstractModel建立任何数据库字段。
Tips: 1、Odoo的命名遵循大驼峰的命名方式(eg. EmployeeSalary) 2、Odoo通过python类继承实现模型定义(eg. Class Employee(models.Model))
1、Model
Model是存储数据记录的最主要手段,它是持久化地对数据记录(record)进行存储,直至对其进行删除。例如我们在上一节建立的员工模块,它继承的就是models.Model,它将会存储所有的员工档案信息,这也是我们想要的。
2、TransientModel
TransientModel我们称之为"瞬时模型",数据库也会为瞬时模型存储数据,但是Odoo会有专门的定时任务对瞬时模型进行清空,这将会大大节省了数据的存储空间。它的优点在于可以使用Odoo正常的功能函数,但是不会对数据库造成数据负担,主要的用途就是向导(wizard)。例如:res.config.settings模型使用的就是瞬时模型,它在专门的地方对其他模型的数据值进行配置,而不产生多余存储空间。我们在odoo12之应用:一、双因子验证(Two-factor authentication, 2FA)一节中使用"导出翻译"功能界面就是一个由瞬时模型写的向导界面:
# -*- coding: utf-8 -*- # Part of Odoo. See LICENSE file for full copyright and licensing details. import base64 import contextlib import io from odoo import api, fields, models, tools, _ NEW_LANG_KEY = '__new__' class BaseLanguageExport(models.TransientModel): _name = "base.language.export" _description = 'Language Export' @api.model def _get_languages(self): langs = self.env['res.lang'].search([('translatable', '=', True)]) return [(NEW_LANG_KEY, _('New Language (Empty translation template)'))] + \ [(lang.code, lang.name) for lang in langs] name = fields.Char('File Name', readonly=True) lang = fields.Selection(_get_languages, string='Language', required=True, default=NEW_LANG_KEY) format = fields.Selection([('csv','CSV File'), ('po','PO File'), ('tgz', 'TGZ Archive')], string='File Format', required=True, default='csv') modules = fields.Many2many('ir.module.module', 'rel_modules_langexport', 'wiz_id', 'module_id', string='Apps To Export', domain=[('state','=','installed')]) data = fields.Binary('File', readonly=True) state = fields.Selection([('choose', 'choose'), ('get', 'get')], # choose language or get the file default='choose') @api.multi def act_getfile(self): this = self[0] lang = this.lang if this.lang != NEW_LANG_KEY else False mods = sorted(this.mapped('modules.name')) or ['all'] with contextlib.closing(io.BytesIO()) as buf: tools.trans_export(lang, mods, buf, this.format, self._cr) out = base64.encodestring(buf.getvalue()) filename = 'new' if lang: filename = tools.get_iso_codes(lang) elif len(mods) == 1: filename = mods[0] extension = this.format if not lang and extension == 'po': extension = 'pot' name = "%s.%s" % (filename, extension) this.write({'state': 'get', 'data': out, 'name': name}) return { 'type': 'ir.actions.act_window', 'res_model': 'base.language.export', 'view_mode': 'form', 'view_type': 'form', 'res_id': this.id, 'views': [(False, 'form')], 'target': 'new', }
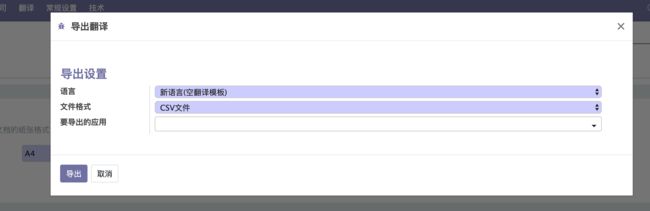
它通过在view中"导出"按钮实现调用act_getfile方法,实现导出功能,并return回到base.language.export页面中。
<footer states="choose"> <button name="act_getfile" string="Export" type="object" class="btn-primary"/> <button special="cancel" string="Cancel" type="object" class="btn-secondary"/> footer>
3、AbstractModel
AbstractModel(抽象类模型)和我们平时理解的面向对象语言中的抽象类是类似的功能,在抽象类中定义一些通用的字段和方法,在子类中进行继承或者重写,可以理解为它是没有"多态"功能的抽象类。比如我们使用的所有字段类: Integer、Float等,还有MailThread,都是抽象模型,为子类实现部分功能。
class Float(models.AbstractModel): _name = 'ir.qweb.field.float' _description = 'Qweb Field Float' _inherit = 'ir.qweb.field.float' @api.model def from_html(self, model, field, element): lang = self.user_lang() value = element.text_content().strip() return float(value.replace(lang.thousands_sep, '') .replace(lang.decimal_point, '.'))
