应用场景
Impala是目前主流的SQL on Hadoop查询引擎,它主要是针对分析类交互式查询场景设计的,特别适用于大数据量的全表数据扫描,多表关联以及汇总分析等。随着Impala的使用越来越广泛,很多客户在使用Impala做分析查询的同时,也开始使用Impala做单表的条件明细查询,例如基于手机号码查询过去一段时间的通话记录。由于Impala不支持索引,因此,即使只有几条通话记录,Impala也需要对全表做扫描,效率比较低。目前唯一的优化手段就是采用分区策略,但是仍然不能从根本上解决明细查询的性能问题。
为了更好的应对明细查询的应用场景,Impala在2.9版本推出了两个基于parquet文件格式的存储索引技术:min/max过滤,以及字典过滤。
min/max过滤
min/max存储索引只在底层文件格式是parquet时才有效。在parquet文件中,每个block(row group)会存放每个字段的在该block中最大和最小值统计信息。当Impala扫描parquet文件时,可以先判断min/max统计信息,然后决定是否读取该block,从而达到加速查询性能的目的。例如以下示例:
select * from cdr_table where calling_phone_num = '13700885960';
注意,min/max存储索引对于非排序的数据过滤不是非常有效。因此,为了有效的使用该功能,一般建议对数据按照某个常用的查询字段进行排序。在Impala中,支持在创建表的时候指定排序字段,这样当数据加载到这张表时,会自动进行排序。例如以下示例:
create table cdr_table (...)
sort by (calling_phone_num)
stored as parquet ;
目前min/max支持数值类型(包括numeric和decimal)、string类型以及timestamp类型。
字典过滤
在parquet文件格式中,会对每一个字段进行编码(encoding),缺省会采用PLAIN_DICTIONARY的编码方式,每个字段的字典(DICTIONARY)信息会在parquet block中的dictionary page中保存,Impala在扫描parquet block时会根据字典统计信息进行block级别的过滤;但是当这个字段在一个parquet block中的唯一值(DISTINCT Value)> 40,000时,该字段的编码方式自动切换为PLAIN,字典过滤失效。因此为了避免字典过滤失效,可以把parquet block的大小调小,具体可以通过以下参数配置:
set parquet_file_size=128m
测试环境
1个主节点,7个工作节点,工作节点配置如下:
• 2个10 Core CPU
• 256GB内存,分给Impala 120GB
• 12块4TB SATA硬盘
• 1Gb网络
操作系统是CentOS 6.5
Hadoop版本是CDH 5.12/Impala 2.9
测试用例
本次测试采用一天的呼叫详单记录(Call Detail Record),总计37.2亿条记录,270GB数据(压缩后)。呼叫详单记录有20+字段,其中最主要的查询字段包括:
• 主叫号码 calling_num
• 被叫号码 called_num
• 主叫卡号 calling_imsi
• 主叫设备号 calling_imei
• 接入基站 base_station
• 呼叫日期 calling_date
本次测试用例分两组,共12个查询。第一组是明细查询,第二组是简单的汇总查询。具体用例描述如下:
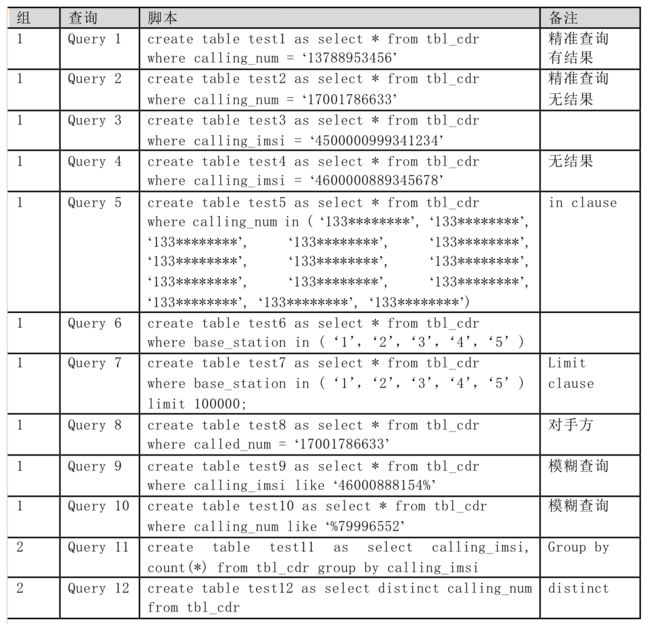
测试结果
本次测试共运行4个批次,分别为:baseline, sort-128, sort-64,sort-32。
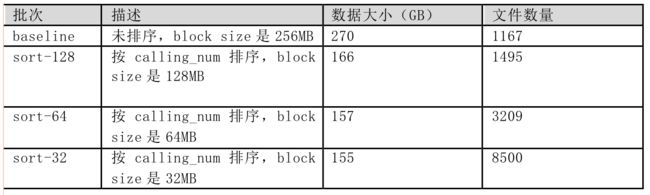
我们注意到,当数据按主叫号码排序后,由于压缩比更高,数据大小相比未排序前减少了将近50%,同时,由于block size变小,最终生成的parquet文件数量增多。
分组1的测试结果如下:

分组2的测试结果如下:

总结
min/max过滤对于排序字段的查询性能有显著的提升:例如对于排序字段(calling_num)的单一条件查询(Query 1, 2),sort-128平均提升了22.6倍,sort-64平均提升了26.3倍。
字典过滤在block size较小的情况下对查询性能有显著的提升:例如对于非排序字段(calling_imsi, base_station,called_num)的查询(Query 3,4,6,7,8,9), sort-128平均提升了2.4倍,sort-64平均提升了3.6倍,sort-32平均提升了4.9倍。
对于简单的汇总查询,改变block size并不会对性能有太大的影响,事实上,由于排序后压缩比变大,实际性能得到了提升。