【2017CS231n】第九讲:CNN架构
第九讲的概述如下:这一讲就是介绍几个CNN的网络,AlexNet、VGG、GoogleNet、ResNet。

1. AlexNet
第一个在ImageNet中获胜的大型卷积神经网络。
基本结构:卷积层,池化层,归一化,卷积,池化,归一化,最后是一些全连接。
1.1 结构
5层卷积层,3层全连接层。

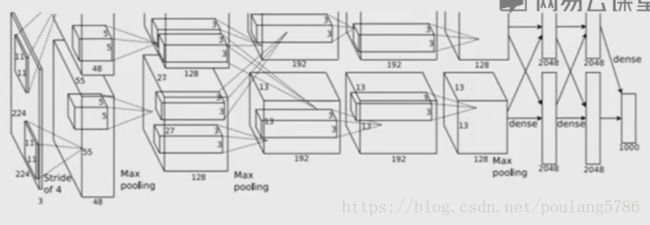
1.2 数据和参数尺寸
1.2.1 第一层输出尺寸
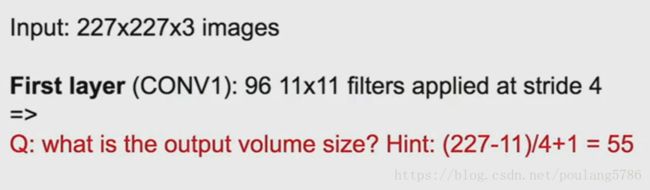
第一层的输出数据大小根据公式计算得55。
1.2.2 整个网路的输出尺寸

整个网络最后的输出是55*55*96。
先根据上面计算的卷积层输出尺寸,得到一层的输出是55*55,因为有96个卷积核,所以整个输出深度是96。则网络最后的输出尺寸是55*55*96
1.2.3 第一层总参数

第一层的参数总数是多少。
每一个卷积核都会处理一个11*11*3的数据(11*11的RGB图像块,所以输入数据的深度是3),所以11*11*3是每个卷积核的参数数量,再乘以卷积核的总数96,得到第一层总参数35000。
1.2.4 池化层输出尺寸

池化层的输出尺寸根据公式计算得27*27,池化层会保留数据深度,因为我们的数据是从卷积层输出,数据深度是96,池化层会保留数据深度,所以池化层的输出尺寸是27*27*96。
1.2.5 池化层参数总数
池化层没有参数。
参数是我们需要训练的权重,在卷积层才有我们需要训练的参数。
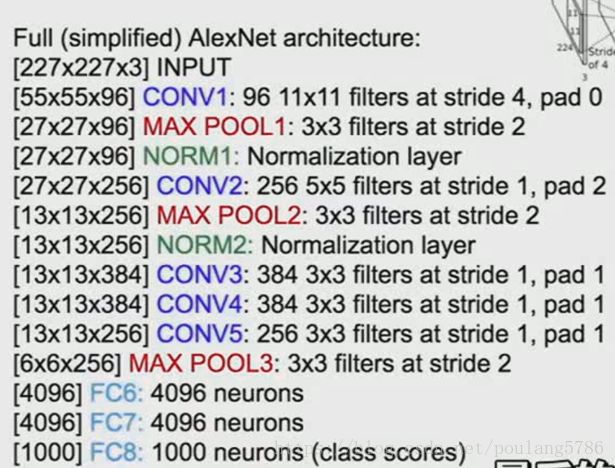
1.2.6 AlexNet总体概述
参数及尺寸:
其他细节:

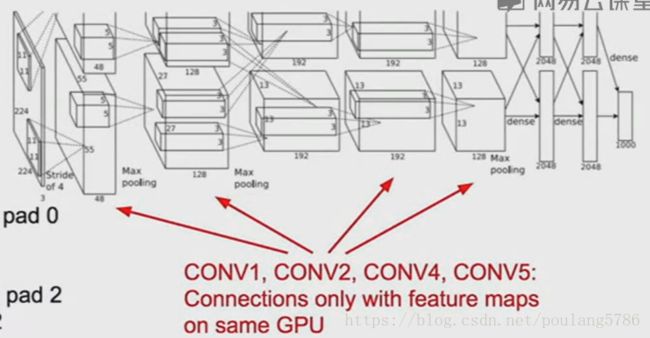
网络分成两部分:
因为受当时GPU运算能力的限制,整个网络被分成两部分,分别在两块GPU上训练。
第一层卷积层分成两个部分,每个部分只有48的深度,每一部分卷积层的特征映射只有一半。
从第三层卷积层到第6,7,8的全连接层,两个GPU互相通信。

