Spark入门学习和调优
Spark运行原理自我理解:
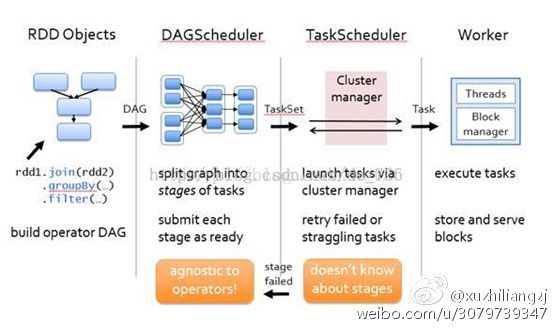
(1) 首先程序有RDD Objects分解为DAG有向无环图
(2) 提交DAGScheduler,根据shuffer将DAG分解为一组taskset,即stages
(3) Taskset提交TaskScheduler,每个taskset在分解为多个task,即一个task就是一个split分区
(4) Task就运行在worker上
Spark运行原理
(1)用户创建SparkContext对象,新创建的SparkContext会根据用户在编程的时候指定的参数或者系统默认的配置连接到ClusterManager。
(2)Cluster Manager会根据用户提交时的设值,(程序占用CPU的个数,内存的信息等等)来为我们具体的本次的程序分配计算资源,启动具体的Executor。Driver会根据用户程序来进行这种调度级别的一种Stage划分,但这边谈的stage的划分是高层调度器,Saprk在具体执行时分为高层调度和底层调度。高层调度是基于RDD的依赖。RDD的产生一般由前面RDD的具体某个操作中产生,第一次也可以从文件系统中读取一个内容就自动产生,也就是SparkContxt中产生,而后面总是依赖于前面的RDD产生,构成了继承和依赖关系。如果说遇见宽依赖的时候,就划分成不同的Stage,每一个Stage会有一组完全相同的任务组成,这些任务分别作用待处理数据的不同分区。
(3)在Stage划分完成和Task具体创建之后,Driver端会向具体的Executor发送具体的任务,Executor收到任务就会下载Task运行时依赖的库,包,准备好Task的
执行环境之后开始执行Task,执行时就是线程池中的线程执行的。
(4)在执行Task的过程中,会把执行状态汇报给Driver。Driver会根据收到的Task运行状态来处理不同的状态更新。Task本身根据我们之前不同的Stage划分,会把Task分为两种类型,一种是ShuffleMapTask,这个是对数据进行Shuffle,Shuffle的结果会保存在Executor所在节点的本地文件系统中;另外一种是ResultTask,就是最后一个Stage,负责生成结果数据。Driver会不断地调用Task,将Task发送到Executor中执行,所有的Task都正确执行,或者超过执行次数的限制没有成功是会停止。正确执行了就会进入下一个Stage。高层调度器DAGScheduler会帮助我们进行一定次数的重试,如果我们重试一定次数还没成功,那整个作业失败。
===================================================================================================================================
spark是一个分布式,基于内存的适合迭代计算的大数据计算框架。
基于内存,在一些情况下也会基于磁盘,spark计算时会优先考虑把数据放到内存中,应为数据在内存中就具有更好的数据本地性;如果内存放不下时,也会将少量数据放到磁盘上,它的计算既可以基于内存也可以基于磁盘,它适于任何规模的数据的计算。
Spark想用一个技术堆栈解决所有的大数据计算问题。大数据计算问题主要包括:交互式查询(基于shell和sql)、流处理(数据流入后直接进行处理)和批处理(基于Spark内核进行的一个RDD级别的编程,同时还包含图计算、机器学习的内容)。目前Spark支持的5中计算范式:流处理、SQL、R、图计算、机器学期等。
我们可以从三个方面去理解Spark,
1. 分布式
在生产环境下,是在分布式多台机器下去运行的。它会有几个特征:(1)我们的Spark会有一个Driver端,也就是所谓的客户端,我们自己编写的程序,要提交给集群;而在集群中有很多机器,
整作业的运行实际上是运行在分布式的节点(默认一台机器是一个节点)中的。
Spark程序提交到Spark集群上进行运行,运行时要处理一批数据,由于它是分布式的,所以运行时不同的节点会处理一部分数据。各个部分节点处理数据互不干扰。所以,在做分布式时,就可以并行化。所以他就可以处理数据更快。
1. (主要)基于内存
Spark优先考虑使用内存,其实是是对计算机资源最大化利用的一个物理基石。在内存中可以放下时,最先考虑到内存中,放不下时放在磁盘上。
2. 擅长迭代式计算
