官方文档:Natural Language Toolkit — NLTK 3.3 documentation
NLTK是一个高效的Python构建的平台,用来处理自然语言数据,它提供了易于使用的接口,通过这些接口可以访问超过50个语料库和词汇资源(如WordNet),还有一套用于分类、标记化、词干标记、解析和语义推理的文本处理库。NLTK可以在Windows、Mac OS以及Linux系统上使用。
1.安装NLTK
使用pip install nltk命令安装NLTK库,NLTK中集成了语料与模型等的包管理器,通过在python解释器中执行以下代码
import nltk
nltk.download()
便会弹出包管理界面,在管理器中可以下载语料,预训练的模型等。

除了一些个人数据包还可以下载整个集合(使用“all”),或者仅下载书中例子和练习中使用到的数据(使用“book”),或者仅下载没有语法和训练模型的语料库(使用“all-corpora”)。
2.简单文本分析
参考:NLTK学习之一:简单文本分析 - CSDN博客
基本功能:
- 分词
- 词性标注
- 命名实体识别
import nltk
#先分句再分词
sents = nltk.sent_tokenize("And now for something completely different. I love you.")
word = []
for sent in sents:
word.append(nltk.word_tokenize(sent))
print(word)
#分词
text = nltk.word_tokenize("And now for something completely different.")
print(text)
#词性标注
tagged = nltk.pos_tag(text)
print (tagged[0:6])
#命名实体识别
entities = nltk.chunk.ne_chunk(tagged)
print (entities)
>>>[['And', 'now', 'for', 'something', 'completely', 'different', '.'], ['I', 'love', 'you', '.']]
>>>['And', 'now', 'for', 'something', 'completely', 'different', '.']
>>>[('And', 'CC'), ('now', 'RB'), ('for', 'IN'), ('something', 'NN'), ('completely', 'RB'), ('different', 'JJ')]
>>>(S And/CC now/RB for/IN something/NN completely/RB different/JJ ./.)
3.词的概率分布类FreqDist
参考:使用Python+NLTK实现英文单词词频统计 - CSDN博客
NLTK之词频 - CSDN博客
1.利用NLTK的FreqDist方法获取在文本中每个出现的标识符的频数:
import nltk
from nltk.book import *
# 打开文件
f = open("D:\\App\\test.txt","r")
text = ""
line = f.readline()
while line:
text += line
line = f.readline()
f.close()
text1 = nltk.word_tokenize(text)
# 或者
text1 = nltk.word_tokenize("And now for something completely different. I love you. This is my friend. You are my friend.")
# FreqDist()获取在文本中每个出现的标识符的频率分布
fdist = FreqDist(text1)
print(fdist)
# 词数量
print(fdist.N())
# 不重复词的数量
print(fdist.B())
>>>
21
16
2.获取频率&频数:
# 获取频率
print(fdist.freq('friend') * 100)
# 获取频数
print(fdist['friend'])
#出现次数最多的词
fdist.max()
>>>9.523809523809524
2
'.'
3.绘制前5个标识符,并出现次数累加:
fdist.tabulate(5, cumulative=True)
# 绘图
fdist.plot(5,cumulative=True)
>>> . my friend And now
4 6 8 9 10
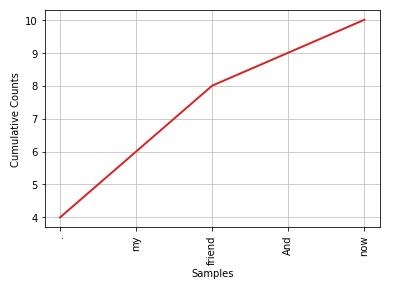
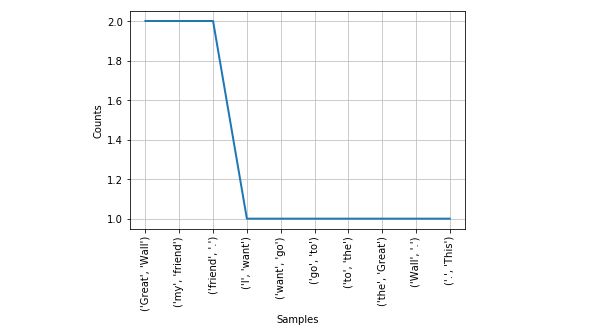
4.词组统计:
text = "I want go to the Great Wall. This is my friend. You are my friend. The Great Wall in China."
