Graphx源码解析之SVD++算法
Spark Graphx中SVD++算法主要是参考论文:
http://public.research.att.com/~volinsky/netflix/kdd08koren.pdf,
核心计算公式为:rui = u + bu + bi + qi*(pu + |N(u)|^^-0.5^^*sum(y))
输入
输入:user,item,score
1,1,5.0
1,2,1.0
1,3,5.0
1,4,1.0
2,1,5.0
2,2,1.0
2,3,5.0
2,4,1.0
3,1,1.0
3,2,5.0
3,3,1.0
3,4,5.0
4,1,1.0
4,2,5.0
4,3,1.0
4,4,5.0根据需要,图主要分为有向图与无向图两种。由于起点与终点代表着不同的含义,选择有向图作为研究的主体。为了便于区分起点与终点,在数据录入之前起点ID乘2,终点ID乘2加1
Edge(uid.toString.toLong * 2, live_uid.toString.toLong * 2 + 1,score.toString.toDouble)参数
class Conf(
var rank: Int,//向量维数
var maxIters: Int,//迭代次数
var minVal: Double,//最小值
var maxVal: Double,//最大值
var gamma1: Double,//衰减系数
var gamma2: Double,//衰减系数
var gamma6: Double,//衰减系数
var gamma7: Double)//衰减系数
extends Serializable算法输入 输出
run(edges: RDD[Edge[Double]], conf: Conf)
: (Graph[(Array[Double], Array[Double], Double, Double), Double], Double)计算平均评分
//rs 评分之和
//rc 记录总数
val (rs, rc) = edges.map(e => (e.attr, 1L)).reduce((a, b) => (a._1 + b._1, a._2 + b._2))
//平均评分
val u = rs / rc组成图
Graph.fromEdges(edges, defaultF(conf.rank)).cache()defaultF根据rank值随机生成feature向量,看下defaultF方法
def defaultF(rank: Int): (Array[Double], Array[Double], Double, Double) = {
// TODO: use a fixed random seed
val v1 = Array.fill(rank)(Random.nextDouble())
val v2 = Array.fill(rank)(Random.nextDouble())
(v1, v2, 0.0, 0.0)
}计算SUM和根号值
//顶点 顶点出现的次数 评分总和
val t0: VertexRDD[(VertexId, Double)] = g.aggregateMessages[(VertexId, Double)](ctx => {
ctx.sendToSrc((1L, ctx.attr));
ctx.sendToDst((1L, ctx.attr))
}, (g1, g2) => (g1._1 + g2._1, g1._2 + g2._2))
// t0.foreach(println(_))
// 总评分除以总次数减去平均评分 1 / 总次数的开根号
val gJoinT0 = g.outerJoinVertices(t0) {
(vid: VertexId, vd: (Array[Double], Array[Double], Double, Double),
msg: Option[(Long, Double)]) =>
// println(msg.get._2 + " " + msg.get._1)
(vd._1, vd._2, msg.get._2 / msg.get._1 - u, 1.0 / scala.math.sqrt(msg.get._1))
}.cache()此时的输出结果为g:
id p q bu/bi |N(u)|^^-0.5
(4,([D@7ed9bdff,[D@15188d22,0.0,0.5))
(6,([D@7ed9bdff,[D@15188d22,0.0,0.5))
(3,([D@7ed9bdff,[D@15188d22,0.0,0.5))
(7,([D@7ed9bdff,[D@15188d22,0.0,0.5))
(9,([D@7ed9bdff,[D@15188d22,0.0,0.5))
(8,([D@7ed9bdff,[D@15188d22,0.0,0.5))
(5,([D@7ed9bdff,[D@15188d22,0.0,0.5))
(2,([D@7ed9bdff,[D@15188d22,0.0,0.5))将g作为输入,进行迭代
第一步
所有起点的第二个数组根据起点求MR并合并到g中
//起始点 相加 次数 起始点个数 第二个数组
val t1 = g.aggregateMessages[Array[Double]](
ctx => {
// println(ctx);
ctx.sendToSrc(ctx.dstAttr._2)
},
(g1, g2) => {
// println(g1.toList)
// println(g2.toList)
val out = g1.clone()