2. VGG
2.1 网络特点
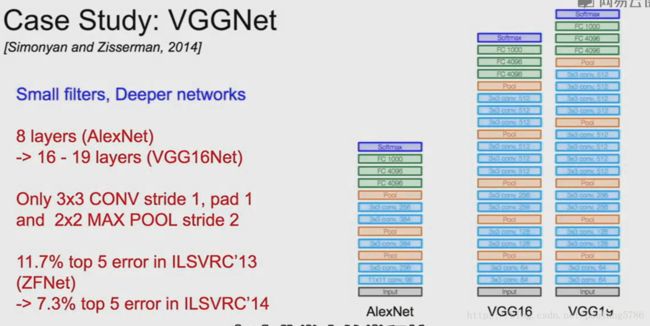
包含很深的网络和很小的卷积核。深度从AlexNet的8层扩展到16到19层,采用3*3的卷积核。
2.2 优点
采用了小的卷积核,具有以下优点:

3*3的卷积核采用步长为1,可以得到跟7*7相同效果的接受域,可以得到比较小的参数量,可以尝试使用更深的网络和更多的卷积核。

3*3卷积核(步长为1)的接受域是多少?
输入的全部区域。

为什么使用更小的卷积核?
更深的网络和更多的非线性和更少的参数(C是通道数)。
2.3 VGG16
VGG16在卷积层需要更多的内存,在全连接层需要更多的参数。
3. GoogleNet
3.1 GoogleNet结构概述
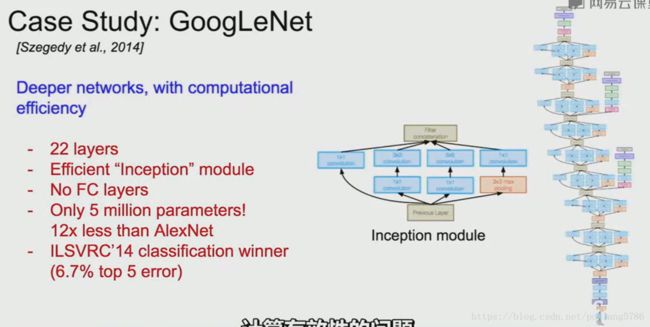
网络总共有22层,有效的计算(采用Inception模块),没有全连接层(减少了很多参数),参数比AlexNet少很多。
3.2 Inception模块

Inception模块:设计一个好的局部网络拓扑结构,有了局部网络拓扑就可以将它视为一个网络,然后将大量局部拓扑堆叠起来。

在这个局部网络中调用Inception模块,对进入相同层的相同输入并行运用不同类别的滤波操作。
我们有来自前面层的输入,然后进行不同的卷积操作(1*1,3*3,5*5)还有池化操作,不同的层得到不同的输出,这些层最后在深度层面上将输出串联在一起。最后得到一个张量输出,张量进入下一层网络。

Inception模块的输入是28*28*256,模块中间是128个1*1的卷积核,192个3*3卷积核,96个5*5卷积核,模块的最后将所有输出联系起来。
Inception模块存在的问题及解决方法:
问题:
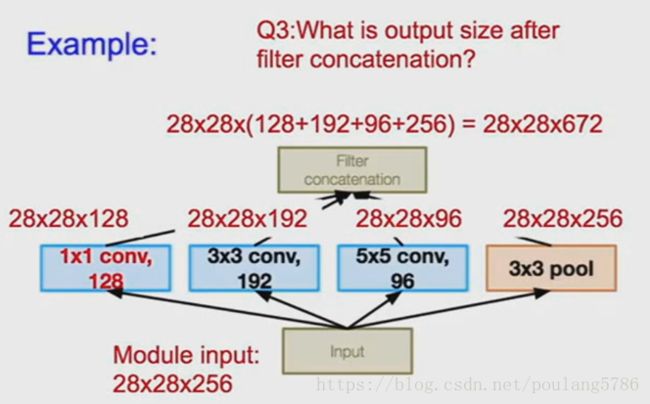
先来看下卷积核串联之后输出的尺寸。
为了保持输入和输出尺寸相同,我们在这里采用了零填充。
Inception模块的输入数据深度是256在这里没有特别的深意,只是上一层的输出深度是256,模块之后的输出深度变成了672。

