深度学习:神经网络neural network
http://blog.csdn.net/pipisorry/article/details/70919374
神经网络
一般有前馈神经网络FFNN模型(feedforward neural network),隐层多的可以叫深度神经网络DNN(deep nn)。
固定基函数的线性组合构成的回归模型和分类模型。我们看到,这些模型具有一些有用的分析性质和计算性质,但是它们的实际应用被维数灾难问题限制了。为了将这些模型应用于大规模的问题,有必要根据数据调节基函数。一种方法是事先固定基函数的数量,但是允许基函数可调节。换句话说,就是使用参数形式的基函数,这些参数可以在训练阶段调节。在模式识别中,这种类型的最成功的模型时前馈神经网络,也被称为 深度前馈网络,或者多层感知器(multilayer perceptron)。
回归的线性模型和分类的线性模型基于固定⾮线性基函数ϕj(x)的线性组合,形式为

其中f()在分类问题中是⼀个⾮线性激活函数,在回归问题中为恒等函数。
神经网络的⽬标是推广这个模型,使得基函数ϕj(x)依赖于参数,从⽽能够让这些参数以及系数fwjg能够在训练阶段调节。当然,有许多种⽅法构造参数化的⾮线性基函数。
神经网络使⽤与公式(5.1)形式相同的基函数,即每个基函数本⾝是输⼊的线性组合的⾮线性函数,其中线性组合的系数是可调节参数。
神经网络的表示
Terminology术语:
weights: the same thing as parameters of the model.
the hidden layer: are values you don't get to observe in the training set.
单个神经元的神经网络表示
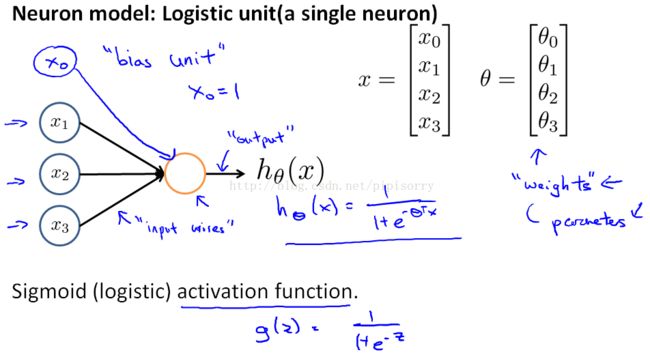
单个神经元的神经网络就是logistic regression。
多个神经元的神经网络

神经网络的前向推导
通过前向推导,推导出神经网络模型hypotheses的数学表示。
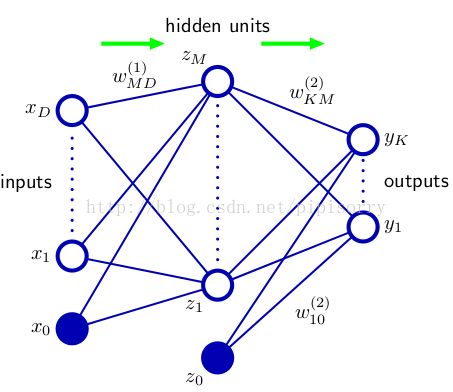

图:一般化的多层多类输出的神经网络
隐层
激活( activation )a j
额外的输入变量 x 0 的值被限制为 x 0 = 1

在一个一般的前馈网络中,每个单元都会计算输入的一个加权和,形式为

使用一个可微的非线性激活函数( activation function ) h(·) 进行变换,可得激活值
![]()
Note: 每个权重会指定两个变量如何相互作用。我们需要在各种条件下观察这两个变量才能良好地拟合权重(所以深度学习一般需要大数据量才能训练好)。而每个偏置仅控制一个单变量。
输出层
对于多个二元分类问题,每个输出单元激活使用 logisticsigmoid 函数进行变换,即
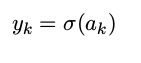
多类multi-class:使用softmax函数

多标签multi-label:每个节点使用一个sigmoid函数
整体的网络函数

神经网络相当于定义了一个很复杂的函数,将x映射到y。an artificial neural network defines a function h that maps your x's input values to hopefully to some space and provisions y? And these hypotheses after parametrized by parameters that denoting with a capital θ so that as we be vary θ we get different hypotheses.So we get different functions mapping say from x to y.
神经网络自学习features

遮住左部:单个神经元是logstic regression,原来的featrues是x,现在加了多层以后features就变换成了更加复杂的a,也就是神经网络学习自己的features来feed into the logistic regression。what this neural network is doing is just like logistic regression, except that rather than using the original features x,is using these new features a.
某小皮
梯度下降最优化