blas.daxpy(out.length, 1.0, g2, 1, out, 1)
out
})
// t1.foreach(x => println(x._1 + " " + x._2.toList))
val gJoinT1 = g.outerJoinVertices(t1) {
(vid: VertexId, vd: (Array[Double], Array[Double], Double, Double),
msg: Option[Array[Double]]) =>
if (msg.isDefined) {
val out = vd._1.clone()
blas.daxpy(out.length, vd._4, msg.get, 1, out, 1)
(vd._1, out, vd._3, vd._4)
} else {
vd
}
}.cache()注意:blas.daxpy 是矩阵相加,由第三方jar提供
第二步
// Phase 2, update p for user nodes and q, y for item nodes
g.cache()
val t2 = g.aggregateMessages(
sendMsgTrainF(conf, u),
(g1: (Array[Double], Array[Double], Double), g2: (Array[Double], Array[Double], Double)) => {
val out1 = g1._1.clone()
blas.daxpy(out1.length, 1.0, g2._1, 1, out1, 1)
val out2 = g2._2.clone()
blas.daxpy(out2.length, 1.0, g2._2, 1, out2, 1)
(out1, out2, g1._3 + g2._3)
})
// t2.foreach(x => println(x))
val gJoinT2 = g.outerJoinVertices(t2) {
(vid: VertexId,
vd: (Array[Double], Array[Double], Double, Double),
msg: Option[(Array[Double], Array[Double], Double)]) => {
val out1 = vd._1.clone()
blas.daxpy(out1.length, 1.0, msg.get._1, 1, out1, 1)
val out2 = vd._2.clone()
blas.daxpy(out2.length, 1.0, msg.get._2, 1, out2, 1)
(out1, out2, vd._3 + msg.get._3, vd._4)
}
}.cache()重点介绍sendMsgTrainF
def sendMsgTrainF(conf: Conf, u: Double)
(ctx: EdgeContext[
(Array[Double], Array[Double], Double, Double),
Double,
(Array[Double], Array[Double], Double)]) {
val (usr, itm) = (ctx.srcAttr, ctx.dstAttr)
println(usr._3 + " " + usr._4)
val (p, q) = (usr._1, itm._1)
val rank = p.length
var pred = u + usr._3 + itm._3 + blas.ddot(rank, q, 1, usr._2, 1)
// println("srcId: " + ctx.srcId + " dstId: " + ctx.dstId + " attr: " + ctx.attr + " pred: " + pred + " error: " + (ctx.attr - pred))
// println("sendMsgTrainF pred " + pred)
pred = math.max(pred, conf.minVal)
pred = math.min(pred, conf.maxVal)
val err = ctx.attr - pred
// println("sendMsgTrainF err " + err)
// updateP = (err * q - conf.gamma7 * p) * conf.gamma2
val updateP = q.clone()
blas.dscal(rank, err * conf.gamma2, updateP, 1)
blas.daxpy(rank, -conf.gamma7 * conf.gamma2, p, 1, updateP, 1)
// updateQ = (err * usr._2 - conf.gamma7 * q) * conf.gamma2
val updateQ = usr._2.clone()
// println("begin srcId: " + ctx.srcId + " dstId: " + ctx.dstId + " " + updateQ.toList)
blas.dscal(rank, err * conf.gamma2, updateQ, 1)
// println("dscal: " + updateQ.toList + " " + err * conf.gamma2)
blas.daxpy(rank, -conf.gamma7 * conf.gamma2, q, 1, updateQ, 1)