计算量:
池化层会保留输入数据的深度,所以存在的问题是每一层过后,深度只会增加。
解决方法:
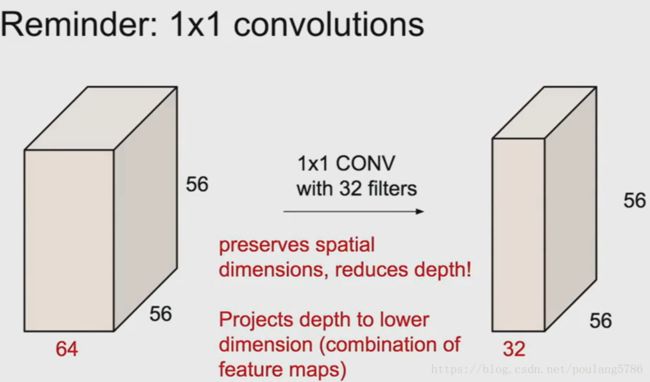
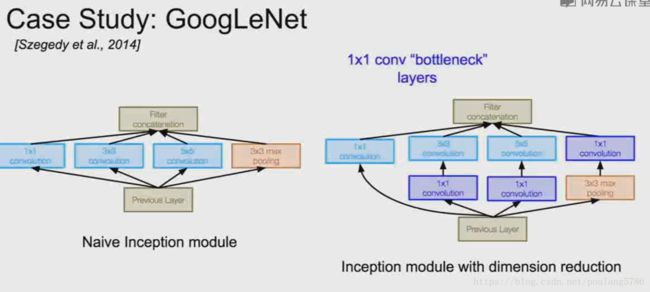
所以在3*3和5*5的卷积层之前,先通过一个1*1的卷积层,在池化层之后也会通过一个额外的1*1卷积层。这些就是添加进来的瓶颈层。
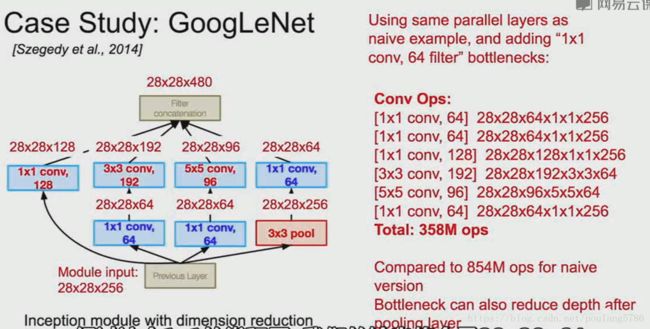
我们输入数据的深度是256,之后的1*1卷积层的数量是64,这样就会降低数据的深度,我们的输出会变成28*28*64。所以进入卷积层的数据深度将会下降。
经过1*1卷积层后会有信息丢失,但是在输入之前我们会使用具有冗余的输入特征映射的线性组合。
3.3 总体架构
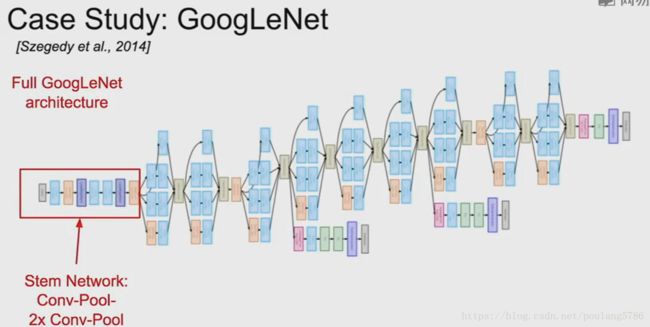
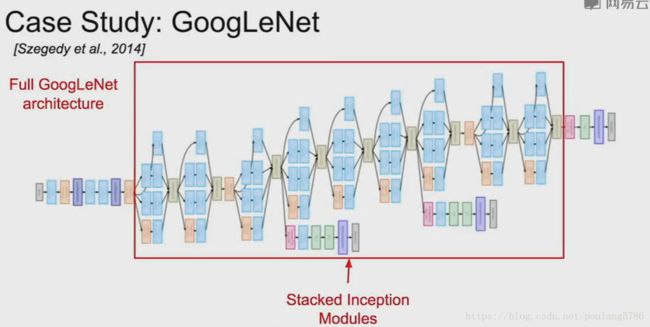
不同的初始化模块都堆叠在一起。
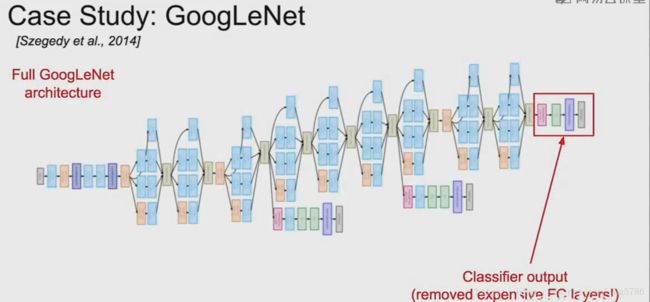
顶部是分类的输出,全连接层已经被移除。
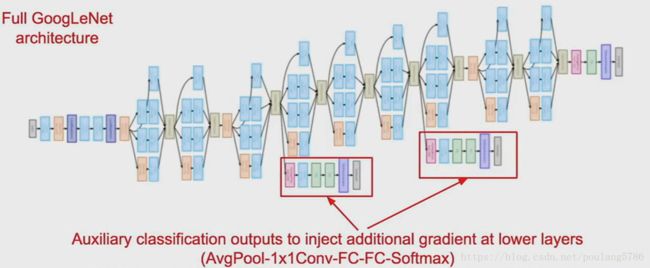
辅助的分类输出。
4. ResNet
4.1 结构概述
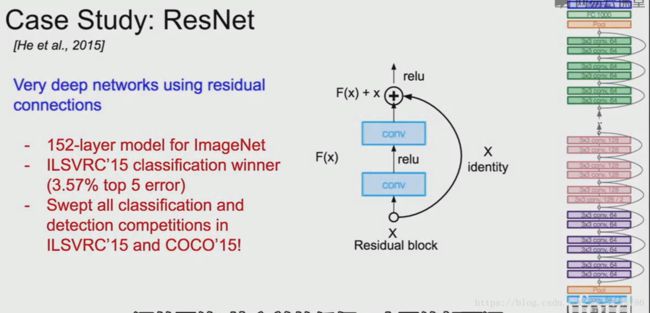
4.2 ResNet和残差连接出现的原因
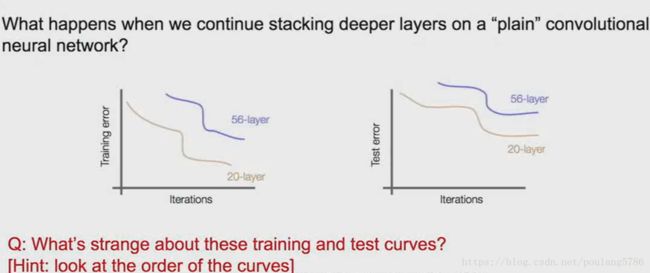
在VGG等网络中,不能仅仅通过堆叠更深的网络来提升效果。
一个56层的网络在训练误差和测试误差表现都不如一个20层的网络,所以这也不是过拟合造成的。