(1)BP算法通过链式法则计算出每一层参数的梯度,使用梯度下降的算法进行损失函数的优化;
(2)由于损失函数是非凸的,所以梯度下降算法并不能保证得到最优解,然而在实际应用中,使用随机梯度下降(stochastic gradient descent,SGD)算法可以得到很好的效果;这里的随机指的是每次进行参数迭代时,随机选取部分样本(也就是一个batch)进行优化计算。
误差反向传播:bp算法
针对一组独立同分布的数据的最大似然方法定义的误差函数,由若干项的求和式组成,每一项对应于训练集的一个数据点,即

我们要考虑的是计算 ∇E n (w) 的问题。这可以直接使用顺序优化的方法计算,或者使用批处理方法在训练集上进行累加。
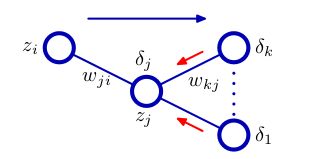
计算En关于权值wji的导数
我们注意到 En 只通过单元 j 的经过求和之后的输入 a j 对权值 w ji 产生依赖

其中误差( error )δ定义为
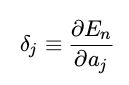
后面一项直接求解为
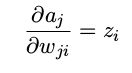
为了计算隐含单元的 δ 值,我们再次使用偏导数的链式法则
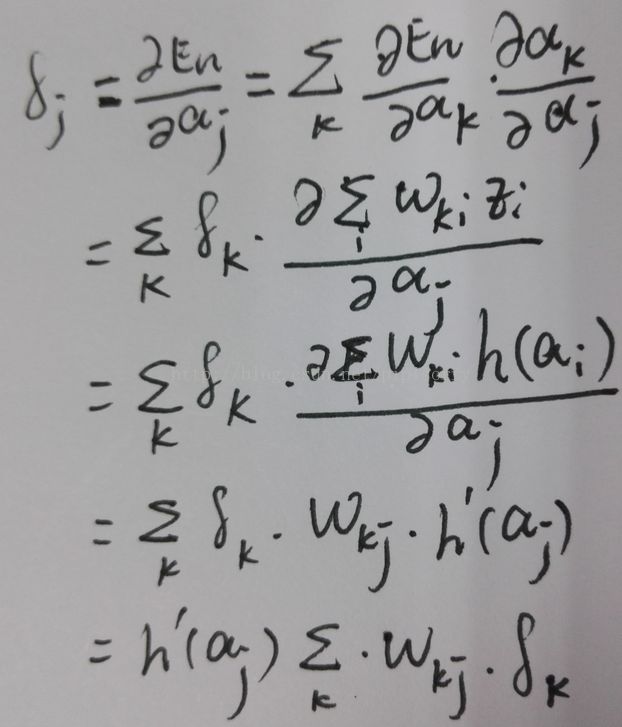
即

其中最后一层δ的求导为

如果使用标准链接函数作为输出单元的激活函数,且使用平方误差,那么对于输出单元,我们就有 δ k = y k − t k。
Note:bias单元: 反向传播时也可以用到bias单元Depending on how you define the back propagation algorithm or depending on how you implement it,you may end up implementing something to compute delta values for these bias units as well. The bias unit is always output the values plus one and they are just what they are and there's no way for us to change the value and so, we just discard them because they don't end up being part of the calculation needed to compute the derivatives.
总误差函数 E 的导数可以通过下面的方式得到:对于训练集里的每个模式,重复上面的步骤,然后对所有的模式求和,即