擅长迭代式计算是Spark的真正精髓。在实际如果要对数据进行稍有价值的挖掘或是对数据进行稍有复杂度的一些挖掘,一定是要对数据进行具有多步奏的计算。这时候就要用到迭代式的计算,而Spark天生就是适用于分布式的主要基于内存的迭代式计算。Spark基于磁盘的迭代式计算会比hadoop快10x倍,而Spark基于内存的迭代式计算要比hadoop快100x倍。这里要提一下,当作业计算完第一个阶段,然后移动另一个节点中进行计算,也就是所谓为的shuffle,而且可以反复的shuffle,并形成一个链条,这就是迭代。
我们写好的本地程序,提交到Driver上,他会提供一个接口即SparkContext,然后Driver会将我们的程序提交到集群上,各个work会并行计算处理我们的程序。Hadoop和Spark最根本的不同是迭代模型的不同,hadoop主要是两步map阶段和reduce阶段,进行完计算之后,就没有以后的阶段了,而Spark可以在计算完第一个阶段后,进行第二阶段计算,第二阶段计算完后进行第三阶段…也就是说,我们进行完一个阶段后,后面可以有很多阶段的计算来完成任务,而不是hadoop只有map和reduce两个阶段这么僵硬。由于它的这种迭代式模型使得Spark更加强大和灵活。构造复杂算法时也更加容易。
在读取文件时,hadoop每次都是都是读取磁盘和写入磁盘,而Spark是基于内存的,大部分中间计算结果是保存在内存中,下一次计算是基于内存的计算结果的,所以节省了读取磁盘的时间。
Spark的高速运行除了基于内存,主要原因还是因为他的调度器(基于DAG之上的调度器,有高层调度器和底层调度器和容错)。
我们在本地开发好Spark文件,具体在单独的机器上提交程序,如上图圆圈中的都是Driver级别的,这些都是驱动整个程序运行的,Spark程序是会提交到集群中去运行的,他具体运行时是要靠Driver驱动来运行的。而具体节点(如Spark worker)是一各个计算的节点work,而在计算时,要读取具体的数据,读取数据可以从HDFS,HBase,Hive或是传统的DB来源读取数据,处理数据时主要是利用线程池、线程复用的方式,处理完成后,数据可以放在HDFS,HBase,Hive,DB,还可以直接返回直接给客户端,也就是正在运行程序的机器上的进程。
RDD
RDD:弹性分布式数据起,本生是对分布式计算一个抽象。首先它是一个数据集(DataSet),它会代表我们要处理的数据,但是它是分布式的,也就是分成很多分片,分布在几百台或上千台机器上的。在每个节点上存储时默认这些数据都是放在内存中的。RDD代表了一些列的分片,而这些分片是在具体的不同节点上存储,默认优先在内存中存储,如果内存放不下,他会把一部分放在磁盘上进行存储,而这些对于我们用户来说是透明的。我们只需要针对RDD进行计算和处理就行了。RDD本生会自动进行内存和磁盘的权衡和切换,这就是弹性之一,其次,它基于Lineage的高效容错(他会更具血统继承关系来恢复运行出错情况,可以从上一个步奏进行重新计算,而不会从第一个步奏重新计算,效率非常高,以为不需要重头开始重新计算),第三,task如果失败,会自动进行特定次数的重试(默认4次),第四,Stage如果失败会自动进行特定次数的重试(默认3次,只计算失败的分片)。
下面我们讲下缓存的时机:
(1)计算特别耗时
(2)计算链条已经很长了
(3)Shuffle之后(冲其他地方抓数据后)
(4)ChechPoint之前(chechPoint是当前作业执行后,再触发一个作业)
RDD本生会有一些列的数据分片,一个RDD在逻辑上就代表了顶层的一个文件或文件夹,但实际上它是按照分区(partition)分为多个分区,分区会放在Spark集群中不同的机器的节点上。而RDD本生又包含了对函数的计算。
==========================================================================================
Spark调优
基本概念和原则
首先,要搞清楚Spark的几个基本概念和原则,否则系统的性能调优无从谈起:
- 每一台host上面可以并行N个worker,每一个worker下面可以并行M个executor,task们会被分配到executor上面 去执行。Stage指的是一组并行运行的task,stage内部是不能出现shuffle的,因为shuffle的就像篱笆一样阻止了并行task的运行,遇到shuffle就意味着到了stage的边界。