针对这个问题ResNet的创造者假设这是一个优化问题,更深的网络更难优化。
一个较深层的模型至少能跟浅层模型表现的一样好,在较浅模型中通过恒等映射将这些拷贝到剩下的深层中。
4.3 网络特性

不仅仅堆叠这些层,而是每层都学习一些底层映射。使用这些模块尝试拟合残差映射而不是直接映射。
用我们的层取拟合残差H(x)-x,代替H(x)。在模块的最后我们用循环来进行连接,现在我们仅仅是输入并作为一个不变的量进行传递,如果在中间有权重层,去学习X的残差,现在的输出就变成了R(x)+残差。
我们可以认为我们的输出是F(x)+x,F(x)是转换后的结果,x是输入且不变地传递。因为直接学习得到H(x)很难且会得到很深的网络,所以我们现在尝试学习输入x加上一个什么东西或减去什么来得到H(x)。
F(x)是我们说的残差
4.4 结构
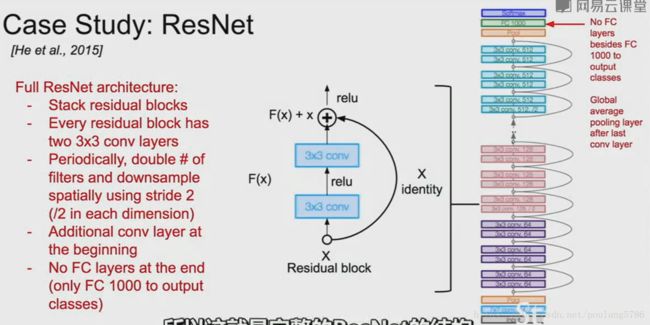
每一个残差模块由两个3*3的卷积层组成,堆叠所有的残差模块,用两倍数量的卷积核,用步长为2的卷积核进行下采样,在网络的最后没有全连接层,只有一个全局的平均池化层。

用瓶颈层降低深度。
在之前有一个1*1*64卷积层降低维度,最后用一个1*1*256卷积层恢复深度。

在实际中训练ResNet。
每个卷积层之后批量正则化。
Xavier初始化。带动量的SGD(随机梯度下降)。