[反向传播算法可视化]
某小皮
神经网络实现要注意的问题
神经网络的选择
下表列出了各种不同的问题和每种问题最适用的神经网络
| 数据类型 | 应用案例 | 输入 | 变换 | 神经网络 |
|---|---|---|---|---|
| 文本 | 情感分析 | 词向量 | 高斯修正 | RNTN或DBN(采用移动窗口) |
| 文本 | 命名实体识别 | 词向量 | 高斯修正 | RNTN或DBN(采用移动窗口) |
| 文本 | 词性标注 | 词向量 | 高斯修正 | RNTN或DBN(采用移动窗口) |
| 文本 | 词性标注 | 词向量 | 高斯修正 | RNTN或DBN(采用移动窗口) |
| 文本 | 语义角色标记 | 词向量 | 高斯修正 | RNTN或DBN(采用移动窗口) |
| 文档 | 主题建模/语义哈希(无监督) | 词频概率 | 可为二进制 | 深度自动编码器(包装一个DBN或SDA) |
| 文档 | 文档分类(有监督) | TF-IDF(或词频概率) | 二进制 | 深度置信网络、堆叠式降噪自动编码器 |
| 图像 | 图像识别 | 二进制 | 二进制(可见及隐藏层) | 深度置信网络 |
| 图像 | 图像识别 | 连续 | 高斯修正 | 深度置信网络 |
| 图像 | 多对象识别 | N/A | 高斯修正 | 卷积网络、RNTN(图像向量化) |
| 图像 | 图像搜索/语义哈希 | N/A | 高斯修正 | 深度自动编码器(包装一个DBN) |
| 声音 | 语音识别 | N/A | 高斯修正 | 循环网络 |
| 声音 | 语音识别 | N/A | 高斯修正 | 移动窗口,DBN或卷积网络 |
| 时间序列 | 预测分析 | N/A | 高斯修正 | 循环网络 |
| 时间序列 | 预测分析 | N/A | 高斯修正 | 移动窗口,DBN或卷积网络 |
注:高斯修正 = Gaussian Rectified | 语义哈希 = Semantic Hashing
神经网络的架构设计
前馈神经网络的网络架构network architectures和选择
架构(architecture)一词是指网络的整体结构:它应该具有多少单元,以及这些单元应该如何连接。
大多数神经网络被组织成称为层的单元组。大多数神经网络架构将这些层布置成链式结构,其中每一层都是前一层的函数。在这些链式架构中,主要的架构考虑是选择网络的深度和每一层的宽度。即使只有一个隐藏层的网络也足够适应训练集。更深层的网络通常能够对每一层使用更少的单元数和更少的参数,并且经常容易泛化到测试集,但是通常也更难以优化。对于一个具体的任务,理想的网络架构必须通过实验,观测在验证集上的误差来找到。
万能近似定理(universal approximation theorem)(Hornik et al., 1989;Cybenko, 1989) 表明,一个前馈神经网络如果具有线性输出层和至少一层具有任何一种 ‘‘挤压’’ 性质的激活函数(例如logistic sigmoid激活函数;后证明更广泛类别的激活函数也是适用的,其中就包括现在常用的整流线性单元)隐藏层,只要给予网络足够数量的隐藏单元,它可以以任意的精度来近似任何从一个有限维空间到另一个有限维空间的 Borel 可测函数。神经网络也可以近似从任何有限维离散空间映射到另一个的任意函数。
具有单层的前馈网络足以表示任何函数,但是网络层可能大得不可实现,并且可能无法正确地学习和泛化。在很多情况下,使用更深的模型能够减少表示期望函数所需的单元的数量,并且可以减少泛化误差。在很多情况下,浅层模型所需的隐藏单元的数量是 n 的指数级。在通常的理解中,一个足够宽的网络,是能够拟合任何函数的。 而一个深层网络,则能够用更少的参数来拟合该函数,因为深层的神经元可以获取比浅层神经元更复杂的特征表示。
使用深层模型表达出了对模型可以学习的函数空间的有用偏好。具体来说,它表达了一种信念,即该函数应该由许多更简单的函数复合在一起而得到。根据经验,更深的模型似乎确实在广泛的任务中泛化得更好。使用深层架构确实在模型学习的函数空间上表示了一个有用的先验。
[How to Choose a Neural Network][深度学习]
如何优化隐层数和隐层结点数?
隐层数和隐层节点数问题的讨论
隐层数
一般认为,增加隐层数可以降低网络误差(不一定能有效降低),提高精度,但也使网络复杂化,从而增加了网络的训练时间和出现“过拟合”的倾向。一般来讲应设计神经网络应优先考虑3层网络(即有1个隐层),因为大部分情况下都够用了。理论上说,一个有两个隐藏层的前馈神经网络可以表示任意的非线性决策边界。
一般地,靠增加隐层节点数来获得较低的误差,其训练效果要比增加隐层数更容易实现。对于没有隐层的神经网络模型,实际上就是一个线性或非线性(取决于输出层采用线性或非线性转换函数型式)回归模型。
隐层节点数
在BP 网络中,隐层节点数的选择非常重要,它不仅对建立的神经网络模型的性能影响很大,而且是训练时出现“过拟合”的直接原因,但是目前理论上还没有一种科学的和普遍的确定方法。 目前多数文献中提出的确定隐层节点数的计算公式都是针对训练样本任意多的情况,而且多数是针对最不利的情况,一般工程实践中很难满足,不宜采用。事实上,各种计算公式得到的隐层节点数有时相差几倍甚至上百倍。为尽可能避免训练时出现“过拟合”现象,保证足够高的网络性能和泛化能力,确定隐层节点数的最基本原则是:在满足精度要求的前提下取尽可能紧凑的结构,即取尽可能少的隐层节点数。研究表明,隐层节点数不仅与输入/输出层的节点数有关,更与需解决的问题的复杂程度和转换函数的型式以及样本数据的特性等因素有关。
隐层节点数和训练样本数必须满足的条件:(1)隐层节点数必须小于N-1(其中N为训练样本数),否则,网络模型的系统误差与训练样本的特性无关而趋于零,即建立的网络模型没有泛化能力,也没有任何实用价值。同理可推得:输入层的节点数(变量数)必须小于N-1。(2) 训练样本数必须多于网络模型的连接权数,一般为2~10倍,否则,样本必须分成几部分并采用“轮流训练”的方法才可能得到可靠的神经网络模型。
总之,若隐层节点数太少,网络可能根本不能训练或网络性能很差,网络不能具有必要的学习能力和信息处理能力;若隐层节点数太多,虽然可使网络的系统误差减小,但一方面大大增加网络结构的复杂性(这一点对硬件实现的网络尤其重要),使网络训练时间延长,另一方面,训练容易陷入局部极小点而得不到最优点,也是训练时出现“过拟合”的内在原因。因此,合理隐层节点数应在综合考虑网络结构复杂程度和误差大小的情况下用节点删除法和扩张法确定。
不过如果训练一次成本太高,可以试试下面几种方法:
方法1:
fangfaGorman指出隐层结点数s与模式数N的关系是:s=log2N;
方法二:
Kolmogorov定理表明,隐层结点数s=2n+1(n为输入层结点数);
方法三:
s=sqrt(0.43mn+0.12nn+2.54m+0.77n+0.35)+0.51
(m是输入层的个数,n是输出层的个数)。
方法四:
假设输入层的节点数是Nx,输出层的节点数Ny、,那么每个隐藏层中的节点数Nh一般在Nx和Ny之间,有人推荐√NxNy,也有人推荐
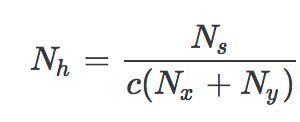
其中Ns是样本的数量,c是一个常数,通常选择个位数。当然以上都是根据经验而来的,具体怎么选,还需要针对具体问题进行分析然后做交叉验证。
其它:

Gradient Checking梯度检查
使用梯度下降时可能出现的问题
即使bp算法代码写错了,cost func也可能在每次梯度迭代时减小。Your cost function J of theta may end up decreasing on every iteration of gradient descent, but this could pull through even though there might be some bug in your implementation of back prop. So it looks like J of theta is decreasing, but you might just wind up with a neural network that has a higher level of error than you would with a bug-free implementation and you might just not know that there was this subtle bug that's giving you this performance.
梯度的数值估计Numerical estimation of gradients
用梯度的估计值来检测BP算法计算得到的D向量是否正确。
θ为一个实数时
Note:
1 don't use ε that's too, too small because then you might run into numerical problems.
2 二边差分two-sided difference估计更准确一点点,所以不用单边差分one-sided difference。
θ是一个向量参数时

Note: 检查完没问题就关掉gradient checking。numeric code gradient checking code is a very computationally expensive, that's a very slow way to try to approximate the derivative. Back prop is a much more computationally efficient way of computing the derivatives. So once you've verified that your implementation of back-propagation is correct, you should turn off gradient checking.
随机初始化Random Initialization
权重初始化:一般初始化为接近0的很小的随机数。一般用高斯分布或者uniform分布。但是这样的分布会导致输出的方差随着输入单元个数而变大,因此需要除以fan in(输入个数的平方根)或者一般使高斯分布的标准差为std_func = lambda x: math.sqrt(2.0 / float(input_units))。
神经网络中θ初始化0会带来symmetric weights问题:不要全部初始化为0,这样会导致大部分的deltaw都一样。都初始化0最后重新得到的值又会是一样的(相同颜色线条标注的),即使不再是0。然后计算得到的两个a也是相同的,然后delta相同,然后D相同,一直循环这种相同。这就意味着神经网络不能计算出非常有趣的函数,所有的hidden units都在计算完全一样的feature,都在计算完全一样的关于input的函数,这就成了一个高度冗余的表达redundant representation.
Cost function的选择和对比
分类问题一般选择交叉熵