text1 = nltk.word_tokenize(text)
bgrams = nltk.bigrams(text1) #返回一个generate
bgfdist = FreqDist(list(bgrams)) #返回搭配的频率
bgfdist.plot(10) #查看前10个出现频率最高的搭配
4.词形还原
但是统计英文词频需要考虑到词形变化,例如move和moved、is和are应该归为一个词而不应该分为两个词来统计,所以需要对各种形式的单词进行词形还原(lemmatization)。
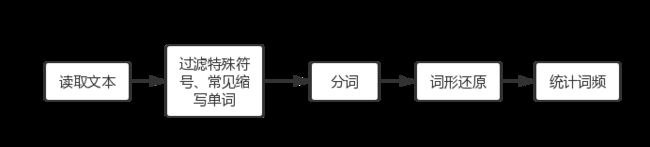
其中词形还原需要用到NLTK。在NLTK中,tag用来描述一个单词的词性(含词形、时态等概念),分词结果传入nltk.pos_tag方法,可以获得每一个单词的词性,如:('John', 'NNP')表示”John”的词性是NNP(Proper noun, singular),即专有名词单数。
进行词形还原并统计词频的完整代码:
import sys,re,collections,nltk
from nltk.stem.wordnet import WordNetLemmatizer
from nltk.tokenize import word_tokenize
# 正则表达式过滤特殊符号用空格符占位,双引号、单引号、句点、逗号
pat_letter = re.compile(r'[^a-zA-Z \']+')
# 还原常见缩写单词
pat_is = re.compile("(it|he|she|that|this|there|here)(\'s)", re.I)
pat_s = re.compile("(?<=[a-zA-Z])\'s") # 找出字母后面的字母
pat_s2 = re.compile("(?<=s)\'s?")
pat_not = re.compile("(?<=[a-zA-Z])n\'t") # not的缩写
pat_would = re.compile("(?<=[a-zA-Z])\'d") # would的缩写
pat_will = re.compile("(?<=[a-zA-Z])\'ll") # will的缩写
pat_am = re.compile("(?<=[I|i])\'m") # am的缩写
pat_are = re.compile("(?<=[a-zA-Z])\'re") # are的缩写
pat_ve = re.compile("(?<=[a-zA-Z])\'ve") # have的缩写
lmtzr = WordNetLemmatizer()
def replace_abbreviations(text):
new_text = text
new_text = pat_letter.sub(' ', text).strip().lower()
new_text = pat_is.sub(r"\1 is", new_text)
new_text = pat_s.sub("", new_text)
new_text = pat_s2.sub("", new_text)
new_text = pat_not.sub(" not", new_text)
new_text = pat_would.sub(" would", new_text)
new_text = pat_will.sub(" will", new_text)
new_text = pat_am.sub(" am", new_text)
new_text = pat_are.sub(" are", new_text)
new_text = pat_ve.sub(" have", new_text)
new_text = new_text.replace('\'', ' ')
return new_text
# pos和tag有相似的地方,通过tag获得pos
def get_wordnet_pos(treebank_tag):
if treebank_tag.startswith('J'):
return nltk.corpus.wordnet.ADJ
elif treebank_tag.startswith('V'):
return nltk.corpus.wordnet.VERB
elif treebank_tag.startswith('N'):
return nltk.corpus.wordnet.NOUN
elif treebank_tag.startswith('R'):
return nltk.corpus.wordnet.ADV
else:
return ''
def merge(words):
new_words = []
for word in words:
if word:
tag = nltk.pos_tag(word_tokenize(word)) # tag is like [('bigger', 'JJR')]
pos = get_wordnet_pos(tag[0][1])
if pos:
# lemmatize()方法将word单词还原成pos词性的形式
lemmatized_word = lmtzr.lemmatize(word, pos)
new_words.append(lemmatized_word)
else:
new_words.append(word)
return new_words
def get_words(file):
with open (file) as f:
words_box=[]
# pat = re.compile(r'[^a-zA-Z \']+') # 过滤特殊符号
for line in f:
#if re.match(r'[a-zA-Z]*',line):
# words_box.extend(line.strip().strip('\'\"\.,').lower().split())
# words_box.extend(pat.sub(' ', line).strip().lower().split())
words_box.extend(merge(replace_abbreviations(line).split()))
return collections.Counter(words_box) # 返回单词和词频
def append_ext(words):
new_words = []
for item in words:
word, count = item
tag = nltk.pos_tag(word_tokenize(word))[0][1] # tag is like [('bigger', 'JJR')]
new_words.append((word, count, tag))
return new_words
# 将统计结果写入文件
def write_to_file(words, file="D:\\App\\result.txt"):
f = open(file, 'w')
for item in words:
for field in item:
f.write(str(field)+',')
f.write('\n')
if __name__=='__main__':
print ("counting...")
words = get_words("D:\\App\\test.txt")
print ("writing file...")
write_to_file(append_ext(words.most_common()))
统计结果:

除NLTK之外,stanford提供的CoreNLP自然语言处理工具包也常被使用,有需要的可以进一步了解。
- 官网地址:http://stanfordnlp.github.io/CoreNLP/
- CoreNLP版本:3.9.1,下载stanford-corenlp-full-2018-02-27.zip压缩包
- 功能:
- 分词(tokenize)、分句(split)
- 词性标注(pos)
- 词形还原(lemma)
- 命名实体识别(ner)
- 语法解析(parse)
- 情感分析(sentiment)
- 支持语言:中文、英文、法语、德语、西班牙语、阿拉伯语等。
- 编程要求:Java1.8+