- CPU的core数量,每个executor可以占用一个或多个core,可以通过观察CPU的使用率变化来了解计算资源的使用情况,例如,很 常见的一种浪费是一个executor占用了多个core,但是总的CPU使用率却不高(因为一个executor并不总能充分利用多核的能力),这个时 候可以考虑让么个executor占用更少的core,同时worker下面增加更多的executor,或者一台host上面增加更多的worker来 增加并行执行的executor的数量,从而增加CPU利用率。但是增加executor的时候需要考虑好内存消耗,因为一台机器的内存分配给越多的executor,每个executor的内存就越小,以致出现过多的数据spill over甚至out of memory的情况。
- partition和parallelism,partition指的就是数据分片的数量,每一次task只能处理一个partition的数据,这个值太小了会导致每片数据量太大,导致内存压力,或者诸多executor的计算能力无法利用充分;但是如果太大了则会导致分片太多,执行效率降低。 在执行action类型操作的时候(比如各种reduce操作),partition的数量会选择parent RDD中最大的那一个。而parallelism则指的是在RDD进行reduce类操作的时候,默认返回数据的paritition数量(而在进行 map类操作的时候,partition数量通常取自parent RDD中较大的一个,而且也不会涉及shuffle,因此这个parallelism的参数没有影响)。所以说,这两个概念密切相关,都是涉及到数据分片 的,作用方式其实是统一的。通过spark.default.parallelism可以设置默认的分片数量,而很多RDD的操作都可以指定一个 partition参数来显式控制具体的分片数量。
- 上面这两条原理上看起来很简单,但是却非常重要,根据硬件和任务的情况选择不同的取值。想要取一个放之四海而皆准的配置是不现实的。看这样几个例 子:(1)实践中跑的EMR Spark job,有的特别慢,查看CPU利用率很低,我们就尝试减少每个executor占用CPU core的数量,增加并行的executor数量,同时配合增加分片,整体上增加了CPU的利用率,加快数据处理速度。(2)发现某job很容易发生内存 溢出,我们就增大分片数量,从而减少了每片数据的规模,同时还减少并行的executor数量,这样相同的内存资源分配给数量更少的executor,相 当于增加了每个task的内存分配,这样运行速度可能慢了些,但是总比OOM强。(3)数据量特别少,有大量的小文件生成,就减少文件分片,没必要创建那 么多task,这种情况,如果只是最原始的input比较小,一般都能被注意到;但是,如果是在运算过程中,比如应用某个reduceBy或者某个 filter以后,数据大量减少,这种低效情况就很少被留意到。
- 最后再补充一点,随着参数和配置的变化,性能的瓶颈是变化的,在分析问题的时候不要忘记。例如在每台机器上部署的executor数量增加的时 候,性能一开始是增加的,同时也观察到CPU的平均使用率在增加;但是随着单台机器上的executor越来越多,性能下降了,因为随着executor 的数量增加,被分配到每个executor的内存数量减小,在内存里直接操作的越来越少,spill over到磁盘上的数据越来越多,自然性能就变差了。
-
下面给这样一个直观的例子,当前总的cpu利用率并不高:
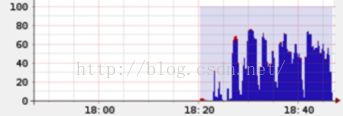
但是经过根据上述原则的的调整之后,可以显著发现cpu总利用率增加了:
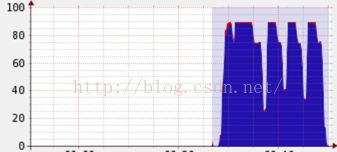
其次,涉及性能调优我们经常要改配置,在Spark里面有三种常见的配置方式,虽然有些参数的配置是可以互相替代,但是作为最佳实践,还是需要遵循不同的情形下使用不同的配置:
- 设置环境变量,这种方式主要用于和环境、硬件相关的配置;
- 命令行参数,这种方式主要用于不同次的运行会发生变化的参数,用双横线开头;
- 代码里面(比如Scala)显式设置(SparkConf对象),这种配置通常是application级别的配置,一般不改变。
-
举一个配置的具体例子。slave、worker和executor之间的比例调整。我们经常需要调整并行的executor的数量,那么简单说有两种方式:
- 1. 每个worker内始终跑一个executor,但是调整单台slave上并行的worker的数量。比如,SPARK_WORKER_INSTANCES可以设置每个slave的worker的数量,但是在改变这个参数的时候,比如改成2,一定要相应设置SPARK_WORKER_CORES的值,让每个worker使用原有一半的core,这样才能让两个worker一同工作;