Note: we don't sum over the terms corresponding to these bias values。
回归问题一般选择平方损失。
神经网络的代码实现
[pybrain库调用实现]
[Python下(只)用numpy写神经网络Neural network with numpy]
[tensorflow中实现][(Python/Theano)28行代码的神经网络《A Neural Network in 28 Lines of Theano | codekansas》by bkbolte18]
[tensorflow Module: tf.contrib.layers ][tensorflow tf.contrib.learn.DNNClassifier ]
某小皮
神经网络的评价
优点:分类的准确度高,并行分布处理能力强,分布存储及学习能力强,对噪声神经有较强的鲁棒性和容错能力,能充分逼近复杂的非线性关系,具备联想记忆的功能等。特别重要的是,神经网络可以用来提取特征,这是许多其他机器学习方法所不具备的能力。
- 网络实质上实现了一个从输入到输出的映射功能,而数学理论已证明它具有实现任何复杂非线性映射的功能。这使得它特别适合于求解内部机制复杂的问题;
- 网络能通过学习带正确答案的实例集自动提取“合理的”求解规则,即具有自学习能力;
- 网络具有一定的推广、概括能力。
缺陷:神经网络需要大量的参数,如网络拓扑结构、权值和阈值的初始值;不能观察之间的学习过程,输出结果难以解释,会影响到结果的可信度和可接受程度;学习时间过长,甚至可能达不到学习的目的。
-
BP算法的学习速度很慢,其原因主要有:
- 由于BP算法本质上为梯度下降法,而它所要优化的目标函数又非常复杂,因此,必然会出现“锯齿形现象”,这使得BP算法低效;
- 存在麻痹现象,由于优化的目标函数很复杂,它必然会在神经元输出接近0或1的情况下,出现一些平坦区,在这些区域内,权值误差改变很小,使训练过程几乎停顿;
- 为了使网络执行BP算法,不能用传统的一维搜索法求每次迭代的步长,而必须把步长的更新规则预先赋予网络,这种方法将引起算法低效。
-
网络训练失败的可能性较大,其原因有:
- 从数学角度看,BP算法为一种局部搜索的优化方法,但它要解决的问题为求解复杂非线性函数的全局极值,因此,算法很有可能陷入局部极值,使训练失败;
- 网络的逼近、推广能力同学习样本的典型性密切相关,而从问题中选取典型样本实例组成训练集是一个很困难的问题。
- 难以解决应用问题的实例规模和网络规模间的矛盾。这涉及到网络容量的可能性与可行性的关系问题,即学习复杂性问题;
- 网络结构的选择尚无一种统一而完整的理论指导,一般只能由经验选定。为此,有人称神经网络的结构选择为一种艺术。而网络的结构直接影响网络的逼近能力及推广性质。因此,应用中如何选择合适的网络结构是一个重要的问题;
- 新加入的样本要影响已学习成功的网络,而且刻画每个输入样本的特征的数目也必须相同;
- 网络的预测能力(也称泛化能力、推广能力)与训练能力(也称逼近能力、学习能力)的矛盾。一般情况下,训练能力差时,预测能力也差,并且一定程度上,随训练能力地提高,预测能力也提高。但这种趋势有一个极限,当达到此极限时,随训练能力的提高,预测能力反而下降,即出现所谓“过拟合”现象。此时,网络学习了过多的样本细节,而不能反映样本内含的规律
因为神经网络的cost function J(θ)是非凸的non-convex,所以理论上易受极小值的影响,但是不会成大问题。 But it turns out that in practice this is not usually a huge problem and even though we can't guarantee that these algorithms will find a global optimum, usually algorithms like gradient descent will do a very good job minimizing this cost function j of theta and get a very good local minimum.
One figure to get that intuition about what gradient descent for a neural network is doing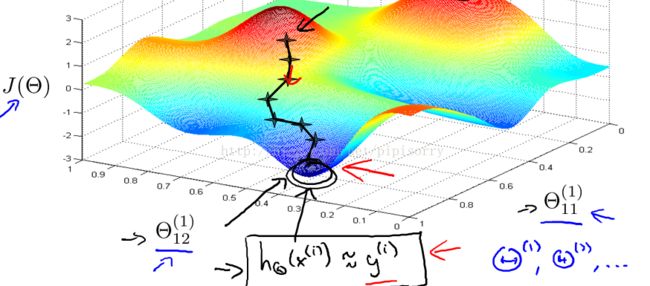
神经网络的改进
cnn, rnn, lstm, attention机制等等。
对于FFNN模型来说,每计算一个样本点,模型信息就丢失,对于相互独立的样本点来说,这样的模型可以起到很好的作用,但是若样本点之间存在关联性,那么将会有信息丢失以至无法很好完成任务;因此,为了对时间进行建模,RNN模型出现。
from: http://blog.csdn.net/pipisorry/article/details/70919374
ref: [PRML]*
[andrew ng machine learning lecture]
[深度学习笔记(七):RNN模型]