// println("daxpy: " + updateQ.toList + " " + (-conf.gamma7 * conf.gamma2))
// updateY = (err * usr._4 * q - conf.gamma7 * itm._2) * conf.gamma2
val updateY = q.clone()
blas.dscal(rank, err * usr._4 * conf.gamma2, updateY, 1)
blas.daxpy(rank, -conf.gamma7 * conf.gamma2, itm._2, 1, updateY, 1)
ctx.sendToSrc((updateP, updateY, (err - conf.gamma6 * usr._3) * conf.gamma1))
ctx.sendToDst((updateQ, updateY, (err - conf.gamma6 * itm._3) * conf.gamma1))
}pred为迭代一次的评分,err为误差。
updateP = (err * q - conf.gamma7 * p) * conf.gamma2
updateQ = (err * usr._2 - conf.gamma7 * q) * conf.gamma2
updateY = (err * usr._4 * q - conf.gamma7 * itm._2) * conf.gamma2
起点修改为(updateP, updateY, score)
终点修改为(updateQ, updateY, score)
然后分布将解决更新到g中对应顶点的前三个位置。
可以很明显的发现这里才有的是每个顶点下降最后sum随机梯度下降的方式迭代。
M
1.per = u + user.3 + item.3 + item1*user2
2.per 最大最小闭区间 [min, max] 范围约束
3.误差 err = 真实评分 - per
4.user
(err * gamma2 * item1 - gamma7 * gamma2 * user1,
err * user4 * gamma2 * item1 - gamma7 * gamma2 * item2, (err - gamma6 * user3) * gamma1)
item
(err * gamma2 * user2 - gamma7 * gamma2 * user1,
err * user4 * gamma2 * item1 - gamma7 * gamma2 * item2, (err - gamma6 * item3) * gamma1)循环上述迭代过程
评测
val t3 = g.aggregateMessages[Double](sendMsgTestF(conf, u), _ + _)
val gJoinT3 = g.outerJoinVertices(t3) {
(vid: VertexId, vd: (Array[Double], Array[Double], Double, Double), msg: Option[Double]) =>
if (msg.isDefined) (vd._1, vd._2, vd._3, msg.get) else vd
}.cache()第三步
获取err
val t3 = gJoinT2.aggregateMessages[Double](sendMsgTestF(conf, u), _ + _)
val gJoinT3 = gJoinT2.outerJoinVertices(t3) {
(vid: VertexId, vd: (Array[Double], Array[Double], Double, Double), msg: Option[Double]) =>
if (msg.isDefined) (vd._1, vd._2, vd._3, msg.get) else vd
}.cache()
val err = gJoinT3.vertices.map { case (vid, vd) =>
if (vid % 2 == 1) vd._4 else 0.0
}.reduce(_ + _) / gJoinT3.numEdges
RedisUtil.setIntoRedis(i + "_ERR", err.toString)如果发现每次迭代过程中err的值出现波动,则可以将gamma1,gamma2调小,再次进行迭代试验。err走向图如下:
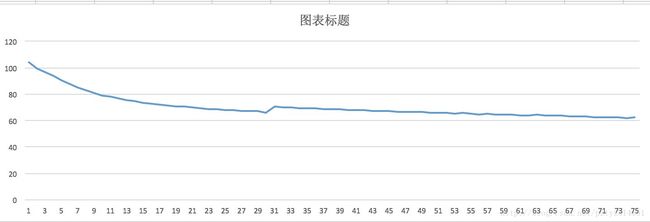
user中的user1为隐性feature,item中的item1为隐性feature。
结果输出
val labels = g.triplets.map { ctx =>
val (usr, itm) = (ctx.srcAttr, ctx.dstAttr)
val (p, q) = (usr._1, itm._1)
var pred = u + usr._3 + itm._3 + blas.ddot(q.length, q, 1, usr._2, 1)
pred = math.max(pred, conf.minVal)
pred = math.min(pred, conf.maxVal)
val err = (ctx.attr - pred)
}
(ctx.srcId / 2) + "|" + (ctx.dstId - 1) / 2 + "|" + pred
}.saveAsTextFile("/spark/grxpah/svd")后面可以进行类AUC之类的效果评测