- 2. 每台slave内始终只部署一个worker,但是worker内部署多个executor。我们是在YARN框架下采用这个调整来实现executor数量改变的,一种典型办法是,一个host只跑一个worker,然后配置spark.executor.cores为host上CPU core的N分之一,同时也设置spark.executor.memory为host上分配给Spark计算内存的N分之一,这样这个host上就能够启动N个executor。
-
有的配置在不同的MR框架/工具下是不一样的,比如YARN下有的参数的默认取值就不同,这点需要注意。
明确这些基础的事情以后,再来一项一项看性能调优的要点。
内存
Memory Tuning,Java对象会占用原始数据2~5倍甚至更多的空间。最好的检测对象内存消耗的办法就是创建RDD,然后放到cache里面去,然后在UI 上面看storage的变化;当然也可以使用SizeEstimator来估算。使用-XX:+UseCompressedOops选项可以压缩指针(8 字节变成4字节)。在调用collect等等API的时候也要小心——大块数据往内存拷贝的时候心里要清楚。内存要留一些给操作系统,比如20%,这里面 也包括了OS的buffer cache,如果预留得太少了,会见到这样的错误:
“Required executor memory (235520+23552 MB) is above the max threshold (241664 MB) of this cluster! Please increase the value of ‘yarn.scheduler.maximum-allocation-mb’.”
或者干脆就没有这样的错误,但是依然有因为内存不足导致的问题,有的会有警告,比如这个:
“16/01/13 23:54:48 WARN scheduler.TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient memory”
有的时候连这样的日志都见不到,而是见到一些不清楚原因的executor丢失信息:
“Exception in thread “main” org.apache.spark.SparkException: Job aborted due to stage failure: Task 12 in stage 17.0 failed 4 times, most recent failure: Lost task 12.3 in stage 17.0 (TID 1257, ip-10-184-192-56.ec2.internal): ExecutorLostFailure (executor 79 lost)”
Reduce Task的内存使用。在某些情况下reduce task特别消耗内存,比如当shuffle出现的时候,比如sortByKey、groupByKey、reduceByKey和join等,要在内存 里面建立一个巨大的hash table。其中一个解决办法是增大level of parallelism,这样每个task的输入规模就相应减小。另外,注意shuffle的内存上限设置,有时候有足够的内存,但是shuffle内存 不够的话,性能也是上不去的。我们在有大量数据join等操作的时候,shuffle的内存上限经常配置到executor的50%。
注意原始input的大小,有很多操作始终都是需要某类全集数据在内存里面完成的,那么并非拼命增加parallelism和partition的 值就可以把内存占用减得非常小的。我们遇到过某些性能低下甚至OOM的问题,是改变这两个参数所难以缓解的。但是可以通过增加每台机器的内存,或者增加机 器的数量都可以直接或间接增加内存总量来解决。
在选择EC2机器类型的时候,要明确瓶颈(可以借由测试来明确),比如我们遇到的情况就是使用r3.8 xlarge和c3.8 xlarge选择的问题,运算能力相当,前者比后者贵50%,但是内存是后者的5倍。
另外,有一些RDD的API,比如cache,persist,都会把数据强制放到内存里面,如果并不明确这样做带来的好处,就不要用它们。
CPU