模型的属性
我们主要介绍几个常用的属性:
_name: 必填属性,odoo类的唯一标识,全局不能重复。 _description: 描述属性,只在查看模型界面的时候作为展示使用,没有实际用户,可选不填,但好的编码习惯我们应该书写尽量详尽的描述。 _table:对应的数据库表名,可选,默认为模型的_name替换.为_,实际上为了方便和统一,我们在一般的情况下不修改数据库表名。 _order: 数据视图的排列顺序,实用功能,方便tree视图的查看,例如我们使用_order = 'sequence,id'表示根据单号和记录id排序, "create_date desc":根据最新创建时间排序。
Tip:为了代码的可读性以及数据可维护性,笔者建议不要使用_table和_order功能。
视图排序功能可以通过在tree/kanban视图中使用default_order实现:
"xxx" default_order="create_date desc">
模型的字段类型
Char: 单行文本 Boolean: 逻辑字段,True/False Selection: 列表选择字段,第一个参数为元组列表,表示可选列表, 如: GENDER = [ ('male', u'男'), ('female', u'女'), ('other', u'其他') ] gender = fields.Selection(GENDER, string=u'性别') Binary: 二进制字段,通常用于图片、附件等文件读写 Integer: 整型字段 Float: 浮点型字段,可以指定位数digits,使用元组(a,b),其中a是总位数,b 是保留小数位 Date: 日期对象,精确到天 Datetime: 日期对象,精确到秒 Html: 界面展示HTML内容,带有富文本编辑器 Text: 多行文本,表现为textarea Many2one: 多对一关系字段,如: company_id = fields.Many2one('res.company', string=u'公司') 表现为多个员工可以对应同一个公司,'res.company'是odoo内置公司模型 One2many:一对多关系字段,如: subordinate_ids = fields.One2many('ml.employee', 'leader_id', string=u'下属') 表示一个员工可以有多个下属
_sql_constraints: 为数据库添加约束,例如:
_sql_constraints = [
('attendance_name_uniq', 'unique (name)', u'编码不能重复!'),
]
模型的字段属性
string: 字段的默认标签,展示于用户界面,不声明的话odoo将会采用字段名。它通常是第一个参数(一对多,多对一,多对多和Selection除外),也可以使用string="xxx"放置于任何位置。在xml视图中,可以使用"xxx" string="XXX" />替代默认标签 default: 设置默认值,允许是函数或者匿名函数,例如: fields.Date(string='XXX', default=fields.Date.context_today) help: 帮助信息,通常进行描述字段,将鼠标放置于界面字段上将会显示帮助信息。 index: 会为数据库字段添加索引,加快数据读取速度 copy: 复制时是否复制当前字段,除了关联字段外,默认为True readonly: 控制字段是否不可编辑。仅对用户界面生效,对API调用不生效,如: date = fields.Date(readonly=True, default=fields.Date.context_today) self.update{ date: '2019-01-01' } 依然生效 required: 控制字段是否必填, 会为数据库添加约束NOT NULL,因此对API调用是生效的 groups: 控制字段权限,为字段分权限组,只有处于该权限组的用户可见该字段 states: 控制不同状态下字段的属性,表现在用户界面。如: states={'draft':[('readonly', '=', False), ('invisible', '=', 'False), ('required', '=' True]} translate: 表示是否对这个字段生成翻译 store: 是否存储该字段,除了compute字段和关联字段,其他字段默认都为True compute: 计算字段,属性值为函数名,会为该字段调用对应的函数获取返回值作为字段的值,拥有该属性的字段默认readonly为True,store为False domain: 用于Many2one字段,筛选对应模型的可选记录值 related: 关联字段,用于与其他模型字段进行关联,不会创建数据库字段,默认只读,如果设为可写(readonly=False),字段的修改将会直接影响被关联的字段。如: is_open_2fa = fields.Boolean(related='company_id.is_open_2fa', string="Open 2FA", readonly=False) 前提是模型中有company_id这个关联字段
模型的自带字段
模型中还自带有四个默认的字段:create_uid,create_date,write_uid,write_date;
create_uid: 代表记录的创建用户
create_date: 代表记录的创建时间,Datetime类型
write_uid: 代表最近更新记录的值的用户
write_date: 代表最近更新记录的值的时间,Datetime类型
此外,还有一个active字段,代表记录是否有效
模型的修饰器
@api.multi:对记录集进行操作的方法需要添加此修饰器,此时self就是要操作的记录集。所以方法内应该对self进行遍历,例如: @api.multi def xxxxxxx(self): for record in self: do_something # 对数据集的一些操作 如果方法没有添加修饰器,默认为@api.multi @api.model:模型(model)层面的操作需要添加此修饰器,它不针对特定的记录,也不保留记录集,self是对模型的引用。相当于类静态函数。例如create方法,widget的调用方法。 注意:form视图自带按钮的调用应该使用@api.multi,因为它是针对特定记录的操作,而widget内自定的视图通过rpc或者call调用方法,应该使用@api.model,因为它是模型层面的调用。 @api.one: 老版本遗留修饰器,不推荐使用,在@api.multi中使用self.ensure_one()来代替
以上是对数据集和模型进行操作的修饰器。此外,还有对字段进行操作的修饰器:
@api.constrains:在界面层面对字段进行约束,对API调用不起效果,例如: @api.constrains('amount') def _check_amount(self): self.ensure_one() if self.amount < 0: raise ValidationError(_('The payment amount cannot be negative.')) @api.onchange:onchange方法只在用户界面表单视图中触发,当用户修改指定的字段值时,立即执行方法内的业务逻辑,可以用于数据的修改,用户提示等。 注意: 1、onchange修改的字段值在保存时会失效,需要在xml字段中使用force_save="1"来存储,如:
@api.multi @api.onchange('a') def _onchange_a(self): for record in self: record.lead_id = 'XXX'"lead_id" readonly="1" force_save="1" />
2、在不同的表单中,可以使用on_change="0"来禁止某个字段的onchange属性 @api.depends:compute字段所对应的方法需要使用该修饰器,以计算值,例如: # 将二维码的值赋给otp_qrcode变量 otp_uri = fields.Char(compute='_compute_otp_uri', string="URI") @api.depends('otp_uri') def _compute_otp_qrcode(self): self.ensure_one() self.otp_qrcode = self.create_qr_code(self.otp_uri)
模型的生命周期方法
create:记录创建方法,每次记录的创建都会调用create方法,可以在该方法中添加对数据的校验,自动生成单号等,例如下面的自动生成单号 @api.model def create(self, vals): if vals.get('name', '/') == '/': vals['name'] = self.env['ir.sequence'].next_by_code('picking.batch') or '/' return super(StockPickingBatch, self).create(vals) 注意,create方法应该使用@api.model修饰器,我们在任何情况下都应该调用父类的创建方法,以创建记录,并返回创建的对象: do something # 创建前的逻辑 rec = super(StockPickingBatch, self).create(vals) do other things # 创建后的逻辑 return rec write: 记录(record)的编辑方法,对已存在的记录进行编辑,如: @api.multi def write(self, values): tools.image_resize_images(values) return super(Employee, self).write(values) unlink:记录的删除方法,可以在这里对记录的删除添加限制,或者在删除时对其他信息进行清空,如: @api.multi def unlink(self): if any(line.holiday_id for line in self): raise UserError(_('You cannot delete timesheet lines attached to a leaves. Please cancel the leaves instead.')) return super(AccountAnalyticLine, self).unlink()
default_get:使用修饰器@api.model包裹,定义数据的默认值,跟字段中的default效果类似,例如: @api.model def default_get(self, fields): res = super(StockRulesReport, self).default_get(fields) product_tmpl_id = False if 'product_id' in fields: if self.env.context.get('default_product_id'): product_id = self.env['product.product'].browse(self.env.context['default_product_id']) product_tmpl_id = product_id.product_tmpl_id res['product_tmpl_id'] = product_id.product_tmpl_id.id res['product_id'] = product_id.id elif self.env.context.get('default_product_tmpl_id'): product_tmpl_id = self.env['product.template'].browse(self.env.context['default_product_tmpl_id']) res['product_tmpl_id'] = product_tmpl_id.id res['product_id'] = product_tmpl_id.product_variant_id.id if len(product_tmpl_id.product_variant_ids) > 1: res['product_has_variants'] = True if 'warehouse_ids' in fields: warehouse_id = self.env['stock.warehouse'].search([], limit=1).id res['warehouse_ids'] = [(6, 0, [warehouse_id])] return res name_get:定义记录的显示形式,特别是在Many2one字段中的显示,比较常用,例如: @api.multi @api.depends('employee_id') def name_get(self): """ 名称显示格式:[XXX]YYY """ result = [] for record in self: name = '[%s]员工' % (record.employee_id.name) result.append((record.id, name)) return result 那么它的展现形式就会是:[李三]员工
笔者的建议
1、使用onchange + force_save替代compute字段:尽量不要使用compute的字段,在API取值时,每次都会重新触发一次计算逻辑,重新计算字段的值,这将是一件十分耗时的操作,想象一下,假如你需要将某个模型中的10w条记录取到,每条记录中有四到五个compute字段,需要耗时多少?
2、使用default_get代替default,方便默认值的维护。
3、不用在字段属性中使用readonly,增加代码的阅读障碍,无法实现动态控制"是否可写",而在xml的字段属性attrs可以动态控制"是否可写",我们约定所有readonly写在xml中。
4、确实需要动态控制required的应写在xml中,不需要的尽量都写在类字段中,因为API的调用不受到xml中的required的影响。
5、字段的命名:Many2one字段使用xxx_id命名,One2many字段使用xxx_ids命名,增强代码可读性
声明
原文来自于博客园(https://www.cnblogs.com/ljwTiey/p/11492862.html)
转载请注明文章出处,文章如有任何版权问题,请联系作者删除。
合作或问题反馈,联系邮箱:[email protected]