大数据时代单表数据同步之SPARK实现(一)
背景
随着电子商务的发展,历史最终选择了三足鼎立的格局去稳定市场,产生了传统电子商务三强:阿里,京东,苏宁易购(阿里,京东日均PV早已是亿级别以上,苏宁易购日均PV也至少应该五千万级左右)。显然这些数据中蕴藏着无情无尽的财富,如何利用这些数据便是当下大数据开发工程师们首先需要解决的问题~既然有大数据,那必然会牵扯到集群数据的迁移,同步等类ETL工作。本文主要介绍博主最近一周实现的利用spark同步关系型数据库数据至HDFS,并实现配置化。
场景
电子商务网站对商品库存,价格等核心指标必然会采用分库分表的策略去存储,大体上都是通过itemcode取模进行存储。
例:
product是表头,十六进制0~f循环
配置文件设置
<table>
<name>productname>
<isAble>2isAble>
<partitions>15partitions>
<fileds>*fileds>
<relyOn>relyOn>
<datasources username="test"
passwd="test"
url="jdbc:mysql://test:3388/prodb01"
prefix="0,1,2,3"
suffix="0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f"
prdeicates="istate = 1"
driver="com.mysql.jdbc.Driver"/>
<datasources username="test"
passwd="test"
url="jdbc:mysql://test:3388/prodb02"
prefix="4,5,6,7"
suffix="0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f"
prdeicates="istate = 1"
driver="com.mysql.jdbc.Driver"/>
table>table:一个同步任务;name: 同步表名;isAble:是否同步;partitions:导出文件数;fileds:需要同步的字段,逗号相隔;relyOn:是否依赖配置表,例如A,B切换场景;datasources:数据源信息;prefix,suffix根据分库分表策略自行组合,可以动态扩展;prdeicates:分片策略,也能作为筛选条件;driver:数据库驱动类型,支持各种driver。
代码
根据上述XML格式组装java对象
Job类
private String name;
private String fields;
private int partitions;
private String isAble;
private String relyOn;
private List dataSourcesDOs; for(JobDO jobDO : jobs) {
try{
FileUtil.deleteOutputDir(DATA_OUTPUT + jobDO.getName());
DataFramedataFrame=null;
//初始化一个空rdd
JavaRDDrdd=sc.parallelize(new ArrayList());
for(DataSourcesDO dataSourcesDO : jobDO.getDataSourcesDOs()){
properties.setProperty("user", dataSourcesDO.getUserName());
properties.setProperty("password", dataSourcesDO.getPassWord());
properties.setProperty("driver", dataSourcesDO.getDriver());
for(StringtableName:dataSourcesDO.getTableNames()) {
if (StringUtils.isNotBlank(jobDO.getRelyOn())) {
JavaRDDrelyOnRDD=sc.textFile(DATA_OUTPUT+jobDO.getRelyOn()+ "/data").map
(new Function(){
@Override
public Stringcall(Stringv1)throws Exception {
return v1.substring(0, v1.indexOf(PattenUtil.PARTTEN));
}
});
List status=sc.broadcast(relyOnRDD.collect()).value();
if(!CheckUtil.checkListIsNull(status)){
tableName=tableName+"_"+status.get(0);
}
}
//数据库查询
dataFrame=sqlContext.read().jdbc(dataSourcesDO.getUrl(), tableName,
dataSourcesDO.getPrdeicates(), properties);
dataFrame.registerTempTable(tableName);
if (!"*".equals(jobDO.getFields())){
dataFrame=sqlContext.sql("select " + jobDO.getFields().toUpperCase() + " from"+tableName);
}
JavaRDDmap=dataFrame.toJavaRDD().map(newFunction(){
privatestatic final longserialVersionUID = 1L;
@Override
public Stringcall(Row v1) throwsException{
StringBuildersb = new StringBuilder();
//业务逻辑
for(int i = 0;i
sb.append(v1.apply(i)).append(PattenUtil.PARTTEN);
}
if (sb.length()>0) {
sb = sb.delete(sb.length() - PattenUtil.PARTTEN.length(),sb.length());
}
return sb.toString();
}
});
if (1== dataSourcesDO.getTableNames().length) {
rdd=map;
}else {
rdd=rdd.union(map);
}
}
}
// System.out.println(rdd.count());
if (jobDO.getPartitions()>0) {
rdd=rdd.repartition(jobDO.getPartitions());
}
rdd.saveAsTextFile(DATA_OUTPUT + jobDO.getName() + "/data");
FileUtil.createFile(DATA_OUTPUT+jobDO.getName()+"/schema", SchemaUtil.createSchema(dataFrame)); 可以通过配置fileds字段,动态获取。prdeicates是个String数组,数组的length决定了spark读数据库的线程数。如果单表过大建议根据数据指定分区规则,如果实在没有啥分区规则,也不用怕,博主有个土鳖的方法:
prdeicates="1 = 1,1 = 1,1 = 1,1 = 1,1 = 1,1 = 1,1 = 1"此处详细介绍可以参考spark官网,不在此累赘原理性的知识。
输出
导出文件格式

文件名为上述XML文件中的name字段,内部结构包括data,schema。其中data是具体数据,schema文件是每行数据的含义,字段名称,数据结构等数据库基本信息
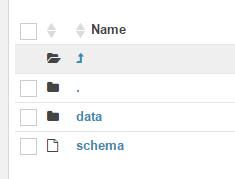
dataFrame提供了schema的获取方法,如果需要自定义输出schema的格式可以重新此方法,博主这边进行了简单的重写:
StructType schema = dataFrame.schema();
StringBuilder sb = new StringBuilder();
sb.append("read me: split by \\001").append(LINE_FEED);
//sb.append("index name dataType nullAble ").append(LINE_FEED).append(LINE_FEED);
sb.append("root").append(LINE_FEED);
for (int i = 0; i < schema.size(); i++) {
sb.append("|--" + BLANK + i + BLANK + schema.apply(i).name().toLowerCase() + ":" + BLANK + schema.apply(i).dataType()+ BLANK + "(nullable =" + BLANK + schema.apply(i).nullable() + ")" + LINE_FEED);
}
return sb.toString();输出文件格式为:
read me: split by \001
root
|-- 0 ts: DateType (nullable = true)
|-- 1 pztyz: StringType (nullable = false)
|-- 2 ant: StringType (nullable = false)至此已经完成了整个数据同步的实现过程,支持分布式,支持配置,支持自定义输出格式。
遇到的问题
上述有提到A,B策略的问题,博主在工程化的过程中遇到商品销量表采用的A,B表策略,通过一张配置表来决定是读写A或者B表。当该表数据比较大时,可以通过设置prdeicates来动态增加SPARK读写的线程数,默认是1。但是这个值也不是设置的越大越好,这还取决于DB的承载能力。
总结
博主这边只是实现了简单的数据同步工作,能满足日常工作中90%的需求,然而实际生产生活中存在多张表数据关联查询等业务场景,读者们可以在博主上述代码的设计思想上进行适当的修改已期能满足你们的需求,想法有多大天空就有多大。传统付费ETL工具,你们有没有在颤抖,博主只关心你家还缺经纪人么?~~~