Level of Parallelism。指定它以后,在进行reduce类型操作的时候,默认partition的数量就被指定了。这个参数在实际工程中通常是必不可少的,一般都要根据input和每个executor内存的大小来确定。设置level of parallelism或者属性spark.default.parallelism来改变并行级别,通常来说,每一个CPU核可以分配2~3个task。
CPU core的访问模式是共享还是独占。即CPU核是被同一host上的executor共享还是瓜分并独占。比如,一台机器上共有32个CPU core的资源,同时部署了两个executor,总内存是50G,那么一种方式是配置spark.executor.cores为 16,spark.executor.memory为20G,这样由于内存的限制,这台机器上会部署两个executor,每个都使用20G内存,并且各 使用“独占”的16个CPU core资源;而在内存资源不变的前提下,也可以让这两个executor“共享”这32个core。根据我的测试,独占模式的性能要略好与共享模式。
GC调优。打印GC信息:-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps。要记得默认60%的executor内存可以被用来作为RDD的缓存,因此只有40%的内存可以被用来作为对象创建的空间, 这一点可以通过设置spark.storage.memoryFraction改变。如果有很多小对象创建,但是这些对象在不完全GC的过程中就可以回 收,那么增大Eden区会有一定帮助。如果有任务从HDFS拷贝数据,内存消耗有一个简单的估算公式——比如HDFS的block size是64MB,工作区内有4个task拷贝数据,而解压缩一个block要增大3倍大小,那么估算内存消耗就是:4*3*64MB。另外,工作中遇 到过这样的一个问题:GC默认情况下有一个限制,默认是GC时间不能超过2%的CPU时间,但是如果大量对象创建(在Spark里很容易出现,代码模式就 是一个RDD转下一个RDD),就会导致大量的GC时间,从而出现“OutOfMemoryError: GC overhead limit exceeded”,对于这个,可以通过设置-XX:-UseGCOverheadLimit关掉它。
序列化和传输
Data Serialization,默认使用的是Java Serialization,这个程序员最熟悉,但是性能、空间表现都比较差。还有一个选项是Kryo Serialization,更快,压缩率也更高,但是并非支持任意类的序列化。在Spark UI上能够看到序列化占用总时间开销的比例,如果这个比例高的话可以考虑优化内存使用和序列化。
Broadcasting Large Variables。在task使用静态大对象的时候,可以把它broadcast出去。Spark会打印序列化后的大小,通常来说如果它超过20KB就值得这么做。有一种常见情形是,一个大表join一个小表,把小表broadcast后,大表的数据就不需要在各个node之间疯跑,安安静静地呆在本地等小表broadcast过来就好了。
Data Locality。数据和代码要放到一起才能处理,通常代码总比数据要小一些,因此把代码送到各处会更快。Data Locality是数据和处理的代码在屋里空间上接近的程度:PROCESS_LOCAL(同一个JVM)、NODE_LOCAL(同一个node,比如 数据在HDFS上,但是和代码在同一个node)、NO_PREF、RACK_LOCAL(不在同一个server,但在同一个机架)、ANY。当然优先 级从高到低,但是如果在空闲的executor上面没有未处理数据了,那么就有两个选择:
- (1)要么等如今繁忙的CPU闲下来处理尽可能“本地”的数据,
- (2)要么就不等直接启动task去处理相对远程的数据。
-
默认当这种情况发生Spark会等一会儿(spark.locality),即策略(1),如果繁忙的CPU停不下来,就会执行策略(2)。
代码里对大对象的引用。在task里面引用大对象的时候要小心,因为它会随着task序列化到每个节点上去,引发性能问题。只要序列化的过程不抛出 异常,引用对象序列化的问题事实上很少被人重视。如果,这个大对象确实是需要的,那么就不如干脆把它变成RDD好了。绝大多数时候,对于大对象的序列化行 为,是不知不觉发生的,或者说是预期之外的,比如在我们的项目中有这样一段代码:
- rdd.map(r => {
- println(BackfillTypeIndex)
- })
-
其实呢,它等价于这样:
- rdd.map(r => {
- println(this.BackfillTypeIndex)
- })
-
不要小看了这个this,有时候它的序列化是非常大的开销。
对于这样的问题,一种最直接的解决方法就是:
- val dereferencedVariable = this.BackfillTypeIndex
- rdd.map(r => println(dereferencedVariable)) // "this" is not serialized
-
相关地,注解@transient用来标识某变量不要被序列化,这对于将大对象从序列化的陷阱中排除掉是很有用的。另外,注意class之间的继承层级关系,有时候一个小的case class可能来自一棵大树。
文件读写
文件存储和读取的优化。比如对于一些case而言,如果只需要某几列,使用rcfile和parquet这样的格式会大大减少文件读取成本。再有就 是存储文件到S3上或者HDFS上,可以根据情况选择更合适的格式,比如压缩率更高的格式。另外,特别是对于shuffle特别多的情况,考虑留下一定量 的额外内存给操作系统作为操作系统的buffer cache,比如总共50G的内存,JVM最多分配到40G多一点。
文件分片。比如在S3上面就支持文件以分片形式存放,后缀是partXX。使用coalesce方法来设置分成多少片,这个调整成并行级别或者其整 数倍可以提高读写性能。但是太高太低都不好,太低了没法充分利用S3并行读写的能力,太高了则是小文件太多,预处理、合并、连接建立等等都是时间开销啊, 读写还容易超过throttle。
任务
Spark的Speculation。通过设置spark.speculation等几个相关选项,可以让Spark在发现某些task执行特别慢的时候,可以在不等待完成的情况下被重新执行,最后相同的task只要有一个执行完了,那么最快执行完的那个结果就会被采纳。
减少Shuffle。其实Spark的计算往往很快,但是大量开销都花在网络和IO上面,而shuffle就是一个典型。举个例子,如果(k, v1) join (k, v2) => (k, v3),那么,这种情况其实Spark是优化得非常好的,因为需要join的都在一个node的一个partition里面,join很快完成,结果也是 在同一个node(这一系列操作可以被放在同一个stage里面)。但是如果数据结构被设计为(obj1) join (obj2) => (obj3),而其中的join条件为obj1.column1 == obj2.column1,这个时候往往就被迫shuffle了,因为不再有同一个key使得数据在同一个node上的强保证。在一定要shuffle的情况下,尽可能减少shuffle前的数据规模,比如这个避免groupByKey的例子。下面这个比较的图片来自Spark Summit 2013的一个演讲,讲的是同一件事情:

Repartition。运算过程中数据量时大时小,选择合适的partition数量关系重大,如果太多partition就导致有很多小任务和空任务产生;如果太少则导致运算资源没法充分利用,必要时候可以使用repartition来调整,不过它也不是没有代价的,其中一个最主要代价就是shuffle。 再有一个常见问题是数据大小差异太大,这种情况主要是数据的partition的key其实取值并不均匀造成的(默认使用 HashPartitioner),需要改进这一点,比如重写hash算法。测试的时候想知道partition的数量可以调用 rdd.partitions().size()获知。
Task时间分布。关注Spark UI,在Stage的详情页面上,可以看得到shuffle写的总开销,GC时间,当前方法栈,还有task的时间花费。如果你发现task的时间花费分 布太散,就是说有的花费时间很长,有的很短,这就说明计算分布不均,需要重新审视数据分片、key的hash、task内部的计算逻辑等等,瓶颈出现在耗 时长的task上面。

重用资源。有的资源申请开销巨大,而且往往相当有限,比如建立连接,可以考虑在partition建立的时候就创建好(比如使用mapPartition方法),这样对于每个partition内的每个元素的操作,就只要重用这个连接就好了,不需要重新建立连接。
可供参考的文档:官方调优文档Tuning Spark,Spark配置的官方文档,Spark Programming Guide,JVMGC调优文档,JVM性能调优文档,How-to: Tune Your Apache Spark Jobs part-1 